 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Reliable Context-Aware and Temporal Planning Framework for Autonomous Driving
Jul 06, 2026Safe operation of autonomous vehicles in dense urban traffic depends on perception and planning that remain reliable when onboard sensing is degraded. In real driving conditions, camera observations are frequently corrupted by occlusion, motion blur, illumination change, and sensor noise, and when such degraded observations are aggregated indiscriminately over time, trajectory planning becomes unstable and collision risk rises for both the ego vehicle and surrounding road users. Recent Bird's-Eye-View (BEV) approaches unify perception and planning through a shared spatial representation, but most fuse temporal information across frames without assessing the reliability of the underlying observations. We present a Reliable Context-Aware and Temporal Planning framework for Autonomous Driving (RCT-AD) that explicitly models feature quality and temporal consistency to support safer, more consistent planning. A Reliable Context Awareness module scores per-frame reliability and selectively retains trustworthy features through a quality-gated First-In-Last-Out (FILO) memory mechanism, reconstructing degraded observations from reliable historical context so that corrupted inputs do not destabilize the scene representation. A Temporal Trajectory Planner captures long-term dependencies and multi-agent interactions to produce smoother, safety-aware trajectories, while a joint detection-and-segmentation head injects semantic and motion cues into the shared BEV space to strengthen scene understanding. Experiments on the nuScenes autonomous driving benchmark show that RCT-AD improves perception accuracy, motion prediction, and planning robustness over recent end-to-end baselines, achieving 61.5 nuScenes Detection Score, 52.9 mean Average Precision, and 52.3 mean Intersection over Union, while maintaining competitive computational efficiency suitable for real-time deployment.
MoG: Mixture of Experts for Graph-based Retrieval-Augmented Generation
May 29, 2026Retrieval-augmented generation is intensively studied to ground large language models on external evidence. However, retrieving from a unified knowledge base could inevitably introduce irrelevant information that may mislead generation for complex reasoning. Inspired by the conditional computation of mixture of experts (MoE), where a router sparsely selects specialized experts alongside shared ones for each input, we propose \textbf{M}ixture \textbf{o}f experts for \textbf{G}raph-based Retrieval-Augmented Generation, i.e., \textbf{MoG}. It organizes knowledge into two core components: (i) diverse, always-accessible hub graphs that encode semantically and structurally central knowledge and provide contextual clues for expert activation, and (ii) sparsely activated expert graphs that contain domain-specific evidence. MoG first accesses hub graphs to identify general evidence and derive contextual clues. Then, a topology-aware router dynamically activates a limited set of expert graphs conditioned on the query, thereby confining retrieval to a focused evidence subspace. Extensive experiments on challenging benchmarks show that MoG consistently outperforms strong baselines, with over 20\% relative improvement on MuSiQue. Our code is available in https://github.com/DEEP-PolyU/MoG.
Toward Native Multimodal Modeling: A Roadmap
May 25, 2026Multimodal modeling represents a vital step from modality-agnostic reasoning toward world modeling. While early approaches predominantly rely on late-fusion that assembles encoders and frozen language backbones with output heads, recent efforts have shifted the paradigm toward native multimodal modeling (NMM) with the intrinsic integration of modalities for superior multimodal performance. Despite its potential, the design space of native architectures remains insufficiently defined. In this paper, we present the community with a formalized roadmap for this transition. Specifically, we formally define the architectural nativity, distinguishing mid-fusion and early-fusion from non-native paradigms. We further organize the existing native models through the lens of input-output duality into three categories: (i) Multi-to-Text for cross-modal comprehension with text-only output; (ii) Multi-to-Target for scenario-oriented generation, e.g., image, audio and video generation, and (iii) Multi-to-Multi for unified modeling with symmetric input-output. We deliver a comprehensive and industrial-grade investigation into the transition toward the definitive NMM framework, where understanding and generation seamlessly coexist within a unified transformer paradigm. We systematically unpack the end-to-end pipeline from industrial perspectives from architectural coordination, massive data curation, to full-stack training recipes, inference & deployment, and the comprehensive evaluation for truly native modeling.
