 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Study of Federated Prompt Learning for Vision Language Model
May 29, 2025The Vision Language Model (VLM) excels in aligning vision and language representations, and prompt learning has emerged as a key technique for adapting such models to downstream tasks. However, the application of prompt learning with VLM in federated learning (\fl{}) scenarios remains underexplored. This paper systematically investigates the behavioral differences between language prompt learning (LPT) and vision prompt learning (VPT) under data heterogeneity challenges, including label skew and domain shift. We conduct extensive experiments to evaluate the impact of various \fl{} and prompt configurations, such as client scale, aggregation strategies, and prompt length, to assess the robustness of Federated Prompt Learning (FPL). Furthermore, we explore strategies for enhancing prompt learning in complex scenarios where label skew and domain shift coexist, including leveraging both prompt types when computational resources allow. Our findings offer practical insights into optimizing prompt learning in federated settings, contributing to the broader deployment of VLMs in privacy-preserving environments.
ZeroGUI: Automating Online GUI Learning at Zero Human Cost
May 29, 2025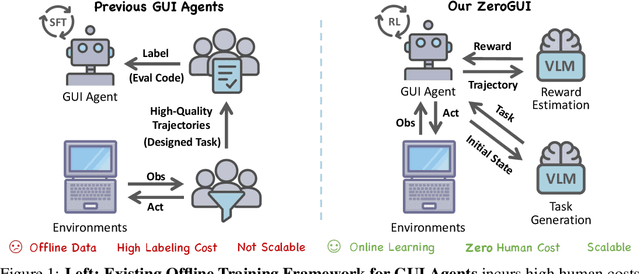
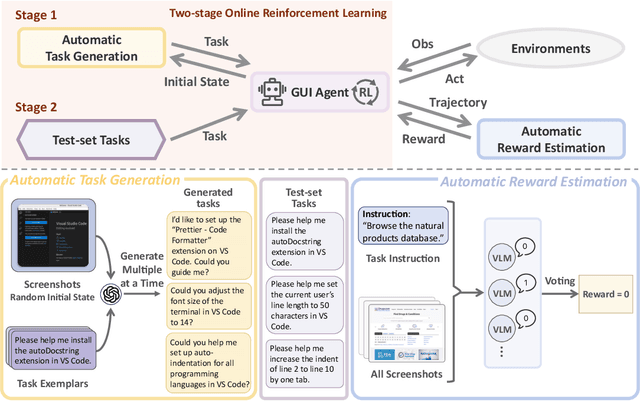


The rapid advancement of large Vision-Language Models (VLMs) has propelled the development of pure-vision-based GUI Agents, capable of perceiving and operating Graphical User Interfaces (GUI) to autonomously fulfill user instructions. However, existing approaches usually adopt an offline learning framework, which faces two core limitations: (1) heavy reliance on high-quality manual annotations for element grounding and action supervision, and (2) limited adaptability to dynamic and interactive environments. To address these limitations, we propose ZeroGUI, a scalable, online learning framework for automating GUI Agent training at Zero human cost. Specifically, ZeroGUI integrates (i) VLM-based automatic task generation to produce diverse training goals from the current environment state, (ii) VLM-based automatic reward estimation to assess task success without hand-crafted evaluation functions, and (iii) two-stage online reinforcement learning to continuously interact with and learn from GUI environments. Experiments on two advanced GUI Agents (UI-TARS and Aguvis) demonstrate that ZeroGUI significantly boosts performance across OSWorld and AndroidLab environments. The code is available at https://github.com/OpenGVLab/ZeroGUI.
O$^2$-Searcher: A Searching-based Agent Model for Open-Domain Open-Ended Question Answering
May 22, 2025



Large Language Models (LLMs), despite their advancements, are fundamentally limited by their static parametric knowledge, hindering performance on tasks requiring open-domain up-to-date information. While enabling LLMs to interact with external knowledge environments is a promising solution, current efforts primarily address closed-end problems. Open-ended questions, which characterized by lacking a standard answer or providing non-unique and diverse answers, remain underexplored. To bridge this gap, we present O$^2$-Searcher, a novel search agent leveraging reinforcement learning to effectively tackle both open-ended and closed-ended questions in the open domain. O$^2$-Searcher leverages an efficient, locally simulated search environment for dynamic knowledge acquisition, effectively decoupling the external world knowledge from model's sophisticated reasoning processes. It employs a unified training mechanism with meticulously designed reward functions, enabling the agent to identify problem types and adapt different answer generation strategies. Furthermore, to evaluate performance on complex open-ended tasks, we construct O$^2$-QA, a high-quality benchmark featuring 300 manually curated, multi-domain open-ended questions with associated web page caches. Extensive experiments show that O$^2$-Searcher, using only a 3B model, significantly surpasses leading LLM agents on O$^2$-QA. It also achieves SOTA results on various closed-ended QA benchmarks against similarly-sized models, while performing on par with much larger ones.
