 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoNIC Challenge: Pushing the Frontiers of Nuclear Detection, Segmentation, Classification and Counting
Mar 14, 2023



Nuclear detection, segmentation and morphometric profiling are essential in helping us further understand the relationship between histology and patient outcome. To drive innovation in this area, we setup a community-wide challenge using the largest available dataset of its kind to assess nuclear segmentation and cellular composition. Our challenge, named CoNIC, stimulated the development of reproducible algorithms for cellular recognition with real-time result inspection on public leaderboards. We conducted an extensive post-challenge analysis based on the top-performing models using 1,658 whole-slide images of colon tissue. With around 700 million detected nuclei per model, associated features were used for dysplasia grading and survival analysis, where we demonstrated that the challenge's improvement over the previous state-of-the-art led to significant boosts in downstream performance. Our findings also suggest that eosinophils and neutrophils play an important role in the tumour microevironment. We release challenge models and WSI-level results to foster the development of further methods for biomarker discovery.
AIROGS: Artificial Intelligence for RObust Glaucoma Screening Challenge
Feb 10, 2023



The early detection of glaucoma is essential in preventing visual impairment. Artificial intelligence (AI) can be used to analyze color fundus photographs (CFPs) in a cost-effective manner, making glaucoma screening more accessible. While AI models for glaucoma screening from CFPs have shown promising results in laboratory settings, their performance decreases significantly in real-world scenarios due to the presence of out-of-distribution and low-quality images. To address this issue, we propose the Artificial Intelligence for Robust Glaucoma Screening (AIROGS) challenge. This challenge includes a large dataset of around 113,000 images from about 60,000 patients and 500 different screening centers, and encourages the development of algorithms that are robust to ungradable and unexpected input data. We evaluated solutions from 14 teams in this paper, and found that the best teams performed similarly to a set of 20 expert ophthalmologists and optometrists. The highest-scoring team achieved an area under the receiver operating characteristic curve of 0.99 (95% CI: 0.98-0.99) for detecting ungradable images on-the-fly. Additionally, many of the algorithms showed robust performance when tested on three other publicly available datasets. These results demonstrate the feasibility of robust AI-enabled glaucoma screening.
AIM 2020 Challenge on Rendering Realistic Bokeh
Nov 10, 2020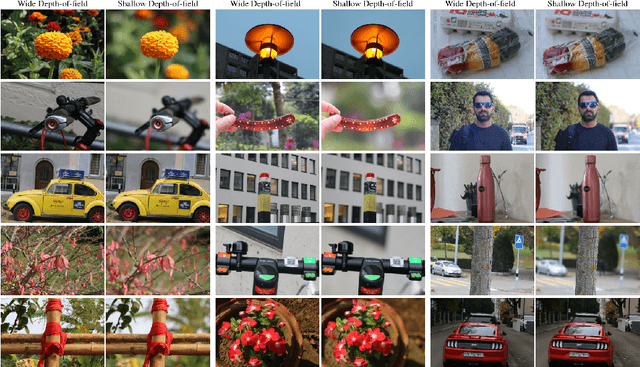


This paper reviews the second AIM realistic bokeh effect rendering challenge and provides the description of the proposed solutions and results. The participating teams were solving a real-world bokeh simulation problem, where the goal was to learn a realistic shallow focus technique using a large-scale EBB! bokeh dataset consisting of 5K shallow / wide depth-of-field image pairs captured using the Canon 7D DSLR camera. The participants had to render bokeh effect based on only one single frame without any additional data from other cameras or sensors. The target metric used in this challenge combined the runtime and the perceptual quality of the solutions measured in the user study. To ensure the efficiency of the submitted models, we measured their runtime on standard desktop CPUs as well as were running the models on smartphone GPUs. The proposed solutions significantly improved the baseline results, defining the state-of-the-art for practical bokeh effect rendering problem.
