 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAIM 2020: Scene Relighting and Illumination Estimation Challenge
Sep 27, 2020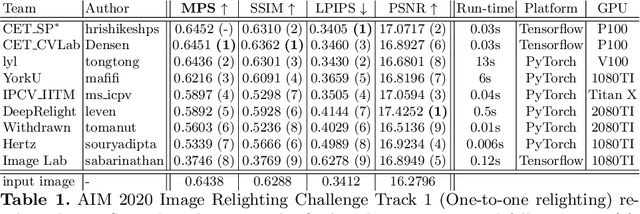

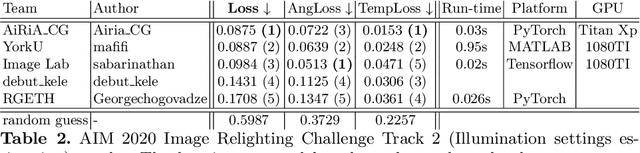

We review the AIM 2020 challenge on virtual image relighting and illumination estimation. This paper presents the novel VIDIT dataset used in the challenge and the different proposed solutions and final evaluation results over the 3 challenge tracks. The first track considered one-to-one relighting; the objective was to relight an input photo of a scene with a different color temperature and illuminant orientation (i.e., light source position). The goal of the second track was to estimate illumination settings, namely the color temperature and orientation, from a given image. Lastly, the third track dealt with any-to-any relighting, thus a generalization of the first track. The target color temperature and orientation, rather than being pre-determined, are instead given by a guide image. Participants were allowed to make use of their track 1 and 2 solutions for track 3. The tracks had 94, 52, and 56 registered participants, respectively, leading to 20 confirmed submissions in the final competition stage.
AIM 2020 Challenge on Real Image Super-Resolution: Methods and Results
Sep 25, 2020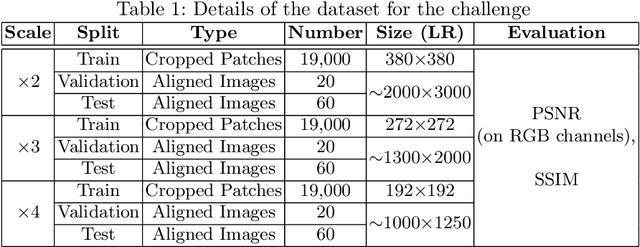
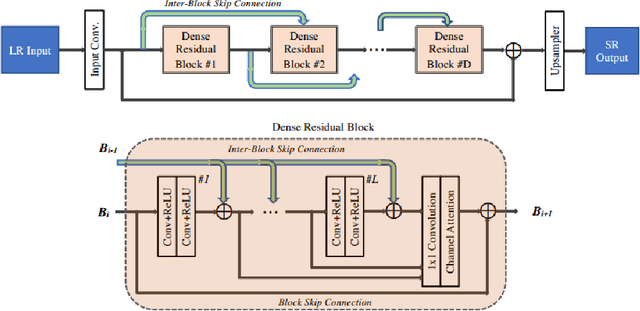
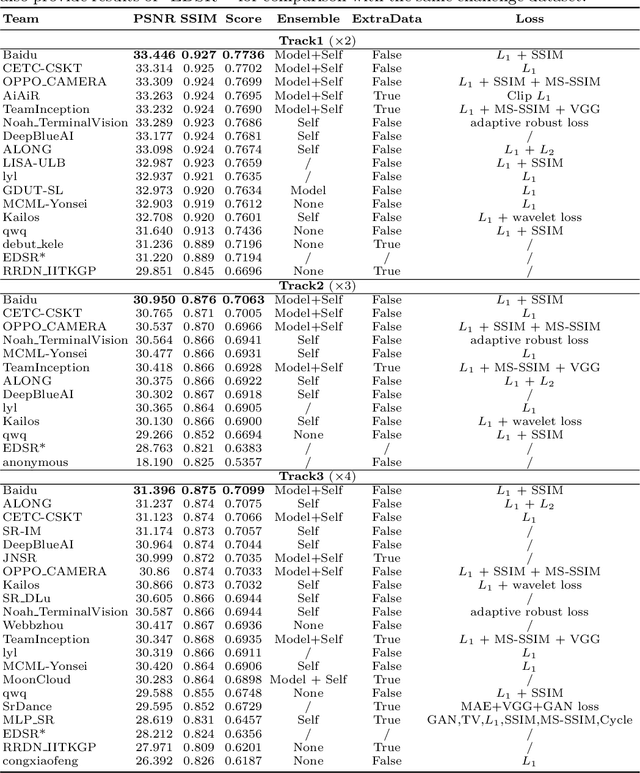
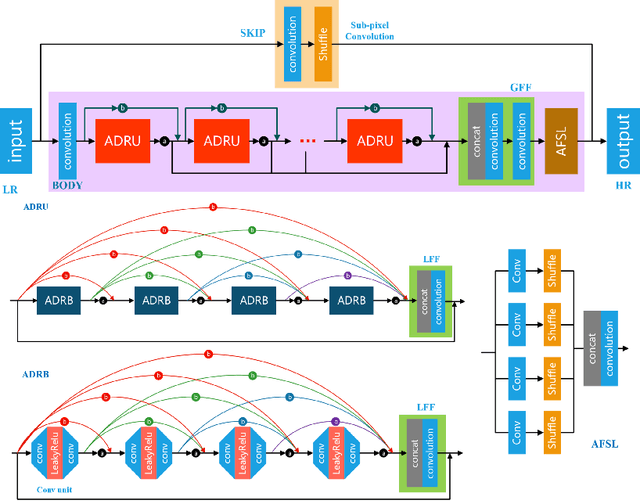
