 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComAct: Reframing Professional Software Manipulation via COM-as-Action Paradigm
Jun 11, 2026Existing computer-use agents remain fundamentally limited in professional software manipulation: GUI-based agents suffer from fragile visual grounding and long-horizon error accumulation, while API-basedapproaches struggle with heterogeneous protocols and inaccessible commercial interfaces. In this work,we identify the Component Object Model (COM) as a unified executable abstraction, proposing COM-as-Action: a new paradigm that reframes professional software interaction as deterministic program synthesisrather than sequential visual control. To validate this paradigm in the most demanding environments, weintroduce ComCADBench, the first benchmark for agents operating real industrial CAD software. Ourexperiments reveal a substantial paradigm gap: frontier proprietary models achieve near-zero successunder GUI-based interaction, whereas COM-based execution yields substantial immediate gains. Tobridge the remaining gap between syntactic correctness and geometric accuracy, we develop ComActor, aself-correcting agent trained through a progressive three-stage framework, alongside ComForge, a scalableplatform for large-scale training in Windows containers. Extensive experiments show that ComActorachieves state-of-the-art performance on ComCADBench, with strong resilience in long-horizon taskswhere baselines collapse, and generalizes to external CAD benchmark.
IterCAD: An Iterative Multimodal Agent for Visually-Grounded CAD Generation and Editing
Jun 11, 2026Computer-Aided Design is pivotal in modern manufacturing, yet existing automated methods predominantly rely on open-loop, one-shot generation, creating a mismatch with iterative real-world practices. In this paper, we present IterCAD, a unified multimodal agent framework for closed-loop, interactive CAD generation and editing. We formulate the task as a multi-turn interaction between a multimodal agent and an executable CAD sandbox, covering three tasks: Drawing-to-Code, Text-to-Code, and Interactive Editing. To support this, we develop a data synthesis pipeline incorporating advanced industrial manufacturing features to generate standard-compliant multi-view engineering drawings, complex code-editing tasks, and high-fidelity interaction trajectories. We optimize the agent via progressive SFT followed by geometry-aware reinforcement learning with viable-prefix masking to enhance code executability and geometric fidelity. Finally, we introduce the IterCAD-Bench evaluation suite and propose the Chamfer Distance Tolerance-Recall (CD-TR) curve alongside its AUC-TR metric, establishing a survivor-bias-free standard that unifies code validity and geometric precision. Extensive experiments demonstrate that IterCAD achieves highly competitive performance across multiple benchmarks, significantly outperforming existing approaches in both code executability and geometric precision, while exhibiting superior capabilities in closed-loop iterative refinement.
EviProp: Seeded Relevance Diffusion on Chunk-Page Graphs for Long Multimodal Document Retrieval
Jun 08, 2026Retrieving evidence pages from visually rich long documents is a key challenge in document question answering. Existing page-level visual retrievers operate under an independent matching paradigm: each page is scored in isolation based on query-page similarity. This paradigm can under-rank evidence pages whose signals are localized in fine-grained chunks or depend on document-internal associations. We propose EviProp, a retrieval method that recovers such pages via seeded relevance diffusion. EviProp models each document as a multimodal Chunk-Page graph with hierarchical, sequential, and similarity links. Given a query, it combines dense visual page priors with sparse chunk seeds, then runs Personalized PageRank to diffuse relevance over the graph. Experiments on MMLongBench-Doc and LongDocURL show consistent gains in evidence-page retrieval over independent visual retrieval and text-visual fusion baselines. Downstream QA results further show that improved retrieval translates into better answer accuracy, with negligible online retrieval overhead. Our code is released at https://github.com/Flyecnu/EviProp.
IA-RAG: Interval-Algebra-Driven Temporal Reasoning for Dynamic Knowledge Retrieval
Jun 04, 2026Retrieval-Augmented Generation (RAG) has shown strong effectiveness in grounding Large Language Models (LLMs) with external knowledge. However, existing RAG and Graph RAG frameworks largely treat knowledge as static or associate time with coarse-grained timestamps or metadata, failing to capture rich temporal structures such as duration, overlap, and containment. We propose IA-RAG, a hierarchical temporal RAG framework that models knowledge as time intervals and performs retrieval under formal temporal constraints. IA-RAG represents facts as Interval Event Units (IEUs) and organizes them into a hierarchical Thematic Forest, where temporal dependencies are governed by Allen's Interval Algebra. To handle incomplete or uncertain temporal boundaries, IA-RAG further introduces a Sub-graph Time Tightening mechanism that refines fuzzy intervals through logical constraints within connected event subgraphs. In addition, IA-RAG supports implicit temporal semantic retrieval through interval-algebra-guided traversal. Experiments on multiple temporal question answering benchmarks, including TimeQA, TempReason, and ComplexTR, demonstrate that IA-RAG achieves strong temporal retrieval and reasoning performance, particularly on complex compositional temporal reasoning tasks. Our code is released at https://github.com/xiaoAugenstern/LogicalRAG_TemporalQA.
