 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Multi-domain Face Landmark Detection with Synthetic Data from Diffusion model
Jan 24, 2024



Recently, deep learning-based facial landmark detection for in-the-wild faces has achieved significant improvement. However, there are still challenges in face landmark detection in other domains (e.g. cartoon, caricature, etc). This is due to the scarcity of extensively annotated training data. To tackle this concern, we design a two-stage training approach that effectively leverages limited datasets and the pre-trained diffusion model to obtain aligned pairs of landmarks and face in multiple domains. In the first stage, we train a landmark-conditioned face generation model on a large dataset of real faces. In the second stage, we fine-tune the above model on a small dataset of image-landmark pairs with text prompts for controlling the domain. Our new designs enable our method to generate high-quality synthetic paired datasets from multiple domains while preserving the alignment between landmarks and facial features. Finally, we fine-tuned a pre-trained face landmark detection model on the synthetic dataset to achieve multi-domain face landmark detection. Our qualitative and quantitative results demonstrate that our method outperforms existing methods on multi-domain face landmark detection.
MPE4G: Multimodal Pretrained Encoder for Co-Speech Gesture Generation
May 25, 2023



When virtual agents interact with humans, gestures are crucial to delivering their intentions with speech. Previous multimodal co-speech gesture generation models required encoded features of all modalities to generate gestures. If some input modalities are removed or contain noise, the model may not generate the gestures properly. To acquire robust and generalized encodings, we propose a novel framework with a multimodal pre-trained encoder for co-speech gesture generation. In the proposed method, the multi-head-attention-based encoder is trained with self-supervised learning to contain the information on each modality. Moreover, we collect full-body gestures that consist of 3D joint rotations to improve visualization and apply gestures to the extensible body model. Through the series of experiments and human evaluation, the proposed method renders realistic co-speech gestures not only when all input modalities are given but also when the input modalities are missing or noisy.
* 5 pages, 3 figures
3d human motion generation from the text via gesture action classification and the autoregressive model
Nov 18, 2022



