 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoRDS: Coreset-based Representative and Diverse Selection for Streaming Video Understanding
May 14, 2026Streaming video understanding with large vision-language models (VLMs) requires a compact memory that can support future reasoning over an ever-growing visual history. A common solution is to compress the key-value (KV) cache, but existing streaming methods typically rely on local token-wise heuristics, such as recency, temporal redundancy, or saliency, which do not explicitly optimize whether the retained cache is representative of the accumulated history. We propose to view KV-cache compression as a coreset selection problem: rather than scoring tokens independently for retention, we select a small subset that covers the geometry of the accumulated visual cache. Our method operates in a joint KV representation and introduces a bicriteria objective that balances coverage in key and value spaces, preserving both retrieval structure and output-relevant information. To encourage a more diverse retained subset, we further introduce an orthogonality-driven diversity criterion that favors candidates contributing new directions beyond the current selection, and connect this criterion to log-determinant subset selection. Across four open-source VLMs and five long-video and streaming-video benchmarks, our method improves over heuristic streaming compression baselines under a fixed cache budget. These results highlight that representative coreset selection offers a more effective principle, than token-wise pruning, for memory-constrained streaming video understanding.
Point transformer for protein structural heterogeneity analysis using CryoEM
Jan 26, 2026Structural dynamics of macromolecules is critical to their structural-function relationship. Cryogenic electron microscopy (CryoEM) provides snapshots of vitrified protein at different compositional and conformational states, and the structural heterogeneity of proteins can be characterized through computational analysis of the images. For protein systems with multiple degrees of freedom, it is still challenging to disentangle and interpret the different modes of dynamics. Here, by implementing Point Transformer, a self-attention network designed for point cloud analysis, we are able to improve the performance of heterogeneity analysis on CryoEM data, and characterize the dynamics of highly complex protein systems in a more human-interpretable way.
MOSS Transcribe Diarize: Accurate Transcription with Speaker Diarization
Jan 08, 2026Speaker-Attributed, Time-Stamped Transcription (SATS) aims to transcribe what is said and to precisely determine the timing of each speaker, which is particularly valuable for meeting transcription. Existing SATS systems rarely adopt an end-to-end formulation and are further constrained by limited context windows, weak long-range speaker memory, and the inability to output timestamps. To address these limitations, we present MOSS Transcribe Diarize, a unified multimodal large language model that jointly performs Speaker-Attributed, Time-Stamped Transcription in an end-to-end paradigm. Trained on extensive real wild data and equipped with a 128k context window for up to 90-minute inputs, MOSS Transcribe Diarize scales well and generalizes robustly. Across comprehensive evaluations, it outperforms state-of-the-art commercial systems on multiple public and in-house benchmarks.
Driver Assistant: Persuading Drivers to Adjust Secondary Tasks Using Large Language Models
Aug 07, 2025Level 3 automated driving systems allows drivers to engage in secondary tasks while diminishing their perception of risk. In the event of an emergency necessitating driver intervention, the system will alert the driver with a limited window for reaction and imposing a substantial cognitive burden. To address this challenge, this study employs a Large Language Model (LLM) to assist drivers in maintaining an appropriate attention on road conditions through a "humanized" persuasive advice. Our tool leverages the road conditions encountered by Level 3 systems as triggers, proactively steering driver behavior via both visual and auditory routes. Empirical study indicates that our tool is effective in sustaining driver attention with reduced cognitive load and coordinating secondary tasks with takeover behavior. Our work provides insights into the potential of using LLMs to support drivers during multi-task automated driving.
