 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Spark of Vision-Language Intelligence: 2-Dimensional Autoregressive Transformer for Efficient Finegrained Image Generation
Oct 02, 2024



This work tackles the information loss bottleneck of vector-quantization (VQ) autoregressive image generation by introducing a novel model architecture called the 2-Dimensional Autoregression (DnD) Transformer. The DnD-Transformer predicts more codes for an image by introducing a new autoregression direction, \textit{model depth}, along with the sequence length direction. Compared to traditional 1D autoregression and previous work utilizing similar 2D image decomposition such as RQ-Transformer, the DnD-Transformer is an end-to-end model that can generate higher quality images with the same backbone model size and sequence length, opening a new optimization perspective for autoregressive image generation. Furthermore, our experiments reveal that the DnD-Transformer's potential extends beyond generating natural images. It can even generate images with rich text and graphical elements in a self-supervised manner, demonstrating an understanding of these combined modalities. This has not been previously demonstrated for popular vision generative models such as diffusion models, showing a spark of vision-language intelligence when trained solely on images. Code, datasets and models are open at https://github.com/chenllliang/DnD-Transformer.
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Sep 18, 2024



We present the Qwen2-VL Series, an advanced upgrade of the previous Qwen-VL models that redefines the conventional predetermined-resolution approach in visual processing. Qwen2-VL introduces the Naive Dynamic Resolution mechanism, which enables the model to dynamically process images of varying resolutions into different numbers of visual tokens. This approach allows the model to generate more efficient and accurate visual representations, closely aligning with human perceptual processes. The model also integrates Multimodal Rotary Position Embedding (M-RoPE), facilitating the effective fusion of positional information across text, images, and videos. We employ a unified paradigm for processing both images and videos, enhancing the model's visual perception capabilities. To explore the potential of large multimodal models, Qwen2-VL investigates the scaling laws for large vision-language models (LVLMs). By scaling both the model size-with versions at 2B, 8B, and 72B parameters-and the amount of training data, the Qwen2-VL Series achieves highly competitive performance. Notably, the Qwen2-VL-72B model achieves results comparable to leading models such as GPT-4o and Claude3.5-Sonnet across various multimodal benchmarks, outperforming other generalist models. Code is available at \url{https://github.com/QwenLM/Qwen2-VL}.
Qwen2 Technical Report
Jul 16, 2024



This report introduces the Qwen2 series, the latest addition to our large language models and large multimodal models. We release a comprehensive suite of foundational and instruction-tuned language models, encompassing a parameter range from 0.5 to 72 billion, featuring dense models and a Mixture-of-Experts model. Qwen2 surpasses most prior open-weight models, including its predecessor Qwen1.5, and exhibits competitive performance relative to proprietary models across diverse benchmarks on language understanding, generation, multilingual proficiency, coding, mathematics, and reasoning. The flagship model, Qwen2-72B, showcases remarkable performance: 84.2 on MMLU, 37.9 on GPQA, 64.6 on HumanEval, 89.5 on GSM8K, and 82.4 on BBH as a base language model. The instruction-tuned variant, Qwen2-72B-Instruct, attains 9.1 on MT-Bench, 48.1 on Arena-Hard, and 35.7 on LiveCodeBench. Moreover, Qwen2 demonstrates robust multilingual capabilities, proficient in approximately 30 languages, spanning English, Chinese, Spanish, French, German, Arabic, Russian, Korean, Japanese, Thai, Vietnamese, and more, underscoring its versatility and global reach. To foster community innovation and accessibility, we have made the Qwen2 model weights openly available on Hugging Face and ModelScope, and the supplementary materials including example code on GitHub. These platforms also include resources for quantization, fine-tuning, and deployment, facilitating a wide range of applications and research endeavors.
Qwen Technical Report
Sep 28, 2023



Large language models (LLMs) have revolutionized the field of artificial intelligence, enabling natural language processing tasks that were previously thought to be exclusive to humans. In this work, we introduce Qwen, the first installment of our large language model series. Qwen is a comprehensive language model series that encompasses distinct models with varying parameter counts. It includes Qwen, the base pretrained language models, and Qwen-Chat, the chat models finetuned with human alignment techniques. The base language models consistently demonstrate superior performance across a multitude of downstream tasks, and the chat models, particularly those trained using Reinforcement Learning from Human Feedback (RLHF), are highly competitive. The chat models possess advanced tool-use and planning capabilities for creating agent applications, showcasing impressive performance even when compared to bigger models on complex tasks like utilizing a code interpreter. Furthermore, we have developed coding-specialized models, Code-Qwen and Code-Qwen-Chat, as well as mathematics-focused models, Math-Qwen-Chat, which are built upon base language models. These models demonstrate significantly improved performance in comparison with open-source models, and slightly fall behind the proprietary models.
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Sep 14, 2023