JMed48k: A Multi-Profession Japanese Medical Licensing Benchmark for Vision-Language Model Evaluation
May 21, 2026We introduce JMed48k, a multi-profession Japanese healthcare licensing benchmark for evaluating vision-language models. Built from official PDF materials released by the Japanese Ministry of Health, Labour and Welfare, JMed48k contains 48,862 exam questions and 20,142 images from 11 national licensing examinations between 2005 and 2025, with visual content annotated under an 8-type taxonomy. From this corpus, we derive JMed48k-Eval, a recent five-year evaluation subset with 12,484 scored questions, including 9,905 text-only questions and 2,579 questions with images. We evaluate 21 proprietary, open-source, and medical-specific models, reporting text-only and with-image performance separately. Because these subsets contain different questions, we further introduce a paired image-removal audit that evaluates questions with images before and after removing visual content to explore four answer-transition states. The audit shows that proprietary and open source models gain substantially from images, whereas medical-specific systems show limited observable use of visual evidence, with many correct answers persisting after image removal. Even among proprietary models, the net image-removal effect varies sevenfold across professions, from +5.7 points on Physician questions to +39.8 points on Public Health Nurse questions. We release JMed48k to support reproducible, profession-stratified evaluation of vision-language models in medical licensing settings.
Deep Tabular Research via Continual Experience-Driven Execution
Mar 12, 2026Large language models often struggle with complex long-horizon analytical tasks over unstructured tables, which typically feature hierarchical and bidirectional headers and non-canonical layouts. We formalize this challenge as Deep Tabular Research (DTR), requiring multi-step reasoning over interdependent table regions. To address DTR, we propose a novel agentic framework that treats tabular reasoning as a closed-loop decision-making process. We carefully design a coupled query and table comprehension for path decision making and operational execution. Specifically, (i) DTR first constructs a hierarchical meta graph to capture bidirectional semantics, mapping natural language queries into an operation-level search space; (ii) To navigate this space, we introduce an expectation-aware selection policy that prioritizes high-utility execution paths; (iii) Crucially, historical execution outcomes are synthesized into a siamese structured memory, i.e., parameterized updates and abstracted texts, enabling continual refinement. Extensive experiments on challenging unstructured tabular benchmarks verify the effectiveness and highlight the necessity of separating strategic planning from low-level execution for long-horizon tabular reasoning.
ErrorLLM: Modeling SQL Errors for Text-to-SQL Refinement
Mar 04, 2026Despite the remarkable performance of large language models (LLMs) in text-to-SQL (SQL generation), correctly producing SQL queries remains challenging during initial generation. The SQL refinement task is subsequently introduced to correct syntactic and semantic errors in generated SQL queries. However, existing paradigms face two major limitations: (i) self-debugging becomes increasingly ineffective as modern LLMs rarely produce explicit execution errors that can trigger debugging signals; (ii) self-correction exhibits low detection precision due to the lack of explicit error modeling grounded in the question and schema, and suffers from severe hallucination that frequently corrupts correct SQLs. In this paper, we propose ErrorLLM, a framework that explicitly models text-to-SQL Errors within a dedicated LLM for text-to-SQL refinement. Specifically, we represent the user question and database schema as structural features, employ static detection to identify execution failures and surface mismatches, and extend ErrorLLM's semantic space with dedicated error tokens that capture categorized implicit semantic error types. Through a well-designed training strategy, we explicitly model these errors with structural representations, enabling the LLM to detect complex implicit errors by predicting dedicated error tokens. Guided by the detected errors, we perform error-guided refinement on the SQL structure by prompting LLMs. Extensive experiments demonstrate that ErrorLLM achieves the most significant improvements over backbone initial generation. Further analysis reveals that detection quality directly determines refinement effectiveness, and ErrorLLM addresses both sides by high detection F1 score while maintain refinement effectiveness.