On the Effect of Negative Gradient in Group Relative Deep Reinforcement Optimization
May 24, 2025Reinforcement learning (RL) has become popular in enhancing the reasoning capabilities of large language models (LLMs), with Group Relative Policy Optimization (GRPO) emerging as a widely used algorithm in recent systems. Despite GRPO's widespread adoption, we identify a previously unrecognized phenomenon we term Lazy Likelihood Displacement (LLD), wherein the likelihood of correct responses marginally increases or even decreases during training. This behavior mirrors a recently discovered misalignment issue in Direct Preference Optimization (DPO), attributed to the influence of negative gradients. We provide a theoretical analysis of GRPO's learning dynamic, identifying the source of LLD as the naive penalization of all tokens in incorrect responses with the same strength. To address this, we develop a method called NTHR, which downweights penalties on tokens contributing to the LLD. Unlike prior DPO-based approaches, NTHR takes advantage of GRPO's group-based structure, using correct responses as anchors to identify influential tokens. Experiments on math reasoning benchmarks demonstrate that NTHR effectively mitigates LLD, yielding consistent performance gains across models ranging from 0.5B to 3B parameters.
Leveraging Online Olympiad-Level Math Problems for LLMs Training and Contamination-Resistant Evaluation
Jan 24, 2025Advances in Large Language Models (LLMs) have sparked interest in their ability to solve Olympiad-level math problems. However, the training and evaluation of these models are constrained by the limited size and quality of available datasets, as creating large-scale data for such advanced problems requires extensive effort from human experts. In addition, current benchmarks are prone to contamination, leading to unreliable evaluations. In this paper, we present an automated pipeline that leverages the rich resources of the Art of Problem Solving (AoPS) forum, which predominantly features Olympiad-level problems and community-driven solutions. Using open-source LLMs, we develop a method to extract question-answer pairs from the forum, resulting in AoPS-Instruct, a dataset of more than 600,000 high-quality QA pairs. Our experiments demonstrate that fine-tuning LLMs on AoPS-Instruct improves their reasoning abilities across various benchmarks. Moreover, we build an automatic pipeline that introduces LiveAoPSBench, an evolving evaluation set with timestamps, derived from the latest forum data, providing a contamination-resistant benchmark for assessing LLM performance. Notably, we observe a significant decline in LLM performance over time, suggesting their success on older examples may stem from pre-training exposure rather than true reasoning ability. Our work presents a scalable approach to creating and maintaining large-scale, high-quality datasets for advanced math reasoning, offering valuable insights into the capabilities and limitations of LLMs in this domain. Our benchmark and code is available at https://github.com/DSL-Lab/aops
GraphPNAS: Learning Distribution of Good Neural Architectures via Deep Graph Generative Models
Nov 28, 2022



Neural architectures can be naturally viewed as computational graphs. Motivated by this perspective, we, in this paper, study neural architecture search (NAS) through the lens of learning random graph models. In contrast to existing NAS methods which largely focus on searching for a single best architecture, i.e, point estimation, we propose GraphPNAS a deep graph generative model that learns a distribution of well-performing architectures. Relying on graph neural networks (GNNs), our GraphPNAS can better capture topologies of good neural architectures and relations between operators therein. Moreover, our graph generator leads to a learnable probabilistic search method that is more flexible and efficient than the commonly used RNN generator and random search methods. Finally, we learn our generator via an efficient reinforcement learning formulation for NAS. To assess the effectiveness of our GraphPNAS, we conduct extensive experiments on three search spaces, including the challenging RandWire on TinyImageNet, ENAS on CIFAR10, and NAS-Bench-101/201. The complexity of RandWire is significantly larger than other search spaces in the literature. We show that our proposed graph generator consistently outperforms RNN-based one and achieves better or comparable performances than state-of-the-art NAS methods.