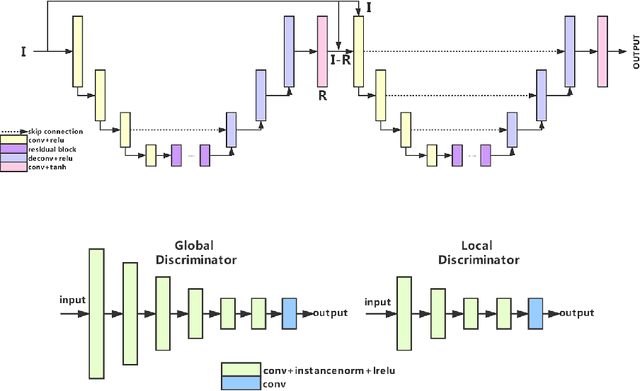
AIM 2020: Scene Relighting and Illumination Estimation Challenge
Sep 27, 2020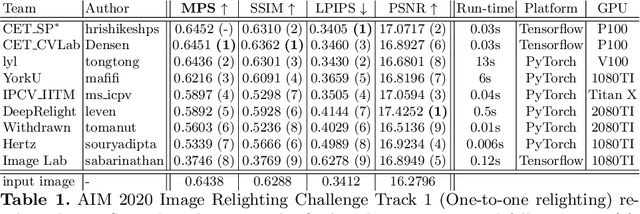

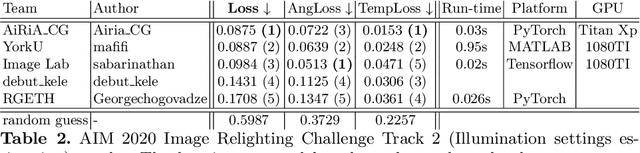

We review the AIM 2020 challenge on virtual image relighting and illumination estimation. This paper presents the novel VIDIT dataset used in the challenge and the different proposed solutions and final evaluation results over the 3 challenge tracks. The first track considered one-to-one relighting; the objective was to relight an input photo of a scene with a different color temperature and illuminant orientation (i.e., light source position). The goal of the second track was to estimate illumination settings, namely the color temperature and orientation, from a given image. Lastly, the third track dealt with any-to-any relighting, thus a generalization of the first track. The target color temperature and orientation, rather than being pre-determined, are instead given by a guide image. Participants were allowed to make use of their track 1 and 2 solutions for track 3. The tracks had 94, 52, and 56 registered participants, respectively, leading to 20 confirmed submissions in the final competition stage.
Transform Domain Pyramidal Dilated Convolution Networks For Restoration of Under Display Camera Images
Sep 20, 2020
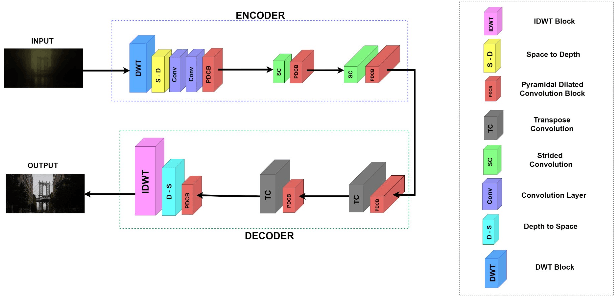
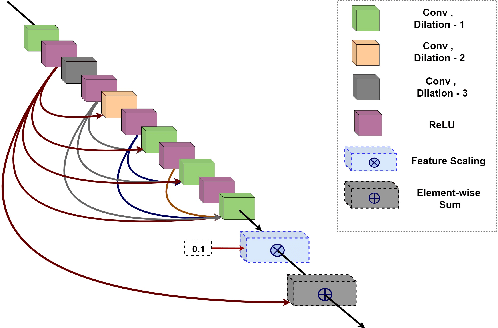
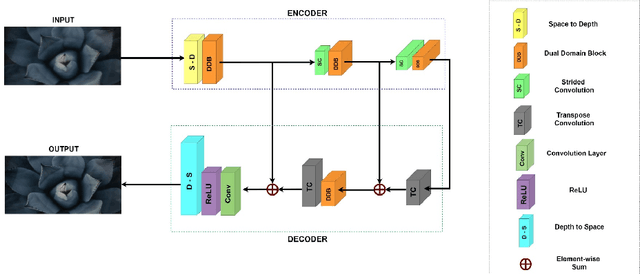
Under-display camera (UDC) is a novel technology that can make digital imaging experience in handheld devices seamless by providing large screen-to-body ratio. UDC images are severely degraded owing to their positioning under a display screen. This work addresses the restoration of images degraded as a result of UDC imaging. Two different networks are proposed for the restoration of images taken with two types of UDC technologies. The first method uses a pyramidal dilated convolution within a wavelet decomposed convolutional neural network for pentile-organic LED (P-OLED) based display system. The second method employs pyramidal dilated convolution within a discrete cosine transform based dual domain network to restore images taken using a transparent-organic LED (T-OLED) based UDC system. The first method produced very good quality restored images and was the winning entry in European Conference on Computer Vision (ECCV) 2020 challenge on image restoration for Under-display Camera - Track 2 - P-OLED evaluated based on PSNR and SSIM. The second method scored fourth position in Track-1 (T-OLED) of the challenge evaluated based on the same metrics.
