 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMAE: A Massive Multitask Audio Editing Benchmark
Jun 05, 2026We introduce MMAE, a Massive Multitask Audio Editing benchmark, serving as the first comprehensive evaluation testbed designed for general-purpose instruction-based audio editing. Spurred by the shift toward intelligent creation, interactive editing has rapidly expanded from visual domains, pioneered by models like Nano-banana 2 for images and Gemini-Omni for video, into audio. However, the current evaluation infrastructure lags severely, remaining highly fragmented and restricted to specific subdomains or basic operations. Unlike existing benchmarks that are limited in scope, MMAE extends to a broad spectrum of real-world scenarios, encompassing 7 distinct audio modalities, including sound, speech, music, and their mixtures. Furthermore, we establish a comprehensive taxonomy spanning 6 levels of task complexity, from basic modifications to multi-hop reasoning and multi-round editing, 2 levels of granularity, and 8 distinct operation types. Meticulously curated through human-agent collaboration, MMAE comprises 2,000 high-fidelity samples paired with a pioneering rubric-based evaluation framework. By decomposing free-form tasks into 17,741 verifiable criteria, this robust rubric-based paradigm enables a precise, multi-dimensional assessment of both instruction following and context consistency. Our extensive evaluation of leading models reveals that current systems remain far from achieving reliable edits. Strikingly, the Exact Match Rate (EMR) consistently falls below 5% and plummets to an absolute 0% in complex, mixed-modality tasks, exposing critical bottlenecks in precise execution and structural robustness. We hope MMAE will serve as a catalyst for future advances in the intelligent creation community, providing a clear diagnostic roadmap and establishing a standardized, long-lasting evaluation paradigm for next-generation audio editing systems.
AnyAudio-Judge: A Dynamic Rubric-Based Benchmark and Evaluator for Audio Instruction Following
Jun 02, 2026The rapid advancement of instruction-guided audio generation has highlighted the critical need for robust alignment evaluation. Current automated evaluation methods heavily rely on holistic scoring from general-purpose large language models, which struggle to decouple complex instructions, lack interpretability, and fail to capture fine-grained attribute mismatches. To address this, we introduce a novel dynamic rubric-based evaluation paradigm that adaptively decomposes complex audio captions into a variable number of independent, verifiable binary rubric items. To rigorously benchmark this capability, we propose the AnyAudio-Judge Bench, a comprehensive, bilingual benchmark comprising 7,920 meticulously curated samples across four diverse audio domains (speech, sound, music, and mixed), featuring deliberately constructed hard negatives. Furthermore, we construct a large-scale corpus of 105K samples with explicit Chain-of-Thought (CoT) rationales to train our dedicated evaluator, the AnyAudio-Judge model. By employing a training pipeline that combines Supervised Fine-Tuning (SFT) and Group Relative Policy Optimization (GRPO), our model successfully aligns its reasoning paths with the rubric-based scoring mechanism. Extensive experiments demonstrate that AnyAudio-Judge not only significantly enhances zero-shot alignment detection compared to state-of-the-art baselines, but also provides precise and interpretable reward signals that substantially improve instruction alignment in downstream reinforcement learning for audio generation.
WavCube: Unifying Speech Representation for Understanding and Generation via Semantic-Acoustic Joint Modeling
May 07, 2026Integrating speech understanding and generation is a pivotal step toward building unified speech models. However, the different representations required for these two tasks currently pose significant compatibility challenges. Typically, semantics-oriented features are learned from self-supervised learning (SSL), and acoustic-oriented features from reconstruction. Such fragmented representations hinder the realization of truly unified speech systems. We present WavCube, a compact continuous latent derived from an SSL speech encoder that simultaneously supports speech understanding, reconstruction, and generation. WavCube employs a two-stage training scheme. Stage 1 trains a semantic bottleneck to filter off-manifold redundancy that makes raw SSL features intractable for diffusion. Stage 2 injects fine-grained acoustic details via end-to-end reconstruction, while a semantic anchoring loss ensures the representation remains grounded within its original semantic manifold. Comprehensive experiments show that WavCube closely approaches WavLM performance on SUPERB despite an 8x dimensional compression, attains reconstruction quality on par with existing acoustic representations, delivers state-of-the-art zero-shot TTS performance with markedly faster training convergence, and excels in speech enhancement, separation, and voice conversion tasks on the SUPERB-SG benchmark. Systematic ablations reveal that WavCube's two-stage recipe resolves two intrinsic flaws of SSL features for generative modeling, paving the way for future unified speech systems. Codes and checkpoints are available at https://github.com/yanghaha0908/WavCube.
