 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOctaOctree Neural Radiosity for Real-time Glossy Material Rendering
Jun 07, 2026Modeling high-frequency outgoing radiance distributions remains a fundamental challenge in global illumination, especially for glossy and specular materials. Existing neural-based radiance caching methods commonly rely on positional feature encodings or spatially organized caches, which makes it difficult to represent sharp directional radiance variations without increasing the model complexity or sampling cost. To address this challenge, we propose OctaOctree, an efficient spatial-angular radiance representation for global illumination. OctaOctree organizes outgoing radiance with an adaptive octree in 3D space, and associates each spatial node with an octahedral directional map. By coupling the spatial hierarchy with direction-dependent storage, our representation allocates fine spatial resolution to local illumination and visibility changes, while using coarser spatial levels with richer angular resolution to capture glossy and specular radiance distributions. This design embeds a reflectance-aware spatial-angular prior directly into the radiance representation, reducing the burden on neural networks or reconstruction modules to recover high-frequency view-dependent effects from positional features alone. As a result, OctaOctree provides a compact and expressive neural encoding for a wide range of indirect illumination effects, from diffuse interreflection to sharp glossy reflections. Experiments demonstrate that our method produces high-quality, direction-aware global illumination with single network query at primary intersections, achieving improved fidelity and real-time performance compared with baseline neural radiosity and radiance caching approaches.
Global River Forecasting with a Topology-Informed AI Foundation Model
Feb 25, 2026River systems operate as inherently interconnected continuous networks, meaning river hydrodynamic simulation ought to be a systemic process. However, widespread hydrology data scarcity often restricts data-driven forecasting to isolated predictions. To achieve systemic simulation and reduce reliance on river observations, we present GraphRiverCast (GRC), a topology-informed AI foundation model designed to simulate multivariate river hydrodynamics in global river systems. GRC is capable of operating in a "ColdStart" mode, generating predictions without relying on historical river states for initialization. In 7-day global pseudo-hindcasts, GRC-ColdStart functions as a robust standalone simulator, achieving a Nash-Sutcliffe Efficiency (NSE) of approximately 0.82 without exhibiting the significant error accumulation typical of autoregressive paradigms. Ablation studies reveal that topological encoding serves as indispensable structural information in the absence of historical states, explicitly guiding hydraulic connectivity and network-scale mass redistribution to reconstruct flow dynamics. Furthermore, when adapted locally via a pre-training and fine-tuning strategy, GRC consistently outperforms physics-based and locally-trained AI baselines. Crucially, this superiority extends from gauged reaches to full river networks, underscoring the necessity of topology encoding and physics-based pre-training. Built on a physics-aligned neural operator architecture, GRC enables rapid and cross-scale adaptive simulation, establishing a collaborative paradigm bridging global hydrodynamic knowledge with local hydrological reality.
Inference-Time Rethinking with Latent Thought Vectors for Math Reasoning
Feb 06, 2026Standard chain-of-thought reasoning generates a solution in a single forward pass, committing irrevocably to each token and lacking a mechanism to recover from early errors. We introduce Inference-Time Rethinking, a generative framework that enables iterative self-correction by decoupling declarative latent thought vectors from procedural generation. We factorize reasoning into a continuous latent thought vector (what to reason about) and a decoder that verbalizes the trace conditioned on this vector (how to reason). Beyond serving as a declarative buffer, latent thought vectors compress the reasoning structure into a continuous representation that abstracts away surface-level token variability, making gradient-based optimization over reasoning strategies well-posed. Our prior model maps unstructured noise to a learned manifold of valid reasoning patterns, and at test time we employ a Gibbs-style procedure that alternates between generating a candidate trace and optimizing the latent vector to better explain that trace, effectively navigating the latent manifold to refine the reasoning strategy. Training a 0.2B-parameter model from scratch on GSM8K, our method with 30 rethinking iterations surpasses baselines with 10 to 15 times more parameters, including a 3B counterpart. This result demonstrates that effective mathematical reasoning can emerge from sophisticated inference-time computation rather than solely from massive parameter counts.
Kimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
Electromagnetic Quantitative Inversion for Translationally Moving Targets via Phase Correlation Registration of Back-Projection Images
Nov 19, 2025A novel electromagnetic quantitative inversion scheme for translationally moving targets via phase correlation registration of back-projection (BP) images is proposed. Based on a time division multiplexing multiple-input multiple-output (TDM-MIMO) radar architecture, the scheme first achieves high-precision relative positioning of the target, then applies relative motion compensation to perform iterative inversion on multi-cycle MIMO measurement data, thereby reconstructing the target's electromagnetic parameters. As a general framework compatible with other mainstream inversion algorithms, we exemplify our approach by incorporating the classical cross-correlated contrast source inversion (CC-CSI) into iterative optimization step of the scheme, resulting in a new algorithm termed RMC-CC-CSI. Numerical and experimental results demonstrate that RMC-CC-CSI offers accelerated convergence, enhanced reconstruction fidelity, and improved noise immunity over conventional CC-CSI for stationary targets despite increased computational cost.
Seer: Online Context Learning for Fast Synchronous LLM Reinforcement Learning
Nov 18, 2025



Reinforcement Learning (RL) has become critical for advancing modern Large Language Models (LLMs), yet existing synchronous RL systems face severe performance bottlenecks. The rollout phase, which dominates end-to-end iteration time, suffers from substantial long-tail latency and poor resource utilization due to inherent workload imbalance. We present Seer, a novel online context learning system that addresses these challenges by exploiting previously overlooked similarities in output lengths and generation patterns among requests sharing the same prompt. Seer introduces three key techniques: divided rollout for dynamic load balancing, context-aware scheduling, and adaptive grouped speculative decoding. Together, these mechanisms substantially reduce long-tail latency and improve resource efficiency during rollout. Evaluations on production-grade RL workloads demonstrate that Seer improves end-to-end rollout throughput by 74% to 97% and reduces long-tail latency by 75% to 93% compared to state-of-the-art synchronous RL systems, significantly accelerating RL training iterations.
SSR: Socratic Self-Refine for Large Language Model Reasoning
Nov 13, 2025



Large Language Models (LLMs) have demonstrated remarkable reasoning abilities, yet existing test-time frameworks often rely on coarse self-verification and self-correction, limiting their effectiveness on complex tasks. In this paper, we propose Socratic Self-Refine (SSR), a novel framework for fine-grained evaluation and precise refinement of LLM reasoning. Our proposed SSR decomposes model responses into verifiable (sub-question, sub-answer) pairs, enabling step-level confidence estimation through controlled re-solving and self-consistency checks. By pinpointing unreliable steps and iteratively refining them, SSR produces more accurate and interpretable reasoning chains. Empirical results across five reasoning benchmarks and three LLMs show that SSR consistently outperforms state-of-the-art iterative self-refinement baselines. Beyond performance gains, SSR provides a principled black-box approach for evaluating and understanding the internal reasoning processes of LLMs. Code is available at https://github.com/SalesforceAIResearch/socratic-self-refine-reasoning.
Self-Abstraction from Grounded Experience for Plan-Guided Policy Refinement
Nov 08, 2025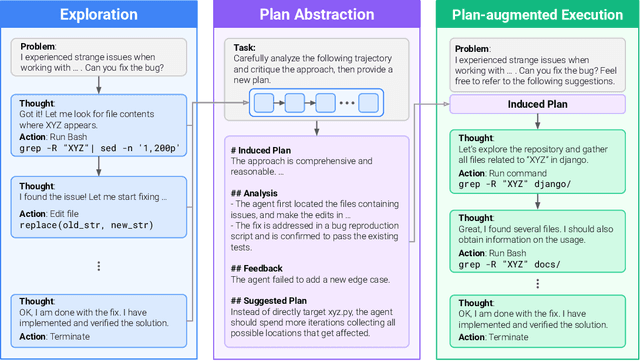

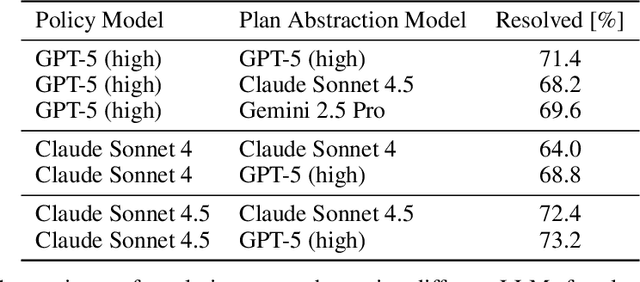
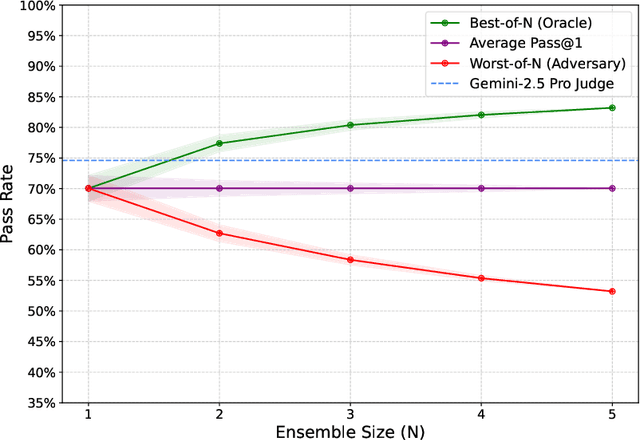