AIM 2020 Challenge on Efficient Super-Resolution: Methods and Results
Sep 15, 2020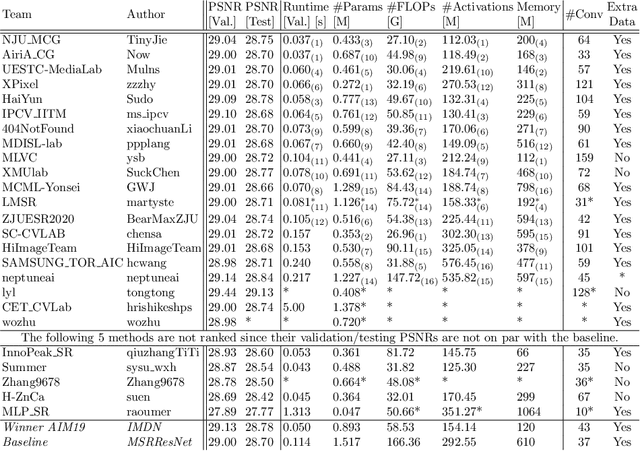
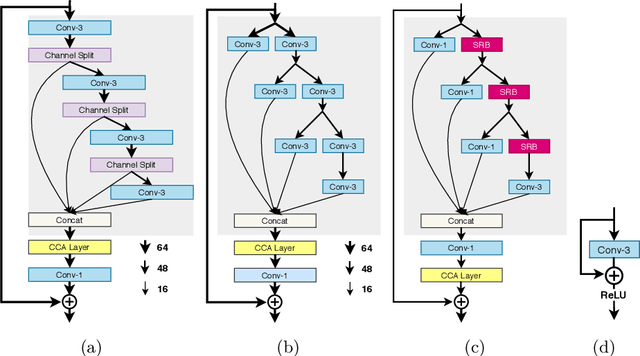
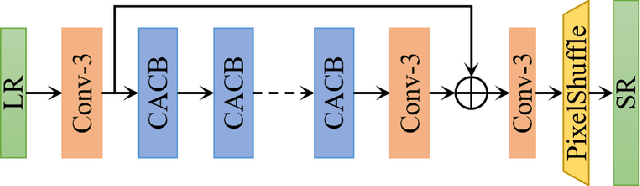
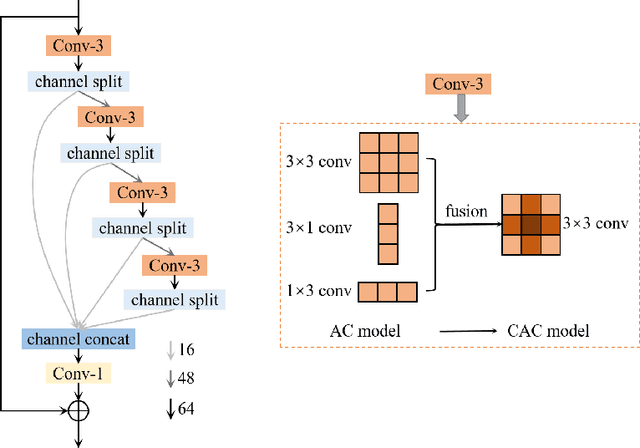
This paper reviews the AIM 2020 challenge on efficient single image super-resolution with focus on the proposed solutions and results. The challenge task was to super-resolve an input image with a magnification factor x4 based on a set of prior examples of low and corresponding high resolution images. The goal is to devise a network that reduces one or several aspects such as runtime, parameter count, FLOPs, activations, and memory consumption while at least maintaining PSNR of MSRResNet. The track had 150 registered participants, and 25 teams submitted the final results. They gauge the state-of-the-art in efficient single image super-resolution.