We introduce the Qwen-VL series, a set of large-scale vision-language models (LVLMs) designed to perceive and understand both text and images. Comprising Qwen-VL and Qwen-VL-Chat, these models exhibit remarkable performance in tasks like image captioning, question answering, visual localization, and flexible interaction. The evaluation covers a wide range of tasks including zero-shot captioning, visual or document visual question answering, and grounding. We demonstrate the Qwen-VL outperforms existing LVLMs. We present their architecture, training, capabilities, and performance, highlighting their contributions to advancing multimodal artificial intelligence. Code, demo and models are available at https://github.com/QwenLM/Qwen-VL.
OFASys: A Multi-Modal Multi-Task Learning System for Building Generalist Models
Dec 08, 2022



Generalist models, which are capable of performing diverse multi-modal tasks in a task-agnostic way within a single model, have been explored recently. Being, hopefully, an alternative to approaching general-purpose AI, existing generalist models are still at an early stage, where modality and task coverage is limited. To empower multi-modal task-scaling and speed up this line of research, we release a generalist model learning system, OFASys, built on top of a declarative task interface named multi-modal instruction. At the core of OFASys is the idea of decoupling multi-modal task representations from the underlying model implementations. In OFASys, a task involving multiple modalities can be defined declaratively even with just a single line of code. The system automatically generates task plans from such instructions for training and inference. It also facilitates multi-task training for diverse multi-modal workloads. As a starting point, we provide presets of 7 different modalities and 23 highly-diverse example tasks in OFASys, with which we also develop a first-in-kind, single model, OFA+, that can handle text, image, speech, video, and motion data. The single OFA+ model achieves 95% performance in average with only 16% parameters of 15 task-finetuned models, showcasing the performance reliability of multi-modal task-scaling provided by OFASys. Available at https://github.com/OFA-Sys/OFASys
Mixed Neural Voxels for Fast Multi-view Video Synthesis
Dec 01, 2022



Synthesizing high-fidelity videos from real-world multi-view input is challenging because of the complexities of real-world environments and highly dynamic motions. Previous works based on neural radiance fields have demonstrated high-quality reconstructions of dynamic scenes. However, training such models on real-world scenes is time-consuming, usually taking days or weeks. In this paper, we present a novel method named MixVoxels to better represent the dynamic scenes with fast training speed and competitive rendering qualities. The proposed MixVoxels represents the 4D dynamic scenes as a mixture of static and dynamic voxels and processes them with different networks. In this way, the computation of the required modalities for static voxels can be processed by a lightweight model, which essentially reduces the amount of computation, especially for many daily dynamic scenes dominated by the static background. To separate the two kinds of voxels, we propose a novel variation field to estimate the temporal variance of each voxel. For the dynamic voxels, we design an inner-product time query method to efficiently query multiple time steps, which is essential to recover the high-dynamic motions. As a result, with 15 minutes of training for dynamic scenes with inputs of 300-frame videos, MixVoxels achieves better PSNR than previous methods. Codes and trained models are available at https://github.com/fengres/mixvoxels
Embodied Referring Expression for Manipulation Question Answering in Interactive Environment
Oct 06, 2022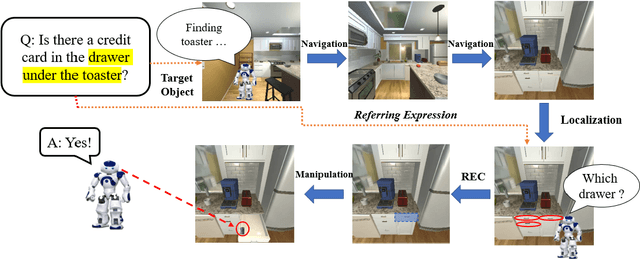
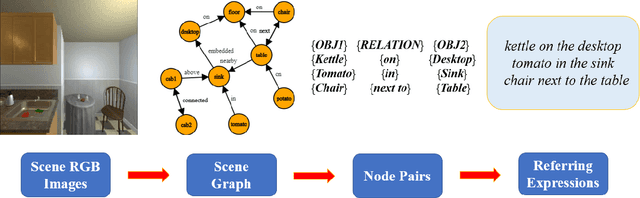
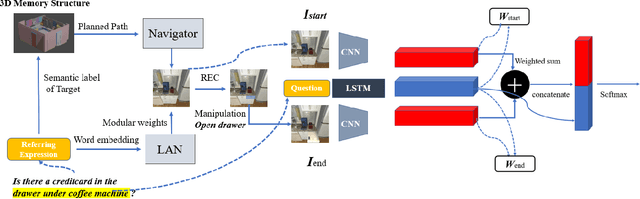