This paper introduces the real image Super-Resolution (SR) challenge that was part of the Advances in Image Manipulation (AIM) workshop, held in conjunction with ECCV 2020. This challenge involves three tracks to super-resolve an input image for $\times$2, $\times$3 and $\times$4 scaling factors, respectively. The goal is to attract more attention to realistic image degradation for the SR task, which is much more complicated and challenging, and contributes to real-world image super-resolution applications. 452 participants were registered for three tracks in total, and 24 teams submitted their results. They gauge the state-of-the-art approaches for real image SR in terms of PSNR and SSIM.
AIM 2020 Challenge on Efficient Super-Resolution: Methods and Results
Sep 15, 2020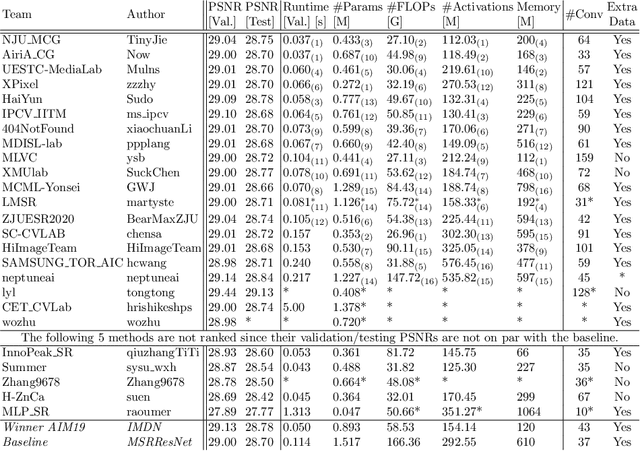
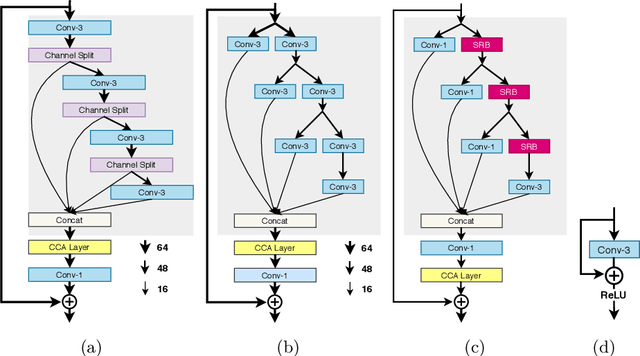
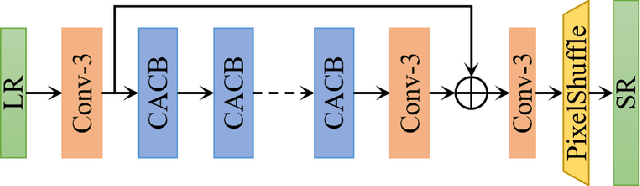
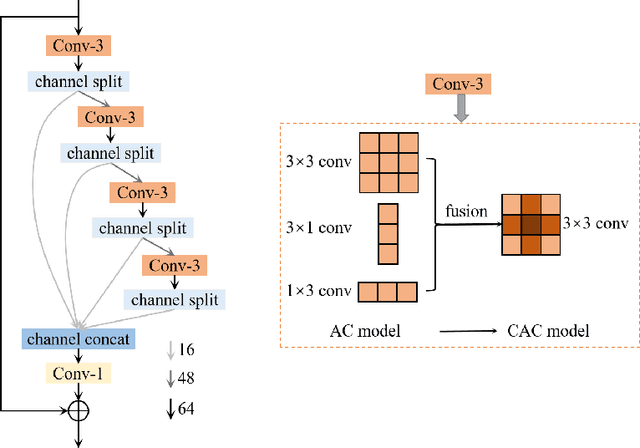
This paper reviews the AIM 2020 challenge on efficient single image super-resolution with focus on the proposed solutions and results. The challenge task was to super-resolve an input image with a magnification factor x4 based on a set of prior examples of low and corresponding high resolution images. The goal is to devise a network that reduces one or several aspects such as runtime, parameter count, FLOPs, activations, and memory consumption while at least maintaining PSNR of MSRResNet. The track had 150 registered participants, and 25 teams submitted the final results. They gauge the state-of-the-art in efficient single image super-resolution.