Large language model (LLM) based agents are increasingly used to tackle software engineering tasks that require multi-step reasoning and code modification, demonstrating promising yet limited performance. However, most existing LLM agents typically operate within static execution frameworks, lacking a principled mechanism to learn and self-improve from their own experience and past rollouts. As a result, their performance remains bounded by the initial framework design and the underlying LLM's capabilities. We propose Self-Abstraction from Grounded Experience (SAGE), a framework that enables agents to learn from their own task executions and refine their behavior through self-abstraction. After an initial rollout, the agent induces a concise plan abstraction from its grounded experience, distilling key steps, dependencies, and constraints. This learned abstraction is then fed back as contextual guidance, refining the agent's policy and supporting more structured, informed subsequent executions. Empirically, SAGE delivers consistent performance gains across diverse LLM backbones and agent architectures. Notably, it yields a 7.2% relative performance improvement over the strong Mini-SWE-Agent baseline when paired with the GPT-5 (high) backbone. SAGE further achieves strong overall performance on SWE-Bench Verified benchmark, reaching 73.2% and 74% Pass@1 resolve rates with the Mini-SWE-Agent and OpenHands CodeAct agent framework, respectively.
Reasoning Curriculum: Bootstrapping Broad LLM Reasoning from Math
Oct 30, 2025Reinforcement learning (RL) can elicit strong reasoning in large language models (LLMs), yet most open efforts focus on math and code. We propose Reasoning Curriculum, a simple two-stage curriculum that first elicits reasoning skills in pretraining-aligned domains such as math, then adapts and refines these skills across other domains via joint RL. Stage 1 performs a brief cold start and then math-only RL with verifiable rewards to develop reasoning skills. Stage 2 runs joint RL on mixed-domain data to transfer and consolidate these skills. The curriculum is minimal and backbone-agnostic, requiring no specialized reward models beyond standard verifiability checks. Evaluated on Qwen3-4B and Llama-3.1-8B over a multi-domain suite, reasoning curriculum yields consistent gains. Ablations and a cognitive-skill analysis indicate that both stages are necessary and that math-first elicitation increases cognitive behaviors important for solving complex problems. Reasoning Curriculum provides a compact, easy-to-adopt recipe for general reasoning.
Kimi Linear: An Expressive, Efficient Attention Architecture
Oct 30, 2025We introduce Kimi Linear, a hybrid linear attention architecture that, for the first time, outperforms full attention under fair comparisons across various scenarios -- including short-context, long-context, and reinforcement learning (RL) scaling regimes. At its core lies Kimi Delta Attention (KDA), an expressive linear attention module that extends Gated DeltaNet with a finer-grained gating mechanism, enabling more effective use of limited finite-state RNN memory. Our bespoke chunkwise algorithm achieves high hardware efficiency through a specialized variant of the Diagonal-Plus-Low-Rank (DPLR) transition matrices, which substantially reduces computation compared to the general DPLR formulation while remaining more consistent with the classical delta rule. We pretrain a Kimi Linear model with 3B activated parameters and 48B total parameters, based on a layerwise hybrid of KDA and Multi-Head Latent Attention (MLA). Our experiments show that with an identical training recipe, Kimi Linear outperforms full MLA with a sizeable margin across all evaluated tasks, while reducing KV cache usage by up to 75% and achieving up to 6 times decoding throughput for a 1M context. These results demonstrate that Kimi Linear can be a drop-in replacement for full attention architectures with superior performance and efficiency, including tasks with longer input and output lengths. To support further research, we open-source the KDA kernel and vLLM implementations, and release the pre-trained and instruction-tuned model checkpoints.