 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrontier AI Risk Management Framework in Practice: A Risk Analysis Technical Report
Jul 22, 2025



To understand and identify the unprecedented risks posed by rapidly advancing artificial intelligence (AI) models, this report presents a comprehensive assessment of their frontier risks. Drawing on the E-T-C analysis (deployment environment, threat source, enabling capability) from the Frontier AI Risk Management Framework (v1.0) (SafeWork-F1-Framework), we identify critical risks in seven areas: cyber offense, biological and chemical risks, persuasion and manipulation, uncontrolled autonomous AI R\&D, strategic deception and scheming, self-replication, and collusion. Guided by the "AI-$45^\circ$ Law," we evaluate these risks using "red lines" (intolerable thresholds) and "yellow lines" (early warning indicators) to define risk zones: green (manageable risk for routine deployment and continuous monitoring), yellow (requiring strengthened mitigations and controlled deployment), and red (necessitating suspension of development and/or deployment). Experimental results show that all recent frontier AI models reside in green and yellow zones, without crossing red lines. Specifically, no evaluated models cross the yellow line for cyber offense or uncontrolled AI R\&D risks. For self-replication, and strategic deception and scheming, most models remain in the green zone, except for certain reasoning models in the yellow zone. In persuasion and manipulation, most models are in the yellow zone due to their effective influence on humans. For biological and chemical risks, we are unable to rule out the possibility of most models residing in the yellow zone, although detailed threat modeling and in-depth assessment are required to make further claims. This work reflects our current understanding of AI frontier risks and urges collective action to mitigate these challenges.
A Spatial Relationship Aware Dataset for Robotics
Jun 14, 2025Robotic task planning in real-world environments requires not only object recognition but also a nuanced understanding of spatial relationships between objects. We present a spatial-relationship-aware dataset of nearly 1,000 robot-acquired indoor images, annotated with object attributes, positions, and detailed spatial relationships. Captured using a Boston Dynamics Spot robot and labelled with a custom annotation tool, the dataset reflects complex scenarios with similar or identical objects and intricate spatial arrangements. We benchmark six state-of-the-art scene-graph generation models on this dataset, analysing their inference speed and relational accuracy. Our results highlight significant differences in model performance and demonstrate that integrating explicit spatial relationships into foundation models, such as ChatGPT 4o, substantially improves their ability to generate executable, spatially-aware plans for robotics. The dataset and annotation tool are publicly available at https://github.com/PengPaulWang/SpatialAwareRobotDataset, supporting further research in spatial reasoning for robotics.
Language Embedding Meets Dynamic Graph: A New Exploration for Neural Architecture Representation Learning
Jun 09, 2025Neural Architecture Representation Learning aims to transform network models into feature representations for predicting network attributes, playing a crucial role in deploying and designing networks for real-world applications. Recently, inspired by the success of transformers, transformer-based models integrated with Graph Neural Networks (GNNs) have achieved significant progress in representation learning. However, current methods still have some limitations. First, existing methods overlook hardware attribute information, which conflicts with the current trend of diversified deep learning hardware and limits the practical applicability of models. Second, current encoding approaches rely on static adjacency matrices to represent topological structures, failing to capture the structural differences between computational nodes, which ultimately compromises encoding effectiveness. In this paper, we introduce LeDG-Former, an innovative framework that addresses these limitations through the synergistic integration of language-based semantic embedding and dynamic graph representation learning. Specifically, inspired by large language models (LLMs), we propose a language embedding framework where both neural architectures and hardware platform specifications are projected into a unified semantic space through tokenization and LLM processing, enabling zero-shot prediction across different hardware platforms for the first time. Then, we propose a dynamic graph-based transformer for modeling neural architectures, resulting in improved neural architecture modeling performance. On the NNLQP benchmark, LeDG-Former surpasses previous methods, establishing a new SOTA while demonstrating the first successful cross-hardware latency prediction capability. Furthermore, our framework achieves superior performance on the cell-structured NAS-Bench-101 and NAS-Bench-201 datasets.
SeedEdit 3.0: Fast and High-Quality Generative Image Editing
Jun 06, 2025We introduce SeedEdit 3.0, in companion with our T2I model Seedream 3.0, which significantly improves over our previous SeedEdit versions in both aspects of edit instruction following and image content (e.g., ID/IP) preservation on real image inputs. Additional to model upgrading with T2I, in this report, we present several key improvements. First, we develop an enhanced data curation pipeline with a meta-info paradigm and meta-info embedding strategy that help mix images from multiple data sources. This allows us to scale editing data effectively, and meta information is helpfult to connect VLM with diffusion model more closely. Second, we introduce a joint learning pipeline for computing a diffusion loss and reward losses. Finally, we evaluate SeedEdit 3.0 on our testing benchmarks, for real/synthetic image editing, where it achieves a best trade-off between multiple aspects, yielding a high usability rate of 56.1%, compared to SeedEdit 1.6 (38.4%), GPT4o (37.1%) and Gemini 2.0 (30.3%).
