 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePointTrack++ for Effective Online Multi-Object Tracking and Segmentation
Paper and Code
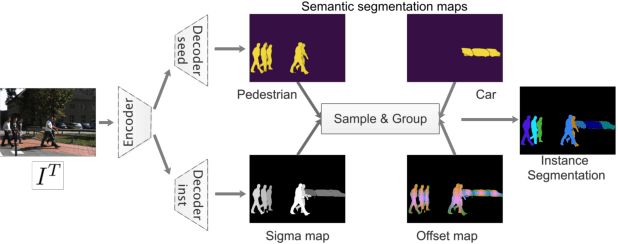
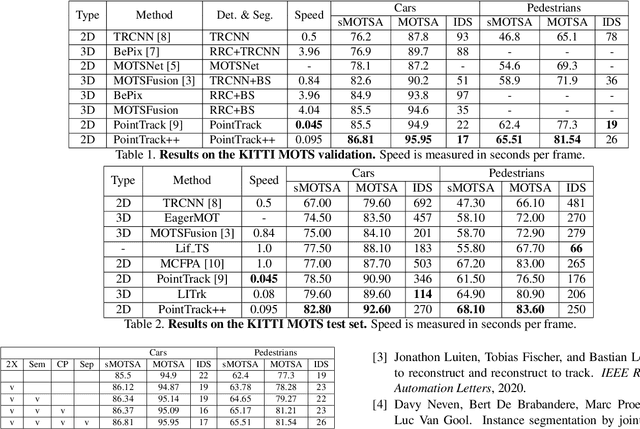
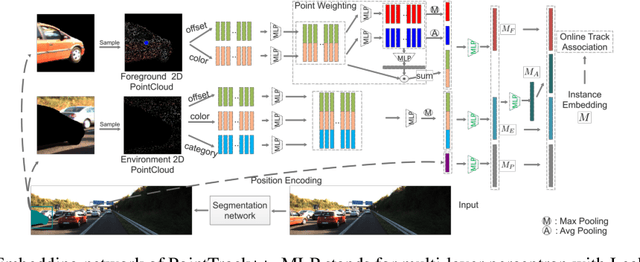
Multiple-object tracking and segmentation (MOTS) is a novel computer vision task that aims to jointly perform multiple object tracking (MOT) and instance segmentation. In this work, we present PointTrack++, an effective on-line framework for MOTS, which remarkably extends our recently proposed PointTrack framework. To begin with, PointTrack adopts an efficient one-stage framework for instance segmentation, and learns instance embeddings by converting compact image representations to un-ordered 2D point cloud. Compared with PointTrack, our proposed PointTrack++ offers three major improvements. Firstly, in the instance segmentation stage, we adopt a semantic segmentation decoder trained with focal loss to improve the instance selection quality. Secondly, to further boost the segmentation performance, we propose a data augmentation strategy by copy-and-paste instances into training images. Finally, we introduce a better training strategy in the instance association stage to improve the distinguishability of learned instance embeddings. The resulting framework achieves the state-of-the-art performance on the 5th BMTT MOTChallenge.