 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreaking the Quality-Privacy Tradeoff in Tabular Data Generation via In-Context Learning
May 06, 2026Tabular data synthesis aims to generate high-quality data while preserving privacy. However, we find that existing tabular generative models exhibit a clear tradeoff in the small-data regime: improving data quality typically comes at the cost of increased memorization of training samples, thereby weakening privacy protection. This tradeoff arises because small training sets make it difficult for dataset-specific generative models to distinguish generalizable structure from sample-specific patterns. To address this, we propose DiffICL, which formulates tabular data generation as an in-context learning problem. Instead of fitting each dataset from scratch,DiffICL leverages pretrained structural priors learned from a large collection of datasets, enabling it to infer data distributions from limited context rather than memorizing individual samples. We evaluate DiffICL on 14 real-world datasets. Results show that DiffICL improves both data quality and privacy, and generate synthetic data that provides effective data augmentation. Our findings suggest that the quality-privacy tradeoff can be improved through better training paradigms.
A Knowledge-Informed Pretrained Model for Causal Discovery
Mar 21, 2026Causal discovery has been widely studied, yet many existing methods rely on strong assumptions or fall into two extremes: either depending on costly interventional signals or partial ground truth as strong priors, or adopting purely data driven paradigms with limited guidance, which hinders practical deployment. Motivated by real-world scenarios where only coarse domain knowledge is available, we propose a knowledge-informed pretrained model for causal discovery that integrates weak prior knowledge as a principled middle ground. Our model adopts a dual source encoder-decoder architecture to process observational data in a knowledge-informed way. We design a diverse pretraining dataset and a curriculum learning strategy that smoothly adapts the model to varying prior strengths across mechanisms, graph densities, and variable scales. Extensive experiments on in-distribution, out-of distribution, and real-world datasets demonstrate consistent improvements over existing baselines, with strong robustness and practical applicability.
TFMLinker: Universal Link Predictor by Graph In-Context Learning with Tabular Foundation Models
Feb 09, 2026Link prediction is a fundamental task in graph machine learning with widespread applications such as recommendation systems, drug discovery, knowledge graphs, etc. In the foundation model era, how to develop universal link prediction methods across datasets and domains becomes a key problem, with some initial attempts adopting Graph Foundation Models utilizing Graph Neural Networks and Large Language Models. However, the existing methods face notable limitations, including limited pre-training scale or heavy reliance on textual information. Motivated by the success of tabular foundation models (TFMs) in achieving universal prediction across diverse tabular datasets, we explore an alternative approach by TFMs, which are pre-trained on diverse synthetic datasets sampled from structural causal models and support strong in-context learning independent of textual attributes. Nevertheless, adapting TFMs for link prediction faces severe technical challenges such as how to obtain the necessary context and capture link-centric topological information. To solve these challenges, we propose TFMLinker (Tabular Foundation Model for Link Predictor), aiming to leverage the in-context learning capabilities of TFMs to perform link prediction across diverse graphs without requiring dataset-specific fine-tuning. Specifically, we first develop a prototype-augmented local-global context module to construct context that captures both graph-specific and cross-graph transferable patterns. Next, we design a universal topology-aware link encoder to capture link-centric topological information and generate link representations as inputs for the TFM. Finally, we employ the TFM to predict link existence through in-context learning. Experiments on 6 graph benchmarks across diverse domains demonstrate the superiority of our method over state-of-the-art baselines without requiring dataset-specific finetuning.
Generating Risky Samples with Conformity Constraints via Diffusion Models
Dec 21, 2025Although neural networks achieve promising performance in many tasks, they may still fail when encountering some examples and bring about risks to applications. To discover risky samples, previous literature attempts to search for patterns of risky samples within existing datasets or inject perturbation into them. Yet in this way the diversity of risky samples is limited by the coverage of existing datasets. To overcome this limitation, recent works adopt diffusion models to produce new risky samples beyond the coverage of existing datasets. However, these methods struggle in the conformity between generated samples and expected categories, which could introduce label noise and severely limit their effectiveness in applications. To address this issue, we propose RiskyDiff that incorporates the embeddings of both texts and images as implicit constraints of category conformity. We also design a conformity score to further explicitly strengthen the category conformity, as well as introduce the mechanisms of embedding screening and risky gradient guidance to boost the risk of generated samples. Extensive experiments reveal that RiskyDiff greatly outperforms existing methods in terms of the degree of risk, generation quality, and conformity with conditioned categories. We also empirically show the generalization ability of the models can be enhanced by augmenting training data with generated samples of high conformity.