Graph-based Agent Memory: Taxonomy, Techniques, and Applications
Feb 05, 2026Memory emerges as the core module in the Large Language Model (LLM)-based agents for long-horizon complex tasks (e.g., multi-turn dialogue, game playing, scientific discovery), where memory can enable knowledge accumulation, iterative reasoning and self-evolution. Among diverse paradigms, graph stands out as a powerful structure for agent memory due to the intrinsic capabilities to model relational dependencies, organize hierarchical information, and support efficient retrieval. This survey presents a comprehensive review of agent memory from the graph-based perspective. First, we introduce a taxonomy of agent memory, including short-term vs. long-term memory, knowledge vs. experience memory, non-structural vs. structural memory, with an implementation view of graph-based memory. Second, according to the life cycle of agent memory, we systematically analyze the key techniques in graph-based agent memory, covering memory extraction for transforming the data into the contents, storage for organizing the data efficiently, retrieval for retrieving the relevant contents from memory to support reasoning, and evolution for updating the contents in the memory. Third, we summarize the open-sourced libraries and benchmarks that support the development and evaluation of self-evolving agent memory. We also explore diverse application scenarios. Finally, we identify critical challenges and future research directions. This survey aims to offer actionable insights to advance the development of more efficient and reliable graph-based agent memory systems. All the related resources, including research papers, open-source data, and projects, are collected for the community in https://github.com/DEEP-PolyU/Awesome-GraphMemory.
T2VAttack: Adversarial Attack on Text-to-Video Diffusion Models
Dec 30, 2025The rapid evolution of Text-to-Video (T2V) diffusion models has driven remarkable advancements in generating high-quality, temporally coherent videos from natural language descriptions. Despite these achievements, their vulnerability to adversarial attacks remains largely unexplored. In this paper, we introduce T2VAttack, a comprehensive study of adversarial attacks on T2V diffusion models from both semantic and temporal perspectives. Considering the inherently dynamic nature of video data, we propose two distinct attack objectives: a semantic objective to evaluate video-text alignment and a temporal objective to assess the temporal dynamics. To achieve an effective and efficient attack process, we propose two adversarial attack methods: (i) T2VAttack-S, which identifies semantically or temporally critical words in prompts and replaces them with synonyms via greedy search, and (ii) T2VAttack-I, which iteratively inserts optimized words with minimal perturbation to the prompt. By combining these objectives and strategies, we conduct a comprehensive evaluation on the adversarial robustness of several state-of-the-art T2V models, including ModelScope, CogVideoX, Open-Sora, and HunyuanVideo. Our experiments reveal that even minor prompt modifications, such as the substitution or insertion of a single word, can cause substantial degradation in semantic fidelity and temporal dynamics, highlighting critical vulnerabilities in current T2V diffusion models.