AIM 2020 Challenge on Video Extreme Super-Resolution: Methods and Results
Sep 14, 2020This paper reviews the video extreme super-resolution challenge associated with the AIM 2020 workshop at ECCV 2020. Common scaling factors for learned video super-resolution (VSR) do not go beyond factor 4. Missing information can be restored well in this region, especially in HR videos, where the high-frequency content mostly consists of texture details. The task in this challenge is to upscale videos with an extreme factor of 16, which results in more serious degradations that also affect the structural integrity of the videos. A single pixel in the low-resolution (LR) domain corresponds to 256 pixels in the high-resolution (HR) domain. Due to this massive information loss, it is hard to accurately restore the missing information. Track 1 is set up to gauge the state-of-the-art for such a demanding task, where fidelity to the ground truth is measured by PSNR and SSIM. Perceptually higher quality can be achieved in trade-off for fidelity by generating plausible high-frequency content. Track 2 therefore aims at generating visually pleasing results, which are ranked according to human perception, evaluated by a user study. In contrast to single image super-resolution (SISR), VSR can benefit from additional information in the temporal domain. However, this also imposes an additional requirement, as the generated frames need to be consistent along time.
UDC 2020 Challenge on Image Restoration of Under-Display Camera: Methods and Results
Aug 18, 2020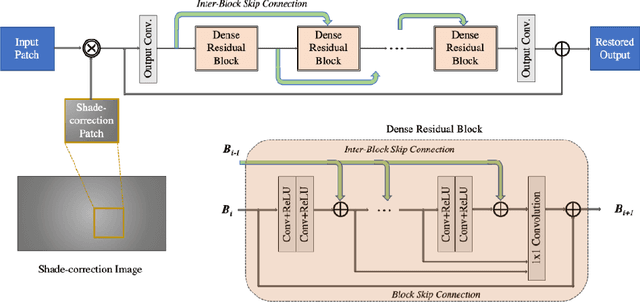
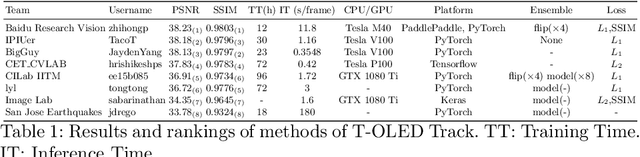
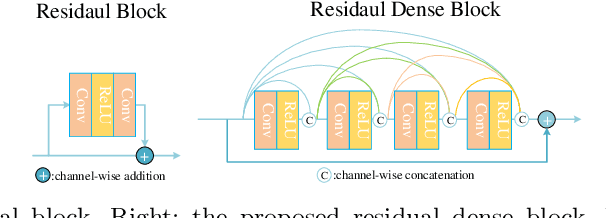
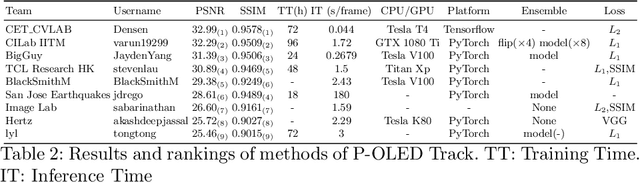
This paper is the report of the first Under-Display Camera (UDC) image restoration challenge in conjunction with the RLQ workshop at ECCV 2020. The challenge is based on a newly-collected database of Under-Display Camera. The challenge tracks correspond to two types of display: a 4k Transparent OLED (T-OLED) and a phone Pentile OLED (P-OLED). Along with about 150 teams registered the challenge, eight and nine teams submitted the results during the testing phase for each track. The results in the paper are state-of-the-art restoration performance of Under-Display Camera Restoration. Datasets and paper are available at https://yzhouas.github.io/projects/UDC/udc.html.