HumanScore: Benchmarking Human Motions in Generated Videos
Apr 22, 2026Recent advances in model architectures, compute, and data scale have driven rapid progress in video generation, producing increasingly realistic content. Yet, no prior method systematically measures how faithfully these systems render human bodies and motion dynamics. In this paper, we present HumanScore, a systematic framework to evaluate the quality of human motions in AI-generated videos. HumanScore defines six interpretable metrics spanning kinematic plausibility, temporal stability, and biomechanical consistency, enabling fine-grained diagnosis beyond visual realism alone. Through carefully designed prompts, we elicit a diverse set of movements at varying intensities and evaluate videos generated by thirteen state-of-the-art models. Our analysis reveals consistent gaps between perceptual plausibility and motion biomechanical fidelity, identifies recurrent failure modes (e.g., temporal jitter, anatomically implausible poses, and motion drift), and produces robust model rankings from quantitative and physically meaningful criteria.
Parallel OctoMapping: A Scalable Framework for Enhanced Path Planning in Autonomous Navigation
Mar 23, 2026Mapping is essential in robotics and autonomous systems because it provides the spatial foundation for path planning. Efficient mapping enables planning algorithms to generate reliable paths while ensuring safety and adapting in real time to complex environments. Fixed-resolution mapping methods often produce overly conservative obstacle representations that lead to suboptimal paths or planning failures in cluttered scenes. To address this issue, we introduce Parallel OctoMapping (POMP), an efficient OctoMap-based mapping technique that maximizes available free space and supports multi-threaded computation. To the best of our knowledge, POMP is the first method that, at a fixed occupancy-grid resolution, refines the representation of free space while preserving map fidelity and compatibility with existing search-based planners. It can therefore be integrated into existing planning pipelines, yielding higher pathfinding success rates and shorter path lengths, especially in cluttered environments, while substantially improving computational efficiency.
Think Deep, Not Just Long: Measuring LLM Reasoning Effort via Deep-Thinking Tokens
Feb 13, 2026Large language models (LLMs) have demonstrated impressive reasoning capabilities by scaling test-time compute via long Chain-of-Thought (CoT). However, recent findings suggest that raw token counts are unreliable proxies for reasoning quality: increased generation length does not consistently correlate with accuracy and may instead signal "overthinking," leading to performance degradation. In this work, we quantify inference-time effort by identifying deep-thinking tokens -- tokens where internal predictions undergo significant revisions in deeper model layers prior to convergence. Across four challenging mathematical and scientific benchmarks (AIME 24/25, HMMT 25, and GPQA-diamond) and a diverse set of reasoning-focused models (GPT-OSS, DeepSeek-R1, and Qwen3), we show that deep-thinking ratio (the proportion of deep-thinking tokens in a generated sequence) exhibits a robust and consistently positive correlation with accuracy, substantially outperforming both length-based and confidence-based baselines. Leveraging this insight, we introduce Think@n, a test-time scaling strategy that prioritizes samples with high deep-thinking ratios. We demonstrate that Think@n matches or exceeds standard self-consistency performance while significantly reducing inference costs by enabling the early rejection of unpromising generations based on short prefixes.
LikeBench: Evaluating Subjective Likability in LLMs for Personalization
Dec 15, 2025A personalized LLM should remember user facts, apply them correctly, and adapt over time to provide responses that the user prefers. Existing LLM personalization benchmarks are largely centered on two axes: accurately recalling user information and accurately applying remembered information in downstream tasks. We argue that a third axis, likability, is both subjective and central to user experience, yet under-measured by current benchmarks. To measure likability holistically, we introduce LikeBench, a multi-session, dynamic evaluation framework that measures likability across multiple dimensions by how much an LLM can adapt over time to a user's preferences to provide more likable responses. In LikeBench, the LLMs engage in conversation with a simulated user and learn preferences only from the ongoing dialogue. As the interaction unfolds, models try to adapt to responses, and after each turn, they are evaluated for likability across seven dimensions by the same simulated user. To the best of our knowledge, we are the first to decompose likability into multiple diagnostic metrics: emotional adaptation, formality matching, knowledge adaptation, reference understanding, conversation length fit, humor fit, and callback, which makes it easier to pinpoint where a model falls short. To make the simulated user more realistic and discriminative, LikeBench uses fine-grained, psychologically grounded descriptive personas rather than the coarse high/low trait rating based personas used in prior work. Our benchmark shows that strong memory performance does not guarantee high likability: DeepSeek R1, with lower memory accuracy (86%, 17 facts/profile), outperformed Qwen3 by 28% on likability score despite Qwen3's higher memory accuracy (93%, 43 facts/profile). Even SOTA models like GPT-5 adapt well in short exchanges but show only limited robustness in longer, noisier interactions.