ODP-Bench: Benchmarking Out-of-Distribution Performance Prediction
Oct 31, 2025Recently, there has been gradually more attention paid to Out-of-Distribution (OOD) performance prediction, whose goal is to predict the performance of trained models on unlabeled OOD test datasets, so that we could better leverage and deploy off-the-shelf trained models in risk-sensitive scenarios. Although progress has been made in this area, evaluation protocols in previous literature are inconsistent, and most works cover only a limited number of real-world OOD datasets and types of distribution shifts. To provide convenient and fair comparisons for various algorithms, we propose Out-of-Distribution Performance Prediction Benchmark (ODP-Bench), a comprehensive benchmark that includes most commonly used OOD datasets and existing practical performance prediction algorithms. We provide our trained models as a testbench for future researchers, thus guaranteeing the consistency of comparison and avoiding the burden of repeating the model training process. Furthermore, we also conduct in-depth experimental analyses to better understand their capability boundary.
LimiX: Unleashing Structured-Data Modeling Capability for Generalist Intelligence
Sep 03, 2025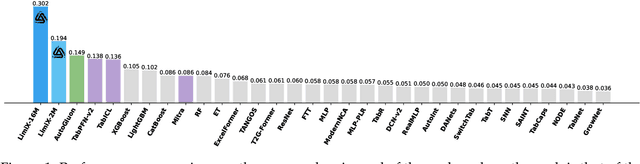
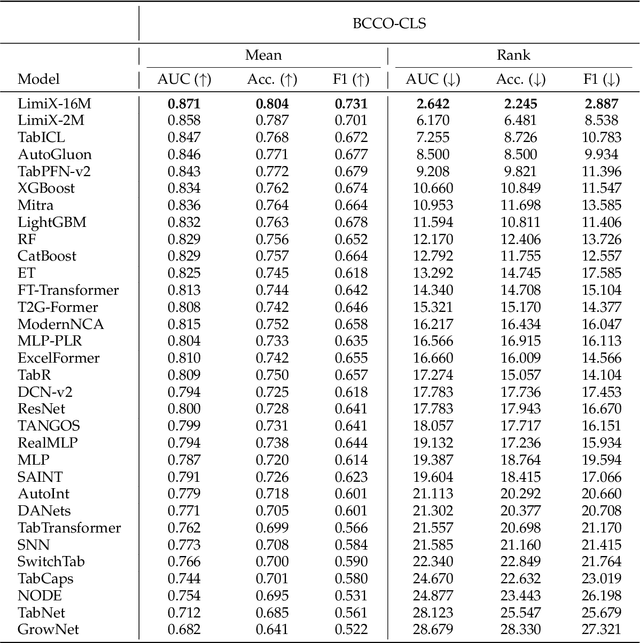
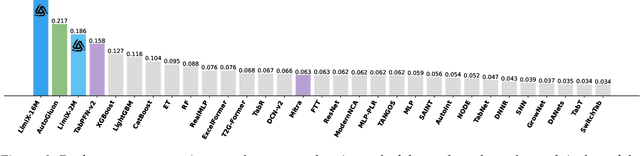
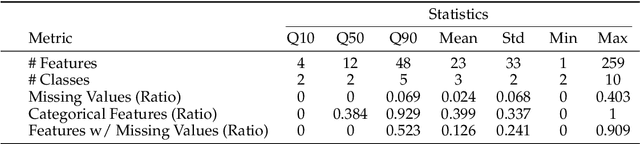
We argue that progress toward general intelligence requires complementary foundation models grounded in language, the physical world, and structured data. This report presents LimiX, the first installment of our large structured-data models (LDMs). LimiX treats structured data as a joint distribution over variables and missingness, thus capable of addressing a wide range of tabular tasks through query-based conditional prediction via a single model. LimiX is pretrained using masked joint-distribution modeling with an episodic, context-conditional objective, where the model predicts for query subsets conditioned on dataset-specific contexts, supporting rapid, training-free adaptation at inference. We evaluate LimiX across 10 large structured-data benchmarks with broad regimes of sample size, feature dimensionality, class number, categorical-to-numerical feature ratio, missingness, and sample-to-feature ratios. With a single model and a unified interface, LimiX consistently surpasses strong baselines including gradient-boosting trees, deep tabular networks, recent tabular foundation models, and automated ensembles, as shown in Figure 1 and Figure 2. The superiority holds across a wide range of tasks, such as classification, regression, missing value imputation, and data generation, often by substantial margins, while avoiding task-specific architectures or bespoke training per task. All LimiX models are publicly accessible under Apache 2.0.