WDRN : A Wavelet Decomposed RelightNet for Image Relighting
Sep 14, 2020
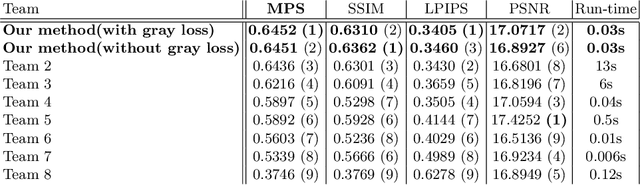
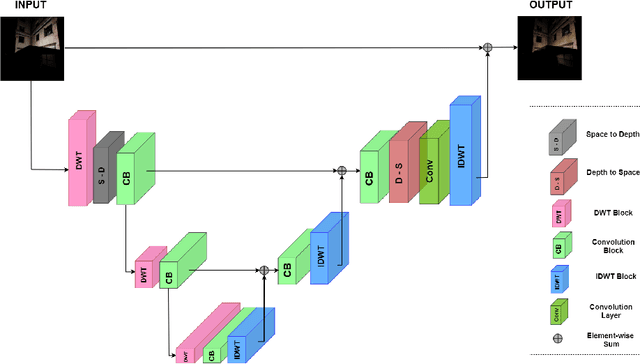
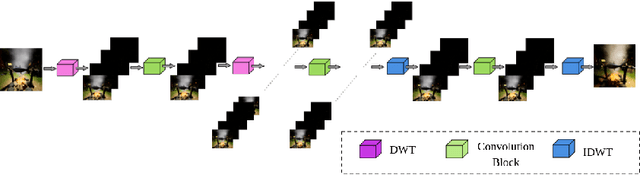
The task of recalibrating the illumination settings in an image to a target configuration is known as relighting. Relighting techniques have potential applications in digital photography, gaming industry and in augmented reality. In this paper, we address the one-to-one relighting problem where an image at a target illumination settings is predicted given an input image with specific illumination conditions. To this end, we propose a wavelet decomposed RelightNet called WDRN which is a novel encoder-decoder network employing wavelet based decomposition followed by convolution layers under a muti-resolution framework. We also propose a novel loss function called gray loss that ensures efficient learning of gradient in illumination along different directions of the ground truth image giving rise to visually superior relit images. The proposed solution won the first position in the relighting challenge event in advances in image manipulation (AIM) 2020 workshop which proves its effectiveness measured in terms of a Mean Perceptual Score which in turn is measured using SSIM and a Learned Perceptual Image Patch Similarity score.
AIM 2020 Challenge on Video Extreme Super-Resolution: Methods and Results
Sep 14, 2020This paper reviews the video extreme super-resolution challenge associated with the AIM 2020 workshop at ECCV 2020. Common scaling factors for learned video super-resolution (VSR) do not go beyond factor 4. Missing information can be restored well in this region, especially in HR videos, where the high-frequency content mostly consists of texture details. The task in this challenge is to upscale videos with an extreme factor of 16, which results in more serious degradations that also affect the structural integrity of the videos. A single pixel in the low-resolution (LR) domain corresponds to 256 pixels in the high-resolution (HR) domain. Due to this massive information loss, it is hard to accurately restore the missing information. Track 1 is set up to gauge the state-of-the-art for such a demanding task, where fidelity to the ground truth is measured by PSNR and SSIM. Perceptually higher quality can be achieved in trade-off for fidelity by generating plausible high-frequency content. Track 2 therefore aims at generating visually pleasing results, which are ranked according to human perception, evaluated by a user study. In contrast to single image super-resolution (SISR), VSR can benefit from additional information in the temporal domain. However, this also imposes an additional requirement, as the generated frames need to be consistent along time.