AgentSchool: An LLM-Powered Multi-Agent Simulation for Education
May 28, 2026Despite the rapid deployment of LLMs into classrooms, validating educational AI remains uniquely intractable: interventions act on developing learners whose cognitive and social trajectories are irreversibly shaped, while real-world trials are slow, ethically constrained, and institutionally locked. LLM-based educational simulators have emerged as a potential remedy, but many still collapse learning into persona-conditioned role-play and, when optimized only to reproduce existing classrooms, can structurally penalize the institutional novelty that pedagogical reform requires. In this work, we introduce AgentSchool, an LLM-driven multi-agent simulator that models learning as state transition rather than prompted behavior. AgentSchool couples cognitively growable student agents -- equipped with weighted subject knowledge graphs, thinking-workflow pools, and explicit misconceptions -- with adaptive teacher agents that plan, scaffold, and reflect along the Zone of Proximal Development, embedded in a configurable scenery generator that situates instruction within both formal and informal learning fields, and a multi-scale simulator that decouples interaction scale, temporal granularity, and simulation duration. Experiments show that structured student agents produce more differentiated mastery and misconception traces than a baseline simulator, while teacher-agent comparisons show backbone-dependent patterns consistent with ZPD-informed adaptation. Further, AgentSchool generates plausible traces of peripheral participation, clique formation, aggressor-induced cohesion, and opinion-leader emergence consistent with classroom social theories. Beyond its role as an educational research instrument, AgentSchool frames education as a socially meaningful testbed for long-horizon memory, multi-agent coordination, and future institutional reasoning under organizational pressure.
The Agent's First Day: Benchmarking Learning, Exploration, and Scheduling in the Workplace Scenarios
Jan 13, 2026The rapid evolution of Multi-modal Large Language Models (MLLMs) has advanced workflow automation; however, existing research mainly targets performance upper bounds in static environments, overlooking robustness for stochastic real-world deployment. We identify three key challenges: dynamic task scheduling, active exploration under uncertainty, and continuous learning from experience. To bridge this gap, we introduce \method{}, a dynamic evaluation environment that simulates a "trainee" agent continuously exploring a novel setting. Unlike traditional benchmarks, \method{} evaluates agents along three dimensions: (1) context-aware scheduling for streaming tasks with varying priorities; (2) prudent information acquisition to reduce hallucination via active exploration; and (3) continuous evolution by distilling generalized strategies from rule-based, dynamically generated tasks. Experiments show that cutting-edge agents have significant deficiencies in dynamic environments, especially in active exploration and continual learning. Our work establishes a framework for assessing agent reliability, shifting evaluation from static tests to realistic, production-oriented scenarios. Our codes are available at https://github.com/KnowledgeXLab/EvoEnv
SymDrive: Realistic and Controllable Driving Simulator via Symmetric Auto-regressive Online Restoration
Dec 25, 2025



High-fidelity and controllable 3D simulation is essential for addressing the long-tail data scarcity in Autonomous Driving (AD), yet existing methods struggle to simultaneously achieve photorealistic rendering and interactive traffic editing. Current approaches often falter in large-angle novel view synthesis and suffer from geometric or lighting artifacts during asset manipulation. To address these challenges, we propose SymDrive, a unified diffusion-based framework capable of joint high-quality rendering and scene editing. We introduce a Symmetric Auto-regressive Online Restoration paradigm, which constructs paired symmetric views to recover fine-grained details via a ground-truth-guided dual-view formulation and utilizes an auto-regressive strategy for consistent lateral view generation. Furthermore, we leverage this restoration capability to enable a training-free harmonization mechanism, treating vehicle insertion as context-aware inpainting to ensure seamless lighting and shadow consistency. Extensive experiments demonstrate that SymDrive achieves state-of-the-art performance in both novel-view enhancement and realistic 3D vehicle insertion.
Learning on the Job: An Experience-Driven Self-Evolving Agent for Long-Horizon Tasks
Oct 09, 2025Large Language Models have demonstrated remarkable capabilities across diverse domains, yet significant challenges persist when deploying them as AI agents for real-world long-horizon tasks. Existing LLM agents suffer from a critical limitation: they are test-time static and cannot learn from experience, lacking the ability to accumulate knowledge and continuously improve on the job. To address this challenge, we propose MUSE, a novel agent framework that introduces an experience-driven, self-evolving system centered around a hierarchical Memory Module. MUSE organizes diverse levels of experience and leverages them to plan and execute long-horizon tasks across multiple applications. After each sub-task execution, the agent autonomously reflects on its trajectory, converting the raw trajectory into structured experience and integrating it back into the Memory Module. This mechanism enables the agent to evolve beyond its static pretrained parameters, fostering continuous learning and self-evolution. We evaluate MUSE on the long-horizon productivity benchmark TAC. It achieves new SOTA performance by a significant margin using only a lightweight Gemini-2.5 Flash model. Sufficient Experiments demonstrate that as the agent autonomously accumulates experience, it exhibits increasingly superior task completion capabilities, as well as robust continuous learning and self-evolution capabilities. Moreover, the accumulated experience from MUSE exhibits strong generalization properties, enabling zero-shot improvement on new tasks. MUSE establishes a new paradigm for AI agents capable of real-world productivity task automation.
