 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSegviGen: Repurposing 3D Generative Model for Part Segmentation
Mar 17, 2026We introduce SegviGen, a framework that repurposes native 3D generative models for 3D part segmentation. Existing pipelines either lift strong 2D priors into 3D via distillation or multi-view mask aggregation, often suffering from cross-view inconsistency and blurred boundaries, or explore native 3D discriminative segmentation, which typically requires large-scale annotated 3D data and substantial training resources. In contrast, SegviGen leverages the structured priors encoded in pretrained 3D generative model to induce segmentation through distinctive part colorization, establishing a novel and efficient framework for part segmentation. Specifically, SegviGen encodes a 3D asset and predicts part-indicative colors on active voxels of a geometry-aligned reconstruction. It supports interactive part segmentation, full segmentation, and full segmentation with 2D guidance in a unified framework. Extensive experiments show that SegviGen improves over the prior state of the art by 40% on interactive part segmentation and by 15% on full segmentation, while using only 0.32% of the labeled training data. It demonstrates that pretrained 3D generative priors transfer effectively to 3D part segmentation, enabling strong performance with limited supervision. See our project page at https://fenghora.github.io/SegviGen-Page/.
HomeGuard: VLM-based Embodied Safeguard for Identifying Contextual Risk in Household Task
Mar 15, 2026Vision-Language Models (VLMs) empower embodied agents to execute complex instructions, yet they remain vulnerable to contextual safety risks where benign commands become hazardous due to subtle environmental states. Existing safeguards often prove inadequate. Rule-based methods lack scalability in object-dense scenes, whereas model-based approaches relying on prompt engineering suffer from unfocused perception, resulting in missed risks or hallucinations. To address this, we propose an architecture-agnostic safeguard featuring Context-Guided Chain-of-Thought (CG-CoT). This mechanism decomposes risk assessment into active perception that sequentially anchors attention to interaction targets and relevant spatial neighborhoods, followed by semantic judgment based on this visual evidence. We support this approach with a curated grounding dataset and a two-stage training strategy utilizing Reinforcement Fine-Tuning (RFT) with process rewards to enforce precise intermediate grounding. Experiments demonstrate that our model HomeGuard significantly enhances safety, improving risk match rates by over 30% compared to base models while reducing oversafety. Beyond hazard detection, the generated visual anchors serve as actionable spatial constraints for downstream planners, facilitating explicit collision avoidance and safety trajectory generation. Code and data are released under https://github.com/AI45Lab/HomeGuard
PROMO: Promptable Outfitting for Efficient High-Fidelity Virtual Try-On
Mar 12, 2026Virtual Try-on (VTON) has become a core capability for online retail, where realistic try-on results provide reliable fit guidance, reduce returns, and benefit both consumers and merchants. Diffusion-based VTON methods achieve photorealistic synthesis, yet often rely on intricate architectures such as auxiliary reference networks and suffer from slow sampling, making the trade-off between fidelity and efficiency a persistent challenge. We approach VTON as a structured image editing problem that demands strong conditional generation under three key requirements: subject preservation, faithful texture transfer, and seamless harmonization. Under this perspective, our training framework is generic and transfers to broader image editing tasks. Moreover, the paired data produced by VTON constitutes a rich supervisory resource for training general-purpose editors. We present PROMO, a promptable virtual try-on framework built upon a Flow Matching DiT backbone with latent multi-modal conditional concatenation. By leveraging conditioning efficiency and self-reference mechanisms, our approach substantially reduces inference overhead. On standard benchmarks, PROMO surpasses both prior VTON methods and general image editing models in visual fidelity while delivering a competitive balance between quality and speed. These results demonstrate that flow-matching transformers, coupled with latent multi-modal conditioning and self-reference acceleration, offer an effective and training-efficient solution for high-quality virtual try-on.