Towards Artificial General or Personalized Intelligence? A Survey on Foundation Models for Personalized Federated Intelligence
May 11, 2025



The rise of large language models (LLMs), such as ChatGPT, DeepSeek, and Grok-3, has reshaped the artificial intelligence landscape. As prominent examples of foundational models (FMs) built on LLMs, these models exhibit remarkable capabilities in generating human-like content, bringing us closer to achieving artificial general intelligence (AGI). However, their large-scale nature, sensitivity to privacy concerns, and substantial computational demands present significant challenges to personalized customization for end users. To bridge this gap, this paper presents the vision of artificial personalized intelligence (API), focusing on adapting these powerful models to meet the specific needs and preferences of users while maintaining privacy and efficiency. Specifically, this paper proposes personalized federated intelligence (PFI), which integrates the privacy-preserving advantages of federated learning (FL) with the zero-shot generalization capabilities of FMs, enabling personalized, efficient, and privacy-protective deployment at the edge. We first review recent advances in both FL and FMs, and discuss the potential of leveraging FMs to enhance federated systems. We then present the key motivations behind realizing PFI and explore promising opportunities in this space, including efficient PFI, trustworthy PFI, and PFI empowered by retrieval-augmented generation (RAG). Finally, we outline key challenges and future research directions for deploying FM-powered FL systems at the edge with improved personalization, computational efficiency, and privacy guarantees. Overall, this survey aims to lay the groundwork for the development of API as a complement to AGI, with a particular focus on PFI as a key enabling technique.
Weakly Supervised Temporal Sentence Grounding via Positive Sample Mining
May 10, 2025The task of weakly supervised temporal sentence grounding (WSTSG) aims to detect temporal intervals corresponding to a language description from untrimmed videos with only video-level video-language correspondence. For an anchor sample, most existing approaches generate negative samples either from other videos or within the same video for contrastive learning. However, some training samples are highly similar to the anchor sample, directly regarding them as negative samples leads to difficulties for optimization and ignores the correlations between these similar samples and the anchor sample. To address this, we propose Positive Sample Mining (PSM), a novel framework that mines positive samples from the training set to provide more discriminative supervision. Specifically, for a given anchor sample, we partition the remaining training set into semantically similar and dissimilar subsets based on the similarity of their text queries. To effectively leverage these correlations, we introduce a PSM-guided contrastive loss to ensure that the anchor proposal is closer to similar samples and further from dissimilar ones. Additionally, we design a PSM-guided rank loss to ensure that similar samples are closer to the anchor proposal than to the negative intra-video proposal, aiming to distinguish the anchor proposal and the negative intra-video proposal. Experiments on the WSTSG and grounded VideoQA tasks demonstrate the effectiveness and superiority of our method.
GDI-Bench: A Benchmark for General Document Intelligence with Vision and Reasoning Decoupling
Apr 30, 2025The rapid advancement of multimodal large language models (MLLMs) has profoundly impacted the document domain, creating a wide array of application scenarios. This progress highlights the need for a comprehensive benchmark to evaluate these models' capabilities across various document-specific tasks. However, existing benchmarks often fail to locate specific model weaknesses or guide systematic improvements. To bridge this gap, we introduce a General Document Intelligence Benchmark (GDI-Bench), featuring 1.9k images across 9 key scenarios and 19 document-specific tasks. By decoupling visual complexity and reasoning complexity, the GDI-Bench structures graded tasks that allow performance assessment by difficulty, aiding in model weakness identification and optimization guidance. We evaluate the GDI-Bench on various open-source and closed-source models, conducting decoupled analyses in the visual and reasoning domains. For instance, the GPT-4o model excels in reasoning tasks but exhibits limitations in visual capabilities. To address the diverse tasks and domains in the GDI-Bench, we propose a GDI Model that mitigates the issue of catastrophic forgetting during the supervised fine-tuning (SFT) process through a intelligence-preserving training strategy. Our model achieves state-of-the-art performance on previous benchmarks and the GDI-Bench. Both our benchmark and model will be open source.