Not All Documents Are What You Need for Extracting Instruction Tuning Data
May 18, 2025Instruction tuning improves the performance of large language models (LLMs), but it heavily relies on high-quality training data. Recently, LLMs have been used to synthesize instruction data using seed question-answer (QA) pairs. However, these synthesized instructions often lack diversity and tend to be similar to the input seeds, limiting their applicability in real-world scenarios. To address this, we propose extracting instruction tuning data from web corpora that contain rich and diverse knowledge. A naive solution is to retrieve domain-specific documents and extract all QA pairs from them, but this faces two key challenges: (1) extracting all QA pairs using LLMs is prohibitively expensive, and (2) many extracted QA pairs may be irrelevant to the downstream tasks, potentially degrading model performance. To tackle these issues, we introduce EQUAL, an effective and scalable data extraction framework that iteratively alternates between document selection and high-quality QA pair extraction to enhance instruction tuning. EQUAL first clusters the document corpus based on embeddings derived from contrastive learning, then uses a multi-armed bandit strategy to efficiently identify clusters that are likely to contain valuable QA pairs. This iterative approach significantly reduces computational cost while boosting model performance. Experiments on AutoMathText and StackOverflow across four downstream tasks show that EQUAL reduces computational costs by 5-10x and improves accuracy by 2.5 percent on LLaMA-3.1-8B and Mistral-7B
Seed-ASR: Understanding Diverse Speech and Contexts with LLM-based Speech Recognition
Jul 05, 2024



Modern automatic speech recognition (ASR) model is required to accurately transcribe diverse speech signals (from different domains, languages, accents, etc) given the specific contextual information in various application scenarios. Classic end-to-end models fused with extra language models perform well, but mainly in data matching scenarios and are gradually approaching a bottleneck. In this work, we introduce Seed-ASR, a large language model (LLM) based speech recognition model. Seed-ASR is developed based on the framework of audio conditioned LLM (AcLLM), leveraging the capabilities of LLMs by inputting continuous speech representations together with contextual information into the LLM. Through stage-wise large-scale training and the elicitation of context-aware capabilities in LLM, Seed-ASR demonstrates significant improvement over end-to-end models on comprehensive evaluation sets, including multiple domains, accents/dialects and languages. Additionally, Seed-ASR can be further deployed to support specific needs in various scenarios without requiring extra language models. Compared to recently released large ASR models, Seed-ASR achieves 10%-40% reduction in word (or character, for Chinese) error rates on Chinese and English public test sets, further demonstrating its powerful performance.
video-SALMONN: Speech-Enhanced Audio-Visual Large Language Models
Jun 22, 2024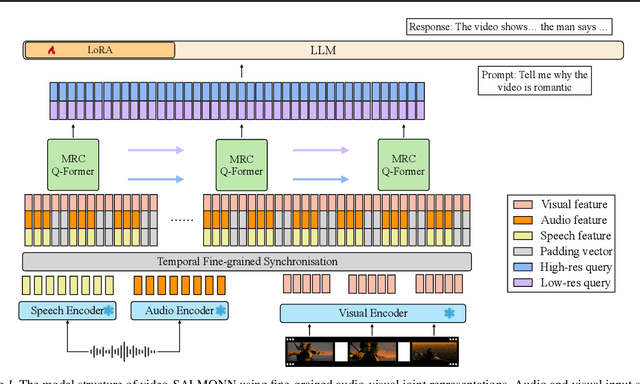



Speech understanding as an element of the more generic video understanding using audio-visual large language models (av-LLMs) is a crucial yet understudied aspect. This paper proposes video-SALMONN, a single end-to-end av-LLM for video processing, which can understand not only visual frame sequences, audio events and music, but speech as well. To obtain fine-grained temporal information required by speech understanding, while keeping efficient for other video elements, this paper proposes a novel multi-resolution causal Q-Former (MRC Q-Former) structure to connect pre-trained audio-visual encoders and the backbone large language model. Moreover, dedicated training approaches including the diversity loss and the unpaired audio-visual mixed training scheme are proposed to avoid frames or modality dominance. On the introduced speech-audio-visual evaluation benchmark, video-SALMONN achieves more than 25\% absolute accuracy improvements on the video-QA task and over 30\% absolute accuracy improvements on audio-visual QA tasks with human speech. In addition, video-SALMONN demonstrates remarkable video comprehension and reasoning abilities on tasks that are unprecedented by other av-LLMs. Our training code and model checkpoints are available at \texttt{\url{https://github.com/bytedance/SALMONN/}}.