UDC 2020 Challenge on Image Restoration of Under-Display Camera: Methods and Results
Aug 18, 2020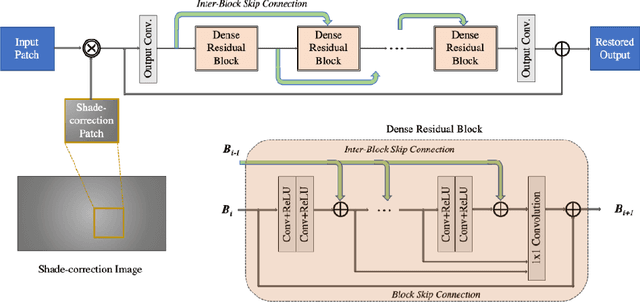
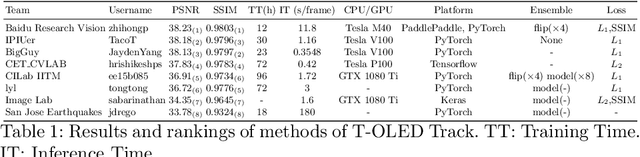
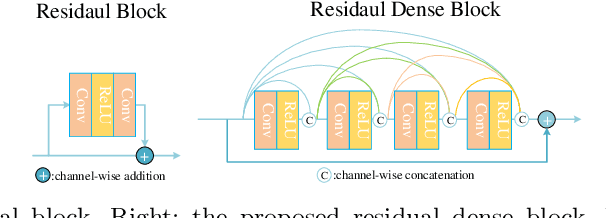
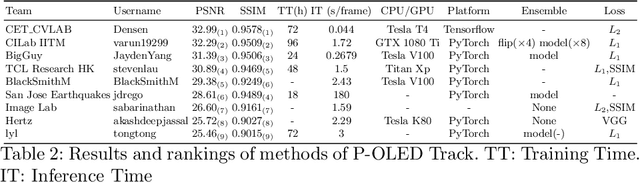
This paper is the report of the first Under-Display Camera (UDC) image restoration challenge in conjunction with the RLQ workshop at ECCV 2020. The challenge is based on a newly-collected database of Under-Display Camera. The challenge tracks correspond to two types of display: a 4k Transparent OLED (T-OLED) and a phone Pentile OLED (P-OLED). Along with about 150 teams registered the challenge, eight and nine teams submitted the results during the testing phase for each track. The results in the paper are state-of-the-art restoration performance of Under-Display Camera Restoration. Datasets and paper are available at https://yzhouas.github.io/projects/UDC/udc.html.
NTIRE 2020 Challenge on Image Demoireing: Methods and Results
May 06, 2020



This paper reviews the Challenge on Image Demoireing that was part of the New Trends in Image Restoration and Enhancement (NTIRE) workshop, held in conjunction with CVPR 2020. Demoireing is a difficult task of removing moire patterns from an image to reveal an underlying clean image. The challenge was divided into two tracks. Track 1 targeted the single image demoireing problem, which seeks to remove moire patterns from a single image. Track 2 focused on the burst demoireing problem, where a set of degraded moire images of the same scene were provided as input, with the goal of producing a single demoired image as output. The methods were ranked in terms of their fidelity, measured using the peak signal-to-noise ratio (PSNR) between the ground truth clean images and the restored images produced by the participants' methods. The tracks had 142 and 99 registered participants, respectively, with a total of 14 and 6 submissions in the final testing stage. The entries span the current state-of-the-art in image and burst image demoireing problems.