Embodied agents are expected to perform more complicated tasks in an interactive environment, with the progress of Embodied AI in recent years. Existing embodied tasks including Embodied Referring Expression (ERE) and other QA-form tasks mainly focuses on interaction in term of linguistic instruction. Therefore, enabling the agent to manipulate objects in the environment for exploration actively has become a challenging problem for the community. To solve this problem, We introduce a new embodied task: Remote Embodied Manipulation Question Answering (REMQA) to combine ERE with manipulation tasks. In the REMQA task, the agent needs to navigate to a remote position and perform manipulation with the target object to answer the question. We build a benchmark dataset for the REMQA task in the AI2-THOR simulator. To this end, a framework with 3D semantic reconstruction and modular network paradigms is proposed. The evaluation of the proposed framework on the REMQA dataset is presented to validate its effectiveness.
An Automated Question-Answering Framework Based on Evolution Algorithm
Jan 26, 2022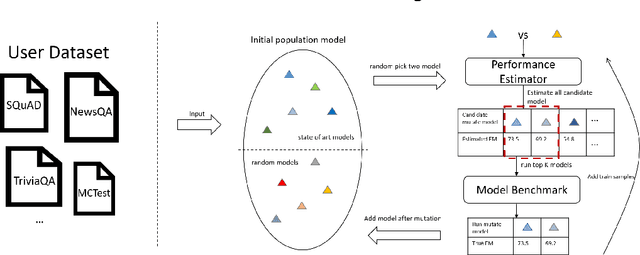

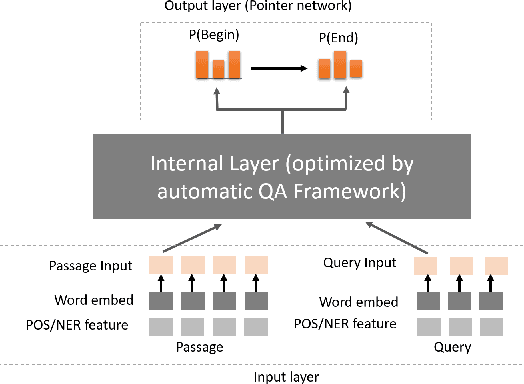
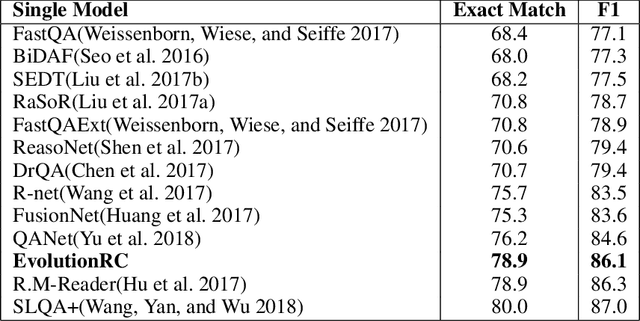
Building a deep learning model for a Question-Answering (QA) task requires a lot of human effort, it may need several months to carefully tune various model architectures and find a best one. It's even harder to find different excellent models for multiple datasets. Recent works show that the best model structure is related to the dataset used, and one single model cannot adapt to all tasks. In this paper, we propose an automated Question-Answering framework, which could automatically adjust network architecture for multiple datasets. Our framework is based on an innovative evolution algorithm, which is stable and suitable for multiple dataset scenario. The evolution algorithm for search combine prior knowledge into initial population and use a performance estimator to avoid inefficient mutation by predicting the performance of candidate model architecture. The prior knowledge used in initial population could improve the final result of the evolution algorithm. The performance estimator could quickly filter out models with bad performance in population as the number of trials increases, to speed up the convergence. Our framework achieves 78.9 EM and 86.1 F1 on SQuAD 1.1, 69.9 EM and 72.5 F1 on SQuAD 2.0. On NewsQA dataset, the found model achieves 47.0 EM and 62.9 F1.
Self-supervised 3D Semantic Representation Learning for Vision-and-Language Navigation
Jan 26, 2022



In the Vision-and-Language Navigation task, the embodied agent follows linguistic instructions and navigates to a specific goal. It is important in many practical scenarios and has attracted extensive attention from both computer vision and robotics communities. However, most existing works only use RGB images but neglect the 3D semantic information of the scene. To this end, we develop a novel self-supervised training framework to encode the voxel-level 3D semantic reconstruction into a 3D semantic representation. Specifically, a region query task is designed as the pretext task, which predicts the presence or absence of objects of a particular class in a specific 3D region. Then, we construct an LSTM-based navigation model and train it with the proposed 3D semantic representations and BERT language features on vision-language pairs. Experiments show that the proposed approach achieves success rates of 68% and 66% on the validation unseen and test unseen splits of the R2R dataset respectively, which are superior to most of RGB-based methods utilizing vision-language transformers.