 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTest-time Cost-and-Quality Controllable Arbitrary-Scale Super-Resolution with Variable Fourier Components
Dec 07, 2024



Super-resolution (SR) with arbitrary scale factor and cost-and-quality controllability at test time is essential for various applications. While several arbitrary-scale SR methods have been proposed, these methods require us to modify the model structure and retrain it to control the computational cost and SR quality. To address this limitation, we propose a novel SR method using a Recurrent Neural Network (RNN) with the Fourier representation. In our method, the RNN sequentially estimates Fourier components, each consisting of frequency and amplitude, and aggregates these components to reconstruct an SR image. Since the RNN can adjust the number of recurrences at test time, we can control the computational cost and SR quality in a single model: fewer recurrences (i.e., fewer Fourier components) lead to lower cost but lower quality, while more recurrences (i.e., more Fourier components) lead to better quality but more cost. Experimental results prove that more Fourier components improve the PSNR score. Furthermore, even with fewer Fourier components, our method achieves a lower PSNR drop than other state-of-the-art arbitrary-scale SR methods.
Burst Super-Resolution with Diffusion Models for Improving Perceptual Quality
Apr 08, 2024



While burst LR images are useful for improving the SR image quality compared with a single LR image, prior SR networks accepting the burst LR images are trained in a deterministic manner, which is known to produce a blurry SR image. In addition, it is difficult to perfectly align the burst LR images, making the SR image more blurry. Since such blurry images are perceptually degraded, we aim to reconstruct the sharp high-fidelity boundaries. Such high-fidelity images can be reconstructed by diffusion models. However, prior SR methods using the diffusion model are not properly optimized for the burst SR task. Specifically, the reverse process starting from a random sample is not optimized for image enhancement and restoration methods, including burst SR. In our proposed method, on the other hand, burst LR features are used to reconstruct the initial burst SR image that is fed into an intermediate step in the diffusion model. This reverse process from the intermediate step 1) skips diffusion steps for reconstructing the global structure of the image and 2) focuses on steps for refining detailed textures. Our experimental results demonstrate that our method can improve the scores of the perceptual quality metrics. Code: https://github.com/placerkyo/BSRD
Kernelized Back-Projection Networks for Blind Super Resolution
Feb 17, 2023



Since non-blind Super Resolution (SR) fails to super-resolve Low-Resolution (LR) images degraded by arbitrary degradations, SR with the degradation model is required. However, this paper reveals that non-blind SR that is trained simply with various blur kernels exhibits comparable performance as those with the degradation model for blind SR. This result motivates us to revisit high-performance non-blind SR and extend it to blind SR with blur kernels. This paper proposes two SR networks by integrating kernel estimation and SR branches in an iterative end-to-end manner. In the first model, which is called the Kernel Conditioned Back-Projection Network (KCBPN), the low-dimensional kernel representations are estimated for conditioning the SR branch. In our second model, the Kernelized BackProjection Network (KBPN), a raw kernel is estimated and directly employed for modeling the image degradation. The estimated kernel is employed not only for back-propagating its residual but also for forward-propagating the residual to iterative stages. This forward-propagation encourages these stages to learn a variety of different features in different stages by focusing on pixels with large residuals in each stage. Experimental results validate the effectiveness of our proposed networks for kernel estimation and SR. We will release the code for this work.
NTIRE 2021 Challenge on Burst Super-Resolution: Methods and Results
Jun 07, 2021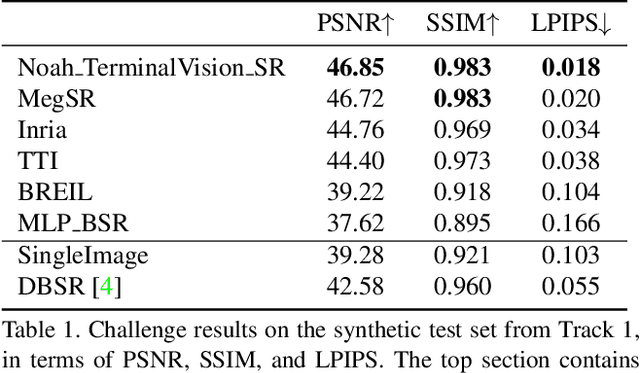