SegMo: Segment-aligned Text to 3D Human Motion Generation
Dec 24, 2025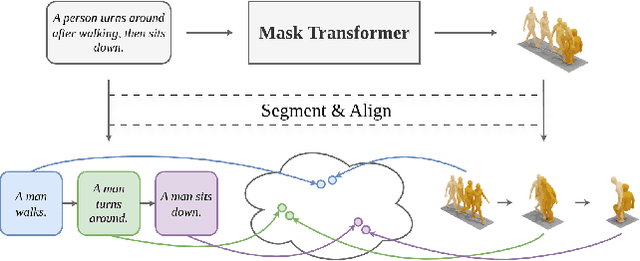
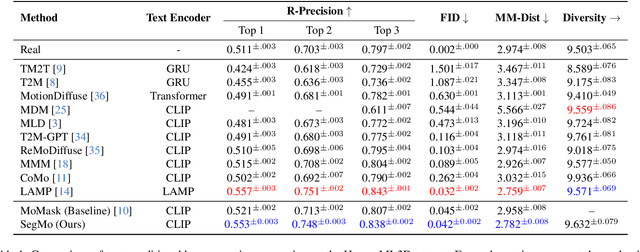
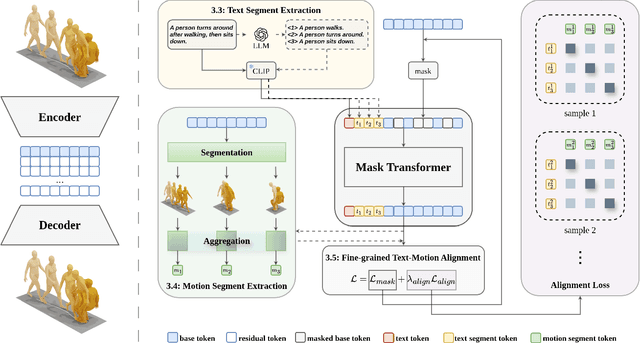
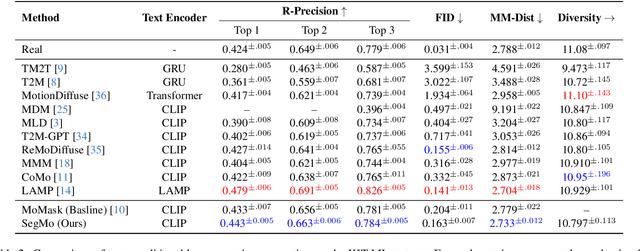
Generating 3D human motions from textual descriptions is an important research problem with broad applications in video games, virtual reality, and augmented reality. Recent methods align the textual description with human motion at the sequence level, neglecting the internal semantic structure of modalities. However, both motion descriptions and motion sequences can be naturally decomposed into smaller and semantically coherent segments, which can serve as atomic alignment units to achieve finer-grained correspondence. Motivated by this, we propose SegMo, a novel Segment-aligned text-conditioned human Motion generation framework to achieve fine-grained text-motion alignment. Our framework consists of three modules: (1) Text Segment Extraction, which decomposes complex textual descriptions into temporally ordered phrases, each representing a simple atomic action; (2) Motion Segment Extraction, which partitions complete motion sequences into corresponding motion segments; and (3) Fine-grained Text-Motion Alignment, which aligns text and motion segments with contrastive learning. Extensive experiments demonstrate that SegMo improves the strong baseline on two widely used datasets, achieving an improved TOP 1 score of 0.553 on the HumanML3D test set. Moreover, thanks to the learned shared embedding space for text and motion segments, SegMo can also be applied to retrieval-style tasks such as motion grounding and motion-to-text retrieval.
Seed-Prover 1.5: Mastering Undergraduate-Level Theorem Proving via Learning from Experience
Dec 19, 2025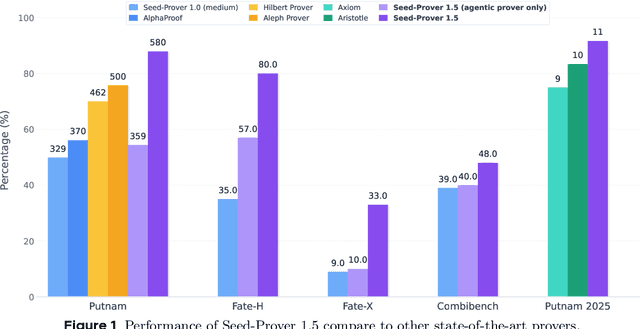

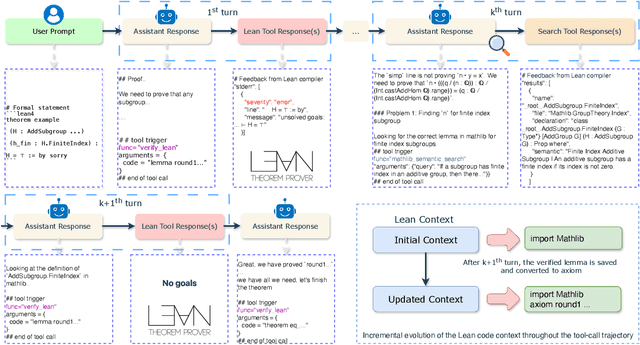

Large language models have recently made significant progress to generate rigorous mathematical proofs. In contrast, utilizing LLMs for theorem proving in formal languages (such as Lean) remains challenging and computationally expensive, particularly when addressing problems at the undergraduate level and beyond. In this work, we present \textbf{Seed-Prover 1.5}, a formal theorem-proving model trained via large-scale agentic reinforcement learning, alongside an efficient test-time scaling (TTS) workflow. Through extensive interactions with Lean and other tools, the model continuously accumulates experience during the RL process, substantially enhancing the capability and efficiency of formal theorem proving. Furthermore, leveraging recent advancements in natural language proving, our TTS workflow efficiently bridges the gap between natural and formal languages. Compared to state-of-the-art methods, Seed-Prover 1.5 achieves superior performance with a smaller compute budget. It solves \textbf{88\% of PutnamBench} (undergraduate-level), \textbf{80\% of Fate-H} (graduate-level), and \textbf{33\% of Fate-X} (PhD-level) problems. Notably, using our system, we solved \textbf{11 out of 12 problems} from Putnam 2025 within 9 hours. Our findings suggest that scaling learning from experience, driven by high-quality formal feedback, holds immense potential for the future of formal mathematical reasoning.