NTIRE 2020 Challenge on Real-World Image Super-Resolution: Methods and Results
May 05, 2020
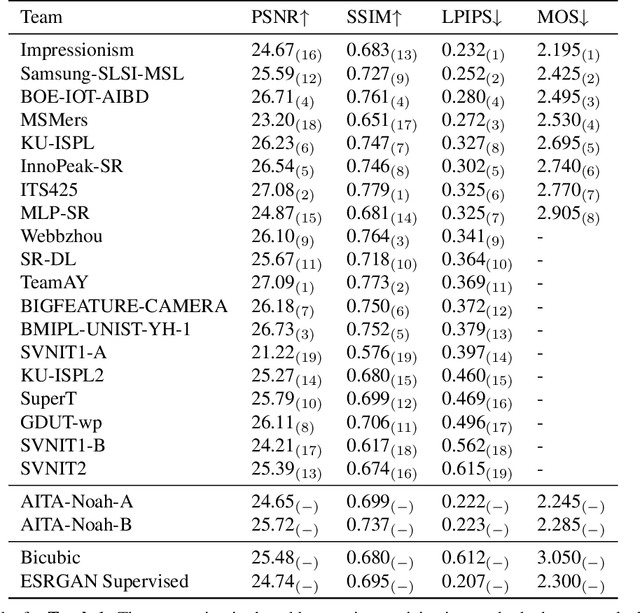
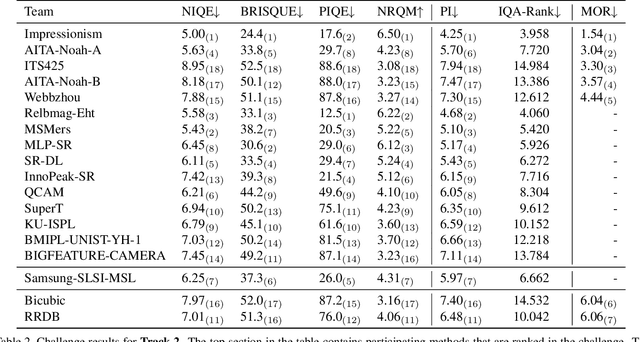

This paper reviews the NTIRE 2020 challenge on real world super-resolution. It focuses on the participating methods and final results. The challenge addresses the real world setting, where paired true high and low-resolution images are unavailable. For training, only one set of source input images is therefore provided along with a set of unpaired high-quality target images. In Track 1: Image Processing artifacts, the aim is to super-resolve images with synthetically generated image processing artifacts. This allows for quantitative benchmarking of the approaches \wrt a ground-truth image. In Track 2: Smartphone Images, real low-quality smart phone images have to be super-resolved. In both tracks, the ultimate goal is to achieve the best perceptual quality, evaluated using a human study. This is the second challenge on the subject, following AIM 2019, targeting to advance the state-of-the-art in super-resolution. To measure the performance we use the benchmark protocol from AIM 2019. In total 22 teams competed in the final testing phase, demonstrating new and innovative solutions to the problem.
NTIRE 2020 Challenge on Perceptual Extreme Super-Resolution: Methods and Results
May 03, 2020
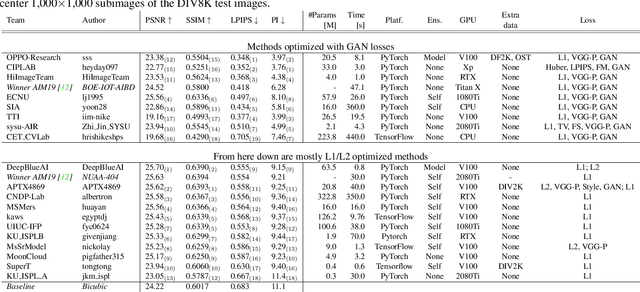

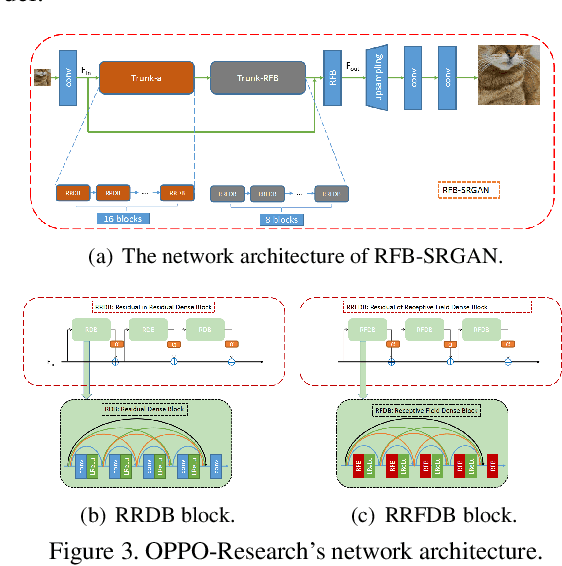
This paper reviews the NTIRE 2020 challenge on perceptual extreme super-resolution with focus on proposed solutions and results. The challenge task was to super-resolve an input image with a magnification factor 16 based on a set of prior examples of low and corresponding high resolution images. The goal is to obtain a network design capable to produce high resolution results with the best perceptual quality and similar to the ground truth. The track had 280 registered participants, and 19 teams submitted the final results. They gauge the state-of-the-art in single image super-resolution.