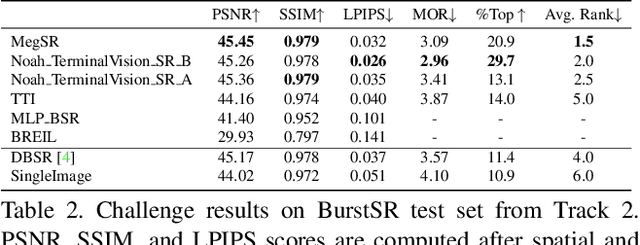

This paper reviews the NTIRE2021 challenge on burst super-resolution. Given a RAW noisy burst as input, the task in the challenge was to generate a clean RGB image with 4 times higher resolution. The challenge contained two tracks; Track 1 evaluating on synthetically generated data, and Track 2 using real-world bursts from mobile camera. In the final testing phase, 6 teams submitted results using a diverse set of solutions. The top-performing methods set a new state-of-the-art for the burst super-resolution task.
AIM 2020 Challenge on Video Extreme Super-Resolution: Methods and Results
Sep 14, 2020This paper reviews the video extreme super-resolution challenge associated with the AIM 2020 workshop at ECCV 2020. Common scaling factors for learned video super-resolution (VSR) do not go beyond factor 4. Missing information can be restored well in this region, especially in HR videos, where the high-frequency content mostly consists of texture details. The task in this challenge is to upscale videos with an extreme factor of 16, which results in more serious degradations that also affect the structural integrity of the videos. A single pixel in the low-resolution (LR) domain corresponds to 256 pixels in the high-resolution (HR) domain. Due to this massive information loss, it is hard to accurately restore the missing information. Track 1 is set up to gauge the state-of-the-art for such a demanding task, where fidelity to the ground truth is measured by PSNR and SSIM. Perceptually higher quality can be achieved in trade-off for fidelity by generating plausible high-frequency content. Track 2 therefore aims at generating visually pleasing results, which are ranked according to human perception, evaluated by a user study. In contrast to single image super-resolution (SISR), VSR can benefit from additional information in the temporal domain. However, this also imposes an additional requirement, as the generated frames need to be consistent along time.
Image Super-Resolution using Explicit Perceptual Loss
Sep 01, 2020
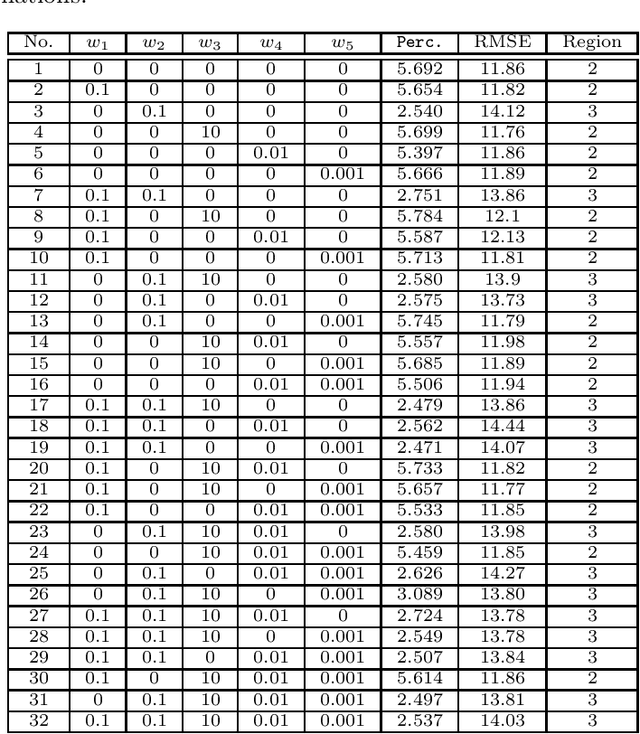
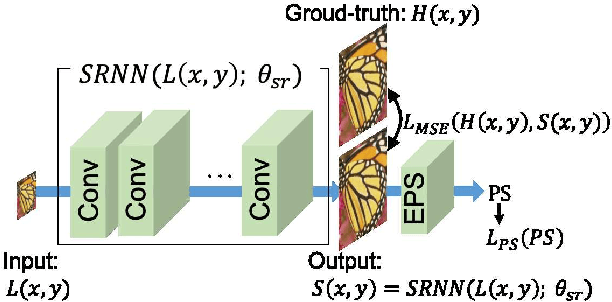

This paper proposes an explicit way to optimize the super-resolution network for generating visually pleasing images. The previous approaches use several loss functions which is hard to interpret and has the implicit relationships to improve the perceptual score. We show how to exploit the machine learning based model which is directly trained to provide the perceptual score on generated images. It is believed that these models can be used to optimizes the super-resolution network which is easier to interpret. We further analyze the characteristic of the existing loss and our proposed explicit perceptual loss for better interpretation. The experimental results show the explicit approach has a higher perceptual score than other approaches. Finally, we demonstrate the relation of explicit perceptual loss and visually pleasing images using subjective evaluation.
NTIRE 2020 Challenge on Perceptual Extreme Super-Resolution: Methods and Results
May 03, 2020
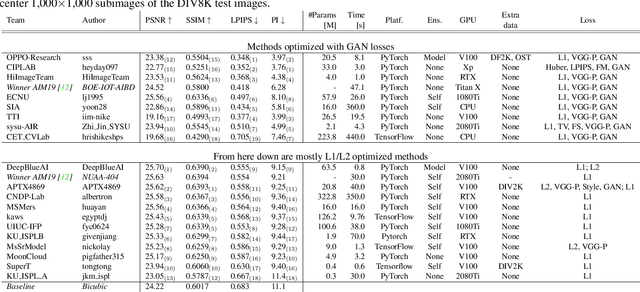

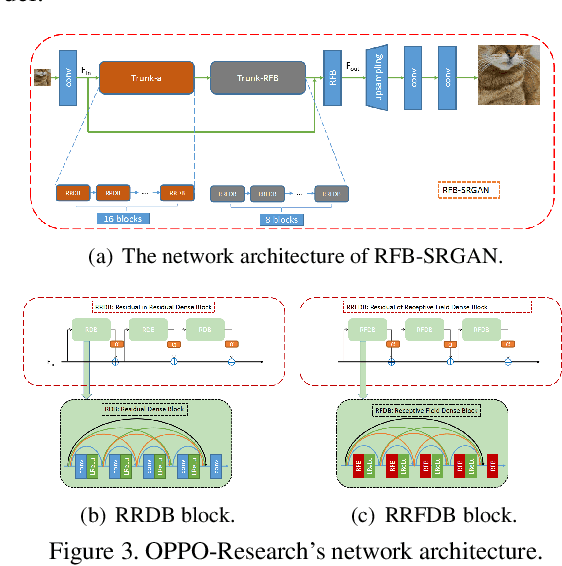
This paper reviews the NTIRE 2020 challenge on perceptual extreme super-resolution with focus on proposed solutions and results. The challenge task was to super-resolve an input image with a magnification factor 16 based on a set of prior examples of low and corresponding high resolution images. The goal is to obtain a network design capable to produce high resolution results with the best perceptual quality and similar to the ground truth. The track had 280 registered participants, and 19 teams submitted the final results. They gauge the state-of-the-art in single image super-resolution.