COUNTS: Benchmarking Object Detectors and Multimodal Large Language Models under Distribution Shifts
Apr 14, 2025Current object detectors often suffer significant perfor-mance degradation in real-world applications when encountering distributional shifts. Consequently, the out-of-distribution (OOD) generalization capability of object detectors has garnered increasing attention from researchers. Despite this growing interest, there remains a lack of a large-scale, comprehensive dataset and evaluation benchmark with fine-grained annotations tailored to assess the OOD generalization on more intricate tasks like object detection and grounding. To address this gap, we introduce COUNTS, a large-scale OOD dataset with object-level annotations. COUNTS encompasses 14 natural distributional shifts, over 222K samples, and more than 1,196K labeled bounding boxes. Leveraging COUNTS, we introduce two novel benchmarks: O(OD)2 and OODG. O(OD)2 is designed to comprehensively evaluate the OOD generalization capabilities of object detectors by utilizing controlled distribution shifts between training and testing data. OODG, on the other hand, aims to assess the OOD generalization of grounding abilities in multimodal large language models (MLLMs). Our findings reveal that, while large models and extensive pre-training data substantially en hance performance in in-distribution (IID) scenarios, significant limitations and opportunities for improvement persist in OOD contexts for both object detectors and MLLMs. In visual grounding tasks, even the advanced GPT-4o and Gemini-1.5 only achieve 56.7% and 28.0% accuracy, respectively. We hope COUNTS facilitates advancements in the development and assessment of robust object detectors and MLLMs capable of maintaining high performance under distributional shifts.
Understanding the Generalization of In-Context Learning in Transformers: An Empirical Study
Mar 19, 2025Large language models (LLMs) like GPT-4 and LLaMA-3 utilize the powerful in-context learning (ICL) capability of Transformer architecture to learn on the fly from limited examples. While ICL underpins many LLM applications, its full potential remains hindered by a limited understanding of its generalization boundaries and vulnerabilities. We present a systematic investigation of transformers' generalization capability with ICL relative to training data coverage by defining a task-centric framework along three dimensions: inter-problem, intra-problem, and intra-task generalization. Through extensive simulation and real-world experiments, encompassing tasks such as function fitting, API calling, and translation, we find that transformers lack inter-problem generalization with ICL, but excel in intra-task and intra-problem generalization. When the training data includes a greater variety of mixed tasks, it significantly enhances the generalization ability of ICL on unseen tasks and even on known simple tasks. This guides us in designing training data to maximize the diversity of tasks covered and to combine different tasks whenever possible, rather than solely focusing on the target task for testing.
Error Slice Discovery via Manifold Compactness
Jan 31, 2025



Despite the great performance of deep learning models in many areas, they still make mistakes and underperform on certain subsets of data, i.e. error slices. Given a trained model, it is important to identify its semantically coherent error slices that are easy to interpret, which is referred to as the error slice discovery problem. However, there is no proper metric of slice coherence without relying on extra information like predefined slice labels. Current evaluation of slice coherence requires access to predefined slices formulated by metadata like attributes or subclasses. Its validity heavily relies on the quality and abundance of metadata, where some possible patterns could be ignored. Besides, current algorithms cannot directly incorporate the constraint of coherence into their optimization objective due to the absence of an explicit coherence metric, which could potentially hinder their effectiveness. In this paper, we propose manifold compactness, a coherence metric without reliance on extra information by incorporating the data geometry property into its design, and experiments on typical datasets empirically validate the rationality of the metric. Then we develop Manifold Compactness based error Slice Discovery (MCSD), a novel algorithm that directly treats risk and coherence as the optimization objective, and is flexible to be applied to models of various tasks. Extensive experiments on the benchmark and case studies on other typical datasets demonstrate the superiority of MCSD.
PPA-Game: Characterizing and Learning Competitive Dynamics Among Online Content Creators
Mar 22, 2024



We introduce the Proportional Payoff Allocation Game (PPA-Game) to model how agents, akin to content creators on platforms like YouTube and TikTok, compete for divisible resources and consumers' attention. Payoffs are allocated to agents based on heterogeneous weights, reflecting the diversity in content quality among creators. Our analysis reveals that although a pure Nash equilibrium (PNE) is not guaranteed in every scenario, it is commonly observed, with its absence being rare in our simulations. Beyond analyzing static payoffs, we further discuss the agents' online learning about resource payoffs by integrating a multi-player multi-armed bandit framework. We propose an online algorithm facilitating each agent's maximization of cumulative payoffs over $T$ rounds. Theoretically, we establish that the regret of any agent is bounded by $O(\log^{1 + \eta} T)$ for any $\eta > 0$. Empirical results further validate the effectiveness of our approach.