Attention-Only Transformers via Unrolled Subspace Denoising
Jun 04, 2025Despite the popularity of transformers in practice, their architectures are empirically designed and neither mathematically justified nor interpretable. Moreover, as indicated by many empirical studies, some components of transformer architectures may be redundant. To derive a fully interpretable transformer architecture with only necessary components, we contend that the goal of representation learning is to compress a set of noisy initial token representations towards a mixture of low-dimensional subspaces. To compress these noisy token representations, an associated denoising operation naturally takes the form of a multi-head (subspace) self-attention. By unrolling such iterative denoising operations into a deep network, we arrive at a highly compact architecture that consists of \textit{only} self-attention operators with skip connections at each layer. Moreover, we show that each layer performs highly efficient denoising: it improves the signal-to-noise ratio of token representations \textit{at a linear rate} with respect to the number of layers. Despite its simplicity, extensive experiments on vision and language tasks demonstrate that such a transformer achieves performance close to that of standard transformer architectures such as GPT-2 and CRATE.
Styl3R: Instant 3D Stylized Reconstruction for Arbitrary Scenes and Styles
May 27, 2025Stylizing 3D scenes instantly while maintaining multi-view consistency and faithfully resembling a style image remains a significant challenge. Current state-of-the-art 3D stylization methods typically involve computationally intensive test-time optimization to transfer artistic features into a pretrained 3D representation, often requiring dense posed input images. In contrast, leveraging recent advances in feed-forward reconstruction models, we demonstrate a novel approach to achieve direct 3D stylization in less than a second using unposed sparse-view scene images and an arbitrary style image. To address the inherent decoupling between reconstruction and stylization, we introduce a branched architecture that separates structure modeling and appearance shading, effectively preventing stylistic transfer from distorting the underlying 3D scene structure. Furthermore, we adapt an identity loss to facilitate pre-training our stylization model through the novel view synthesis task. This strategy also allows our model to retain its original reconstruction capabilities while being fine-tuned for stylization. Comprehensive evaluations, using both in-domain and out-of-domain datasets, demonstrate that our approach produces high-quality stylized 3D content that achieve a superior blend of style and scene appearance, while also outperforming existing methods in terms of multi-view consistency and efficiency.
Understanding Generalization in Diffusion Models via Probability Flow Distance
May 26, 2025Diffusion models have emerged as a powerful class of generative models, capable of producing high-quality samples that generalize beyond the training data. However, evaluating this generalization remains challenging: theoretical metrics are often impractical for high-dimensional data, while no practical metrics rigorously measure generalization. In this work, we bridge this gap by introducing probability flow distance ($\texttt{PFD}$), a theoretically grounded and computationally efficient metric to measure distributional generalization. Specifically, $\texttt{PFD}$ quantifies the distance between distributions by comparing their noise-to-data mappings induced by the probability flow ODE. Moreover, by using $\texttt{PFD}$ under a teacher-student evaluation protocol, we empirically uncover several key generalization behaviors in diffusion models, including: (1) scaling behavior from memorization to generalization, (2) early learning and double descent training dynamics, and (3) bias-variance decomposition. Beyond these insights, our work lays a foundation for future empirical and theoretical studies on generalization in diffusion models.
SLearnLLM: A Self-Learning Framework for Efficient Domain-Specific Adaptation of Large Language Models
May 23, 2025



When using supervised fine-tuning (SFT) to adapt large language models (LLMs) to specific domains, a significant challenge arises: should we use the entire SFT dataset for fine-tuning? Common practice often involves fine-tuning directly on the entire dataset due to limited information on the LLM's past training data. However, if the SFT dataset largely overlaps with the model's existing knowledge, the performance gains are minimal, leading to wasted computational resources. Identifying the unknown knowledge within the SFT dataset and using it to fine-tune the model could substantially improve the training efficiency. To address this challenge, we propose a self-learning framework for LLMs inspired by human learning pattern. This framework takes a fine-tuning (SFT) dataset in a specific domain as input. First, the LLMs answer the questions in the SFT dataset. The LLMs then objectively grade the responses and filter out the incorrectly answered QA pairs. Finally, we fine-tune the LLMs based on this filtered QA set. Experimental results in the fields of agriculture and medicine demonstrate that our method substantially reduces training time while achieving comparable improvements to those attained with full dataset fine-tuning. By concentrating on the unknown knowledge within the SFT dataset, our approach enhances the efficiency of fine-tuning LLMs.