Attribute-guided Feature Learning Network for Vehicle Re-identification
Jan 12, 2020
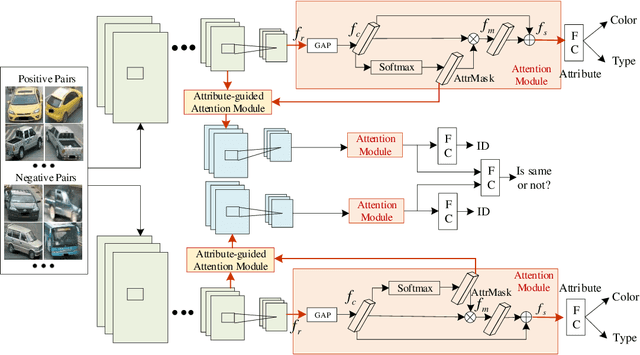
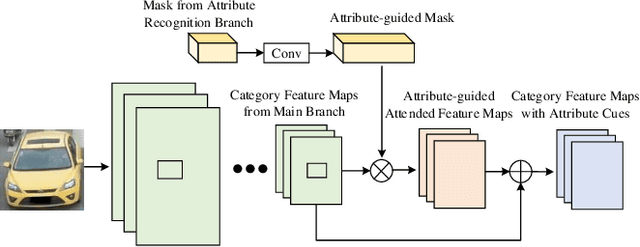

Vehicle re-identification (reID) plays an important role in the automatic analysis of the increasing urban surveillance videos, which has become a hot topic in recent years. However, it poses the critical but challenging problem that is caused by various viewpoints of vehicles, diversified illuminations and complicated environments. Till now, most existing vehicle reID approaches focus on learning metrics or ensemble to derive better representation, which are only take identity labels of vehicle into consideration. However, the attributes of vehicle that contain detailed descriptions are beneficial for training reID model. Hence, this paper proposes a novel Attribute-Guided Network (AGNet), which could learn global representation with the abundant attribute features in an end-to-end manner. Specially, an attribute-guided module is proposed in AGNet to generate the attribute mask which could inversely guide to select discriminative features for category classification. Besides that, in our proposed AGNet, an attribute-based label smoothing (ALS) loss is presented to better train the reID model, which can strength the distinct ability of vehicle reID model to regularize AGNet model according to the attributes. Comprehensive experimental results clearly demonstrate that our method achieves excellent performance on both VehicleID dataset and VeRi-776 dataset.