Referring Transformer: A One-step Approach to Multi-task Visual Grounding
Jun 06, 2021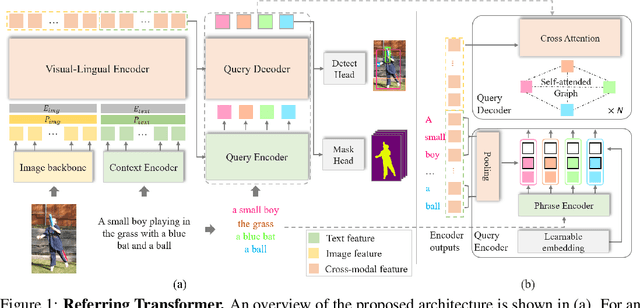
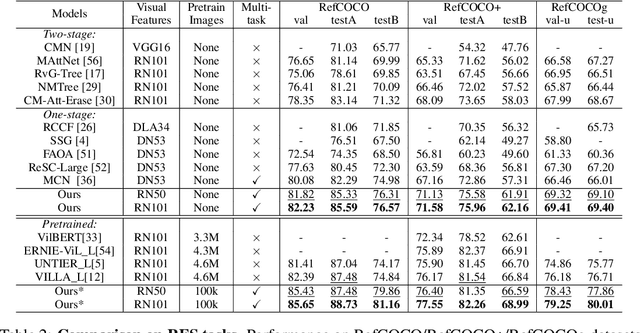
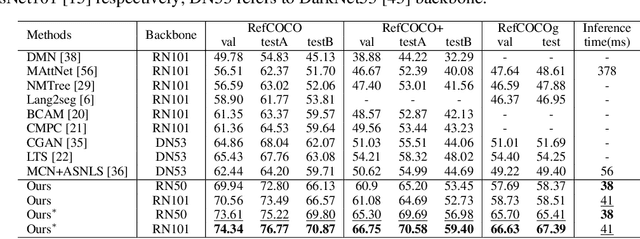

As an important step towards visual reasoning, visual grounding (e.g., phrase localization, referring expression comprehension/segmentation) has been widely explored Previous approaches to referring expression comprehension (REC) or segmentation (RES) either suffer from limited performance, due to a two-stage setup, or require the designing of complex task-specific one-stage architectures. In this paper, we propose a simple one-stage multi-task framework for visual grounding tasks. Specifically, we leverage a transformer architecture, where two modalities are fused in a visual-lingual encoder. In the decoder, the model learns to generate contextualized lingual queries which are then decoded and used to directly regress the bounding box and produce a segmentation mask for the corresponding referred regions. With this simple but highly contextualized model, we outperform state-of-the-arts methods by a large margin on both REC and RES tasks. We also show that a simple pre-training schedule (on an external dataset) further improves the performance. Extensive experiments and ablations illustrate that our model benefits greatly from contextualized information and multi-task training.
Learning Spatial and Spatio-Temporal Pixel Aggregations for Image and Video Denoising
Jan 26, 2021
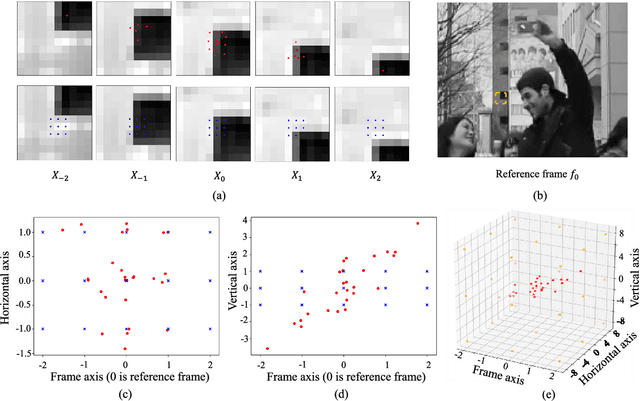
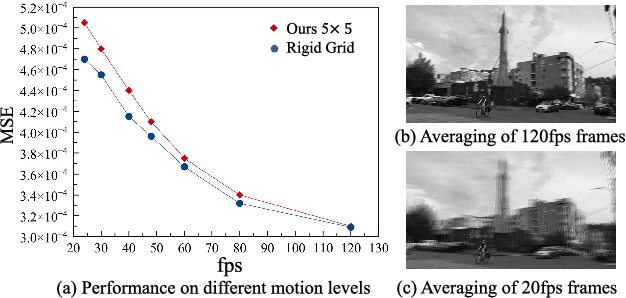
Existing denoising methods typically restore clear results by aggregating pixels from the noisy input. Instead of relying on hand-crafted aggregation schemes, we propose to explicitly learn this process with deep neural networks. We present a spatial pixel aggregation network and learn the pixel sampling and averaging strategies for image denoising. The proposed model naturally adapts to image structures and can effectively improve the denoised results. Furthermore, we develop a spatio-temporal pixel aggregation network for video denoising to efficiently sample pixels across the spatio-temporal space. Our method is able to solve the misalignment issues caused by large motion in dynamic scenes. In addition, we introduce a new regularization term for effectively training the proposed video denoising model. We present extensive analysis of the proposed method and demonstrate that our model performs favorably against the state-of-the-art image and video denoising approaches on both synthetic and real-world data.