In this paper, a deep learning-based model for 3D human motion generation from the text is proposed via gesture action classification and an autoregressive model. The model focuses on generating special gestures that express human thinking, such as waving and nodding. To achieve the goal, the proposed method predicts expression from the sentences using a text classification model based on a pretrained language model and generates gestures using the gate recurrent unit-based autoregressive model. Especially, we proposed the loss for the embedding space for restoring raw motions and generating intermediate motions well. Moreover, the novel data augmentation method and stop token are proposed to generate variable length motions. To evaluate the text classification model and 3D human motion generation model, a gesture action classification dataset and action-based gesture dataset are collected. With several experiments, the proposed method successfully generates perceptually natural and realistic 3D human motion from the text. Moreover, we verified the effectiveness of the proposed method using a public-available action recognition dataset to evaluate cross-dataset generalization performance.
Efficient dynamic filter for robust and low computational feature extraction
May 03, 2022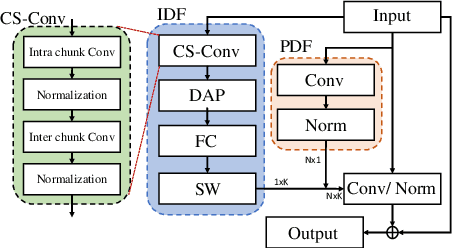
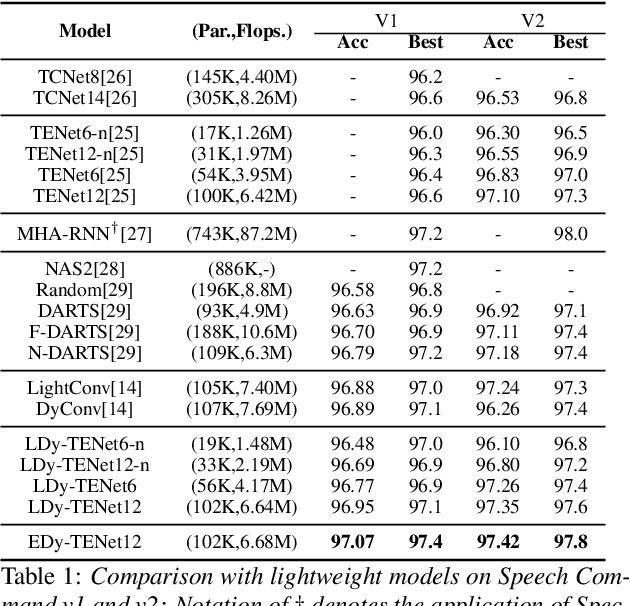
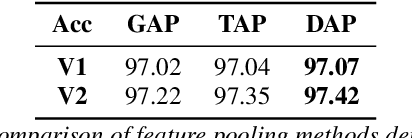
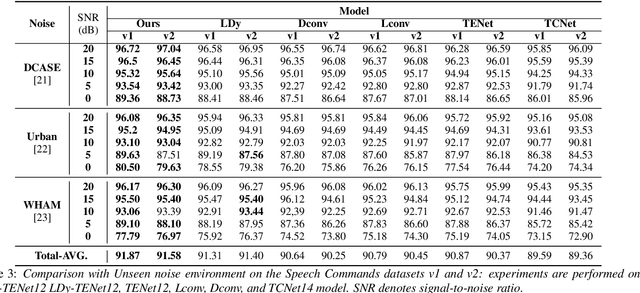
Unseen noise signal which is not considered in a model training process is difficult to anticipate and would lead to performance degradation. Various methods have been investigated to mitigate unseen noise. In our previous work, an Instance-level Dynamic Filter (IDF) and a Pixel Dynamic Filter (PDF) were proposed to extract noise-robust features. However, the performance of the dynamic filter might be degraded since simple feature pooling is used to reduce the computational resource in the IDF part. In this paper, we propose an efficient dynamic filter to enhance the performance of the dynamic filter. Instead of utilizing the simple feature mean, we separate Time-Frequency (T-F) features as non-overlapping chunks, and separable convolutions are carried out for each feature direction (inter chunks and intra chunks). Additionally, we propose Dynamic Attention Pooling that maps high dimensional features as low dimensional feature embeddings. These methods are applied to the IDF for keyword spotting and speaker verification tasks. We confirm that our proposed method performs better in unseen environments (unseen noise and unseen speakers) than state-of-the-art models.
NTIRE 2020 Challenge on Real-World Image Super-Resolution: Methods and Results
May 05, 2020
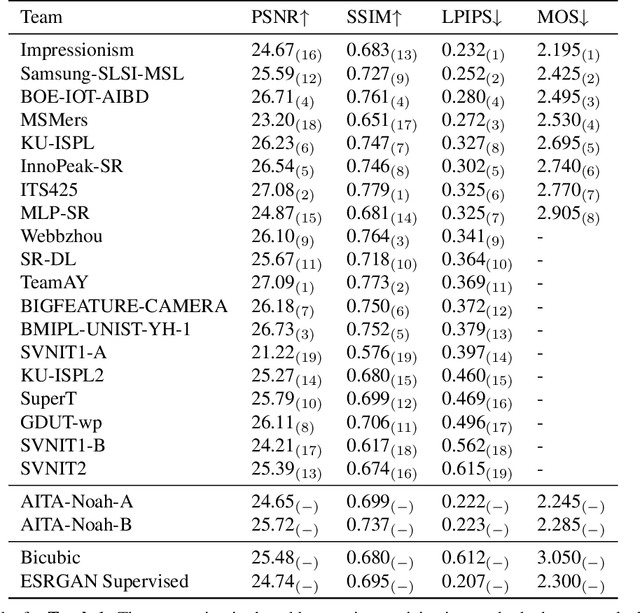
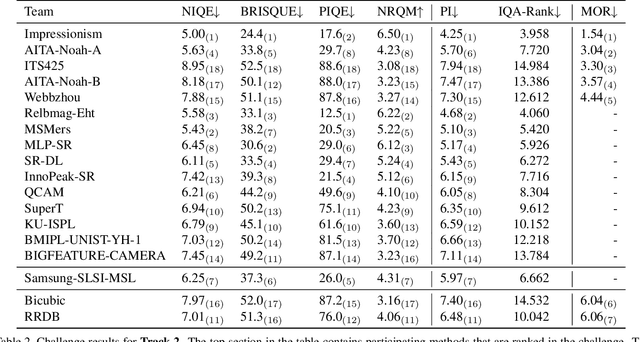