TrustGeoGen: Scalable and Formal-Verified Data Engine for Trustworthy Multi-modal Geometric Problem Solving
Apr 22, 2025



Mathematical geometric problem solving (GPS) often requires effective integration of multimodal information and verifiable logical coherence. Despite the fast development of large language models in general problem solving, it remains unresolved regarding with both methodology and benchmarks, especially given the fact that exiting synthetic GPS benchmarks are often not self-verified and contain noise and self-contradicted information due to the illusion of LLMs. In this paper, we propose a scalable data engine called TrustGeoGen for problem generation, with formal verification to provide a principled benchmark, which we believe lays the foundation for the further development of methods for GPS. The engine synthesizes geometric data through four key innovations: 1) multimodal-aligned generation of diagrams, textual descriptions, and stepwise solutions; 2) formal verification ensuring rule-compliant reasoning paths; 3) a bootstrapping mechanism enabling complexity escalation via recursive state generation and 4) our devised GeoExplore series algorithms simultaneously produce multi-solution variants and self-reflective backtracking traces. By formal logical verification, TrustGeoGen produces GeoTrust-200K dataset with guaranteed modality integrity, along with GeoTrust-test testset. Experiments reveal the state-of-the-art models achieve only 49.17\% accuracy on GeoTrust-test, demonstrating its evaluation stringency. Crucially, models trained on GeoTrust achieve OOD generalization on GeoQA, significantly reducing logical inconsistencies relative to pseudo-label annotated by OpenAI-o1. Our code is available at https://github.com/Alpha-Innovator/TrustGeoGen
The Devil is in the Prompts: Retrieval-Augmented Prompt Optimization for Text-to-Video Generation
Apr 16, 2025The evolution of Text-to-video (T2V) generative models, trained on large-scale datasets, has been marked by significant progress. However, the sensitivity of T2V generative models to input prompts highlights the critical role of prompt design in influencing generative outcomes. Prior research has predominantly relied on Large Language Models (LLMs) to align user-provided prompts with the distribution of training prompts, albeit without tailored guidance encompassing prompt vocabulary and sentence structure nuances. To this end, we introduce \textbf{RAPO}, a novel \textbf{R}etrieval-\textbf{A}ugmented \textbf{P}rompt \textbf{O}ptimization framework. In order to address potential inaccuracies and ambiguous details generated by LLM-generated prompts. RAPO refines the naive prompts through dual optimization branches, selecting the superior prompt for T2V generation. The first branch augments user prompts with diverse modifiers extracted from a learned relational graph, refining them to align with the format of training prompts via a fine-tuned LLM. Conversely, the second branch rewrites the naive prompt using a pre-trained LLM following a well-defined instruction set. Extensive experiments demonstrate that RAPO can effectively enhance both the static and dynamic dimensions of generated videos, demonstrating the significance of prompt optimization for user-provided prompts. Project website: \href{https://whynothaha.github.io/Prompt_optimizer/RAPO.html}{GitHub}.
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Apr 15, 2025We introduce InternVL3, a significant advancement in the InternVL series featuring a native multimodal pre-training paradigm. Rather than adapting a text-only large language model (LLM) into a multimodal large language model (MLLM) that supports visual inputs, InternVL3 jointly acquires multimodal and linguistic capabilities from both diverse multimodal data and pure-text corpora during a single pre-training stage. This unified training paradigm effectively addresses the complexities and alignment challenges commonly encountered in conventional post-hoc training pipelines for MLLMs. To further improve performance and scalability, InternVL3 incorporates variable visual position encoding (V2PE) to support extended multimodal contexts, employs advanced post-training techniques such as supervised fine-tuning (SFT) and mixed preference optimization (MPO), and adopts test-time scaling strategies alongside an optimized training infrastructure. Extensive empirical evaluations demonstrate that InternVL3 delivers superior performance across a wide range of multi-modal tasks. In particular, InternVL3-78B achieves a score of 72.2 on the MMMU benchmark, setting a new state-of-the-art among open-source MLLMs. Its capabilities remain highly competitive with leading proprietary models, including ChatGPT-4o, Claude 3.5 Sonnet, and Gemini 2.5 Pro, while also maintaining strong pure-language proficiency. In pursuit of open-science principles, we will publicly release both the training data and model weights to foster further research and development in next-generation MLLMs.
VideoChat-R1: Enhancing Spatio-Temporal Perception via Reinforcement Fine-Tuning
Apr 10, 2025Recent advancements in reinforcement learning have significantly advanced the reasoning capabilities of multimodal large language models (MLLMs). While approaches such as Group Relative Policy Optimization (GRPO) and rule-based reward mechanisms demonstrate promise in text and image domains, their application to video understanding remains limited. This paper presents a systematic exploration of Reinforcement Fine-Tuning (RFT) with GRPO for video MLLMs, aiming to enhance spatio-temporal perception while maintaining general capabilities. Our experiments reveal that RFT is highly data-efficient for task-specific improvements. Through multi-task RFT on spatio-temporal perception objectives with limited samples, we develop VideoChat-R1, a powerful video MLLM that achieves state-of-the-art performance on spatio-temporal perception tasks without sacrificing chat ability, while exhibiting emerging spatio-temporal reasoning abilities. Compared to Qwen2.5-VL-7B, VideoChat-R1 boosts performance several-fold in tasks like temporal grounding (+31.8) and object tracking (+31.2). Additionally, it significantly improves on general QA benchmarks such as VideoMME (+0.9), MVBench (+1.0), and Perception Test (+0.9). Our findings underscore the potential of RFT for specialized task enhancement of Video MLLMs. We hope our work offers valuable insights for future RL research in video MLLMs.