Experimental robustness benchmark of quantum neural network on a superconducting quantum processor
May 22, 2025Quantum machine learning (QML) models, like their classical counterparts, are vulnerable to adversarial attacks, hindering their secure deployment. Here, we report the first systematic experimental robustness benchmark for 20-qubit quantum neural network (QNN) classifiers executed on a superconducting processor. Our benchmarking framework features an efficient adversarial attack algorithm designed for QNNs, enabling quantitative characterization of adversarial robustness and robustness bounds. From our analysis, we verify that adversarial training reduces sensitivity to targeted perturbations by regularizing input gradients, significantly enhancing QNN's robustness. Additionally, our analysis reveals that QNNs exhibit superior adversarial robustness compared to classical neural networks, an advantage attributed to inherent quantum noise. Furthermore, the empirical upper bound extracted from our attack experiments shows a minimal deviation ($3 \times 10^{-3}$) from the theoretical lower bound, providing strong experimental confirmation of the attack's effectiveness and the tightness of fidelity-based robustness bounds. This work establishes a critical experimental framework for assessing and improving quantum adversarial robustness, paving the way for secure and reliable QML applications.
LyapLock: Bounded Knowledge Preservation in Sequential Large Language Model Editing
May 21, 2025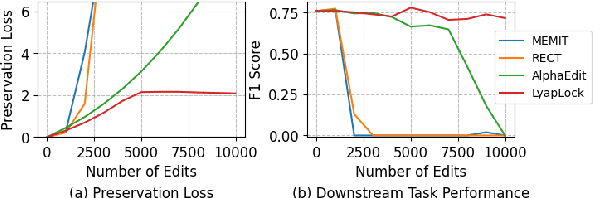
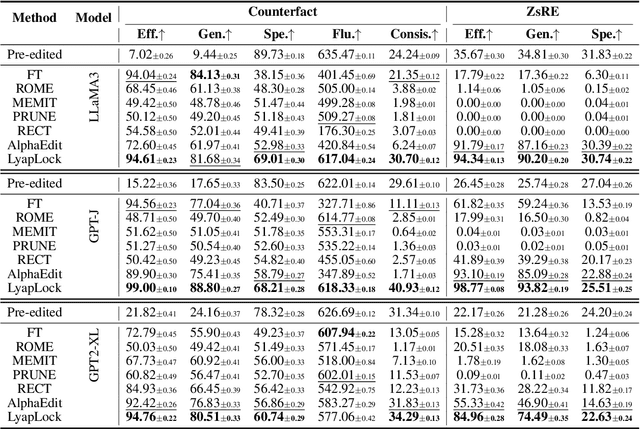
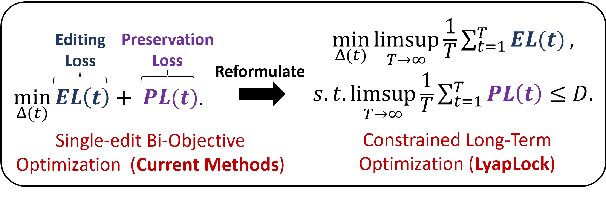
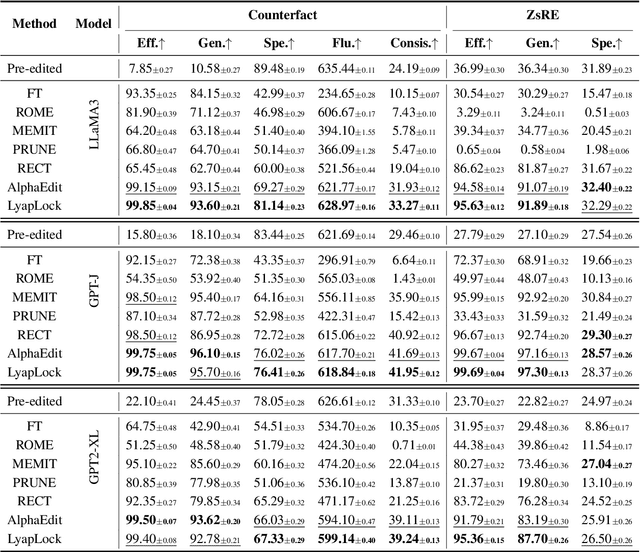
Large Language Models often contain factually incorrect or outdated knowledge, giving rise to model editing methods for precise knowledge updates. However, current mainstream locate-then-edit approaches exhibit a progressive performance decline during sequential editing, due to inadequate mechanisms for long-term knowledge preservation. To tackle this, we model the sequential editing as a constrained stochastic programming. Given the challenges posed by the cumulative preservation error constraint and the gradually revealed editing tasks, \textbf{LyapLock} is proposed. It integrates queuing theory and Lyapunov optimization to decompose the long-term constrained programming into tractable stepwise subproblems for efficient solving. This is the first model editing framework with rigorous theoretical guarantees, achieving asymptotic optimal editing performance while meeting the constraints of long-term knowledge preservation. Experimental results show that our framework scales sequential editing capacity to over 10,000 edits while stabilizing general capabilities and boosting average editing efficacy by 11.89\% over SOTA baselines. Furthermore, it can be leveraged to enhance the performance of baseline methods. Our code is released on https://github.com/caskcsg/LyapLock.