This paper reviews the NTIRE 2020 challenge on real world super-resolution. It focuses on the participating methods and final results. The challenge addresses the real world setting, where paired true high and low-resolution images are unavailable. For training, only one set of source input images is therefore provided along with a set of unpaired high-quality target images. In Track 1: Image Processing artifacts, the aim is to super-resolve images with synthetically generated image processing artifacts. This allows for quantitative benchmarking of the approaches \wrt a ground-truth image. In Track 2: Smartphone Images, real low-quality smart phone images have to be super-resolved. In both tracks, the ultimate goal is to achieve the best perceptual quality, evaluated using a human study. This is the second challenge on the subject, following AIM 2019, targeting to advance the state-of-the-art in super-resolution. To measure the performance we use the benchmark protocol from AIM 2019. In total 22 teams competed in the final testing phase, demonstrating new and innovative solutions to the problem.
NTIRE 2020 Challenge on Perceptual Extreme Super-Resolution: Methods and Results
May 03, 2020
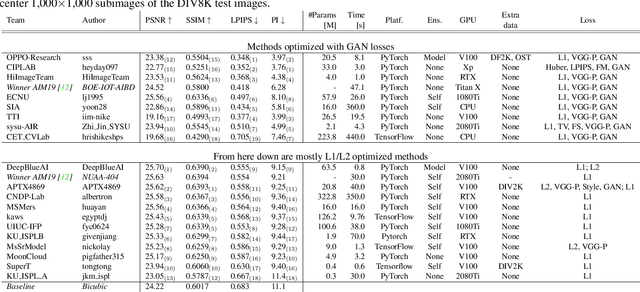

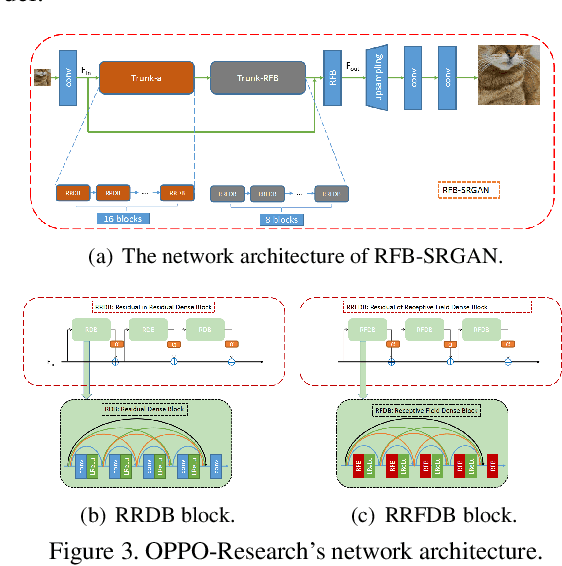
This paper reviews the NTIRE 2020 challenge on perceptual extreme super-resolution with focus on proposed solutions and results. The challenge task was to super-resolve an input image with a magnification factor 16 based on a set of prior examples of low and corresponding high resolution images. The goal is to obtain a network design capable to produce high resolution results with the best perceptual quality and similar to the ground truth. The track had 280 registered participants, and 19 teams submitted the final results. They gauge the state-of-the-art in single image super-resolution.