* Project page: https://sites.google.com/view/xiangyuxu/denoise_stpan. arXiv admin note: substantial text overlap with arXiv:1904.06903
TDAF: Top-Down Attention Framework for Vision Tasks
Dec 14, 2020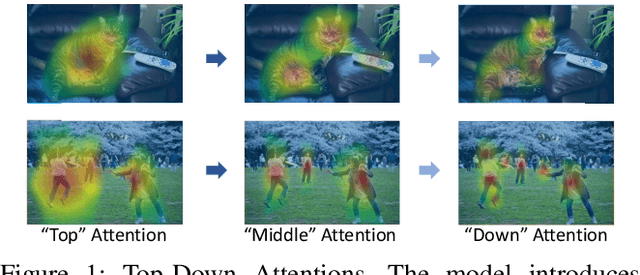
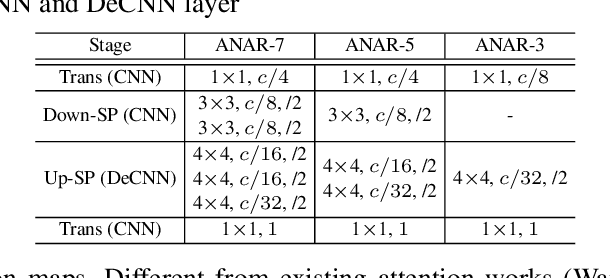
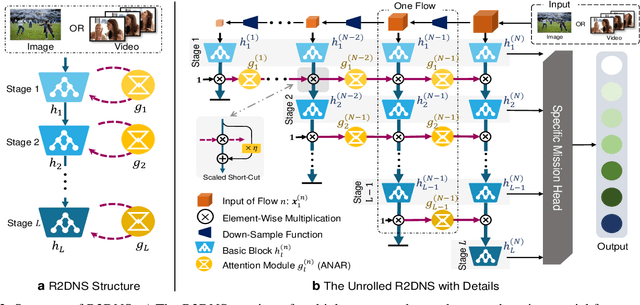
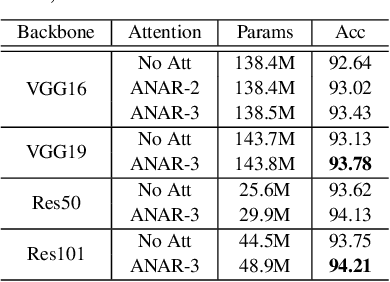
Human attention mechanisms often work in a top-down manner, yet it is not well explored in vision research. Here, we propose the Top-Down Attention Framework (TDAF) to capture top-down attentions, which can be easily adopted in most existing models. The designed Recursive Dual-Directional Nested Structure in it forms two sets of orthogonal paths, recursive and structural ones, where bottom-up spatial features and top-down attention features are extracted respectively. Such spatial and attention features are nested deeply, therefore, the proposed framework works in a mixed top-down and bottom-up manner. Empirical evidence shows that our TDAF can capture effective stratified attention information and boost performance. ResNet with TDAF achieves 2.0% improvements on ImageNet. For object detection, the performance is improved by 2.7% AP over FCOS. For pose estimation, TDAF improves the baseline by 1.6%. And for action recognition, the 3D-ResNet adopting TDAF achieves improvements of 1.7% accuracy.