LeanRAG: Knowledge-Graph-Based Generation with Semantic Aggregation and Hierarchical Retrieval
Aug 14, 2025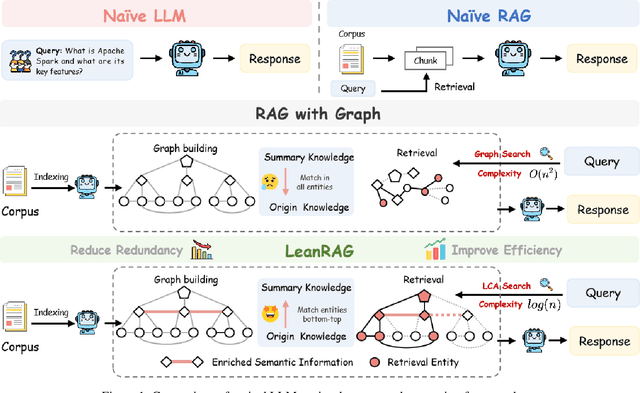
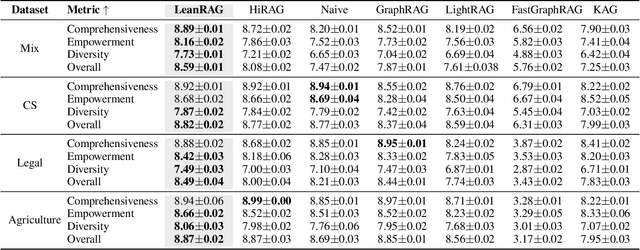
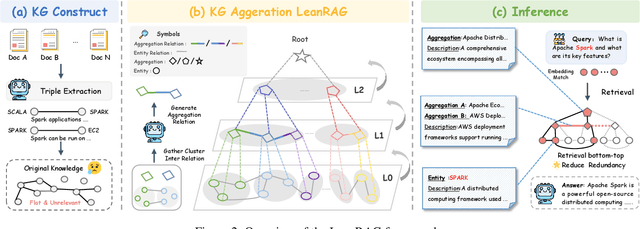

Retrieval-Augmented Generation (RAG) plays a crucial role in grounding Large Language Models by leveraging external knowledge, whereas the effectiveness is often compromised by the retrieval of contextually flawed or incomplete information. To address this, knowledge graph-based RAG methods have evolved towards hierarchical structures, organizing knowledge into multi-level summaries. However, these approaches still suffer from two critical, unaddressed challenges: high-level conceptual summaries exist as disconnected ``semantic islands'', lacking the explicit relations needed for cross-community reasoning; and the retrieval process itself remains structurally unaware, often degenerating into an inefficient flat search that fails to exploit the graph's rich topology. To overcome these limitations, we introduce LeanRAG, a framework that features a deeply collaborative design combining knowledge aggregation and retrieval strategies. LeanRAG first employs a novel semantic aggregation algorithm that forms entity clusters and constructs new explicit relations among aggregation-level summaries, creating a fully navigable semantic network. Then, a bottom-up, structure-guided retrieval strategy anchors queries to the most relevant fine-grained entities and then systematically traverses the graph's semantic pathways to gather concise yet contextually comprehensive evidence sets. The LeanRAG can mitigate the substantial overhead associated with path retrieval on graphs and minimizes redundant information retrieval. Extensive experiments on four challenging QA benchmarks with different domains demonstrate that LeanRAG significantly outperforming existing methods in response quality while reducing 46\% retrieval redundancy. Code is available at: https://github.com/RaZzzyz/LeanRAG
O$^2$-Searcher: A Searching-based Agent Model for Open-Domain Open-Ended Question Answering
May 22, 2025



Large Language Models (LLMs), despite their advancements, are fundamentally limited by their static parametric knowledge, hindering performance on tasks requiring open-domain up-to-date information. While enabling LLMs to interact with external knowledge environments is a promising solution, current efforts primarily address closed-end problems. Open-ended questions, which characterized by lacking a standard answer or providing non-unique and diverse answers, remain underexplored. To bridge this gap, we present O$^2$-Searcher, a novel search agent leveraging reinforcement learning to effectively tackle both open-ended and closed-ended questions in the open domain. O$^2$-Searcher leverages an efficient, locally simulated search environment for dynamic knowledge acquisition, effectively decoupling the external world knowledge from model's sophisticated reasoning processes. It employs a unified training mechanism with meticulously designed reward functions, enabling the agent to identify problem types and adapt different answer generation strategies. Furthermore, to evaluate performance on complex open-ended tasks, we construct O$^2$-QA, a high-quality benchmark featuring 300 manually curated, multi-domain open-ended questions with associated web page caches. Extensive experiments show that O$^2$-Searcher, using only a 3B model, significantly surpasses leading LLM agents on O$^2$-QA. It also achieves SOTA results on various closed-ended QA benchmarks against similarly-sized models, while performing on par with much larger ones.