Eliminating cross-camera bias for vehicle re-identification
Dec 21, 2019
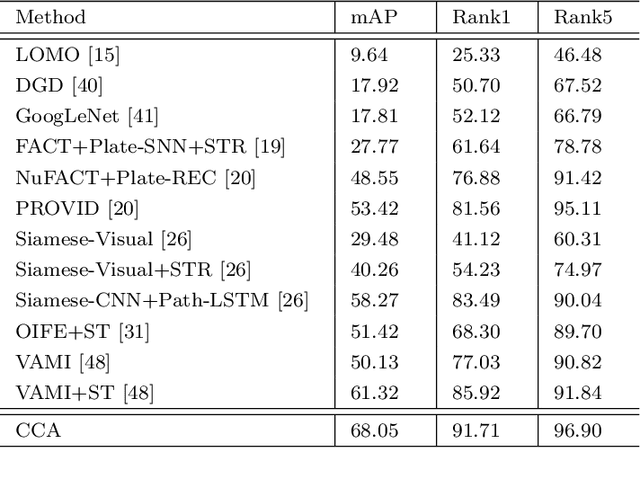
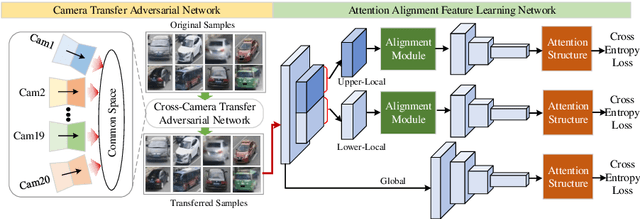
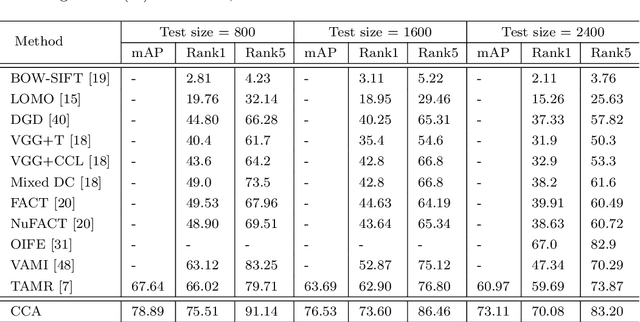
Vehicle re-identification (reID) often requires recognize a target vehicle in large datasets captured from multi-cameras. It plays an important role in the automatic analysis of the increasing urban surveillance videos, which has become a hot topic in recent years. However, the appearance of vehicle images is easily affected by the environment that various illuminations, different backgrounds and viewpoints, which leads to the large bias between different cameras. To address this problem, this paper proposes a cross-camera adaptation framework (CCA), which smooths the bias by exploiting the common space between cameras for all samples. CCA first transfers images from multi-cameras into one camera to reduce the impact of the illumination and resolution, which generates the samples with the similar distribution. Then, to eliminate the influence of background and focus on the valuable parts, we propose an attention alignment network (AANet) to learn powerful features for vehicle reID. Specially, in AANet, the spatial transfer network with attention module is introduced to locate a series of the most discriminative regions with high-attention weights and suppress the background. Moreover, comprehensive experimental results have demonstrated that our proposed CCA can achieve excellent performances on benchmark datasets VehicleID and VeRi-776.
Cross Domain Knowledge Transfer for Unsupervised Vehicle Re-identification
Mar 19, 2019

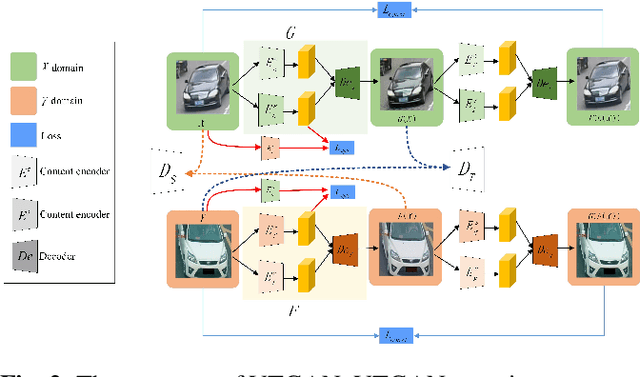
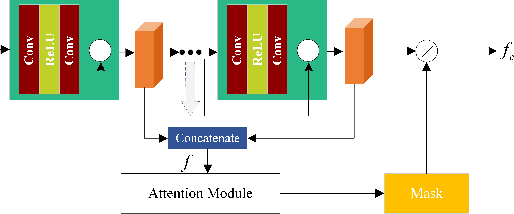
Vehicle re-identification (reID) is to identify a target vehicle in different cameras with non-overlapping views. When deploy the well-trained model to a new dataset directly, there is a severe performance drop because of differences among datasets named domain bias. To address this problem, this paper proposes an domain adaptation framework which contains an image-to-image translation network named vehicle transfer generative adversarial network (VTGAN) and an attention-based feature learning network (ATTNet). VTGAN could make images from the source domain (well-labeled) have the style of target domain (unlabeled) and preserve identity information of source domain. To further improve the domain adaptation ability for various backgrounds, ATTNet is proposed to train generated images with the attention structure for vehicle reID. Comprehensive experimental results clearly demonstrate that our method achieves excellent performance on VehicleID dataset.