ProGuard: Towards Proactive Multimodal Safeguard
Dec 29, 2025The rapid evolution of generative models has led to a continuous emergence of multimodal safety risks, exposing the limitations of existing defense methods. To address these challenges, we propose ProGuard, a vision-language proactive guard that identifies and describes out-of-distribution (OOD) safety risks without the need for model adjustments required by traditional reactive approaches. We first construct a modality-balanced dataset of 87K samples, each annotated with both binary safety labels and risk categories under a hierarchical multimodal safety taxonomy, effectively mitigating modality bias and ensuring consistent moderation across text, image, and text-image inputs. Based on this dataset, we train our vision-language base model purely through reinforcement learning (RL) to achieve efficient and concise reasoning. To approximate proactive safety scenarios in a controlled setting, we further introduce an OOD safety category inference task and augment the RL objective with a synonym-bank-based similarity reward that encourages the model to generate concise descriptions for unseen unsafe categories. Experimental results show that ProGuard achieves performance comparable to closed-source large models on binary safety classification, substantially outperforms existing open-source guard models on unsafe content categorization. Most notably, ProGuard delivers a strong proactive moderation ability, improving OOD risk detection by 52.6% and OOD risk description by 64.8%.
Reasoning-Driven Amodal Completion: Collaborative Agents and Perceptual Evaluation
Dec 24, 2025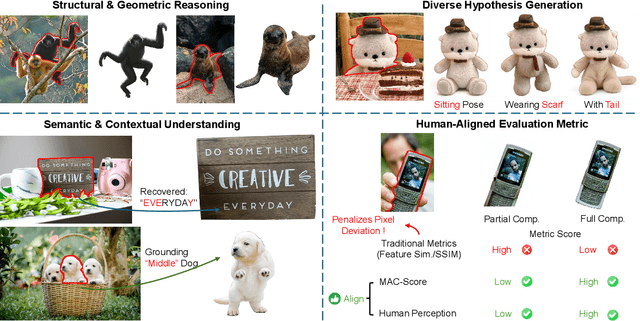

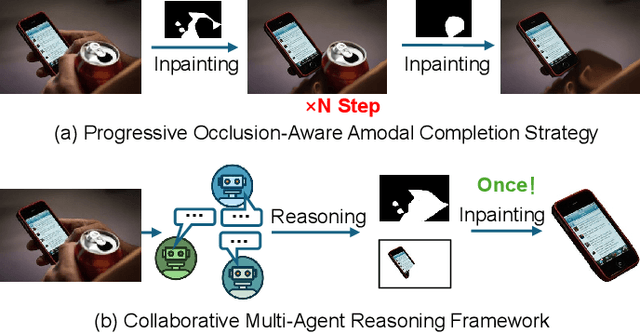
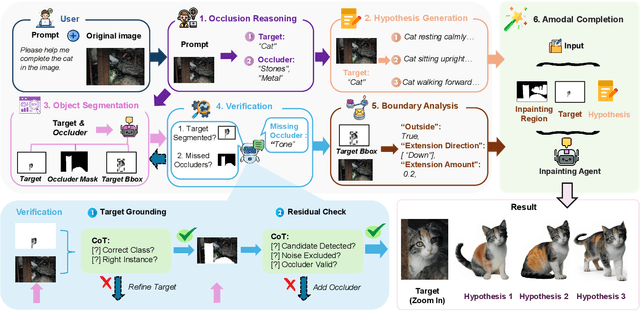
Amodal completion, the task of inferring invisible object parts, faces significant challenges in maintaining semantic consistency and structural integrity. Prior progressive approaches are inherently limited by inference instability and error accumulation. To tackle these limitations, we present a Collaborative Multi-Agent Reasoning Framework that explicitly decouples Semantic Planning from Visual Synthesis. By employing specialized agents for upfront reasoning, our method generates a structured, explicit plan before pixel generation, enabling visually and semantically coherent single-pass synthesis. We integrate this framework with two critical mechanisms: (1) a self-correcting Verification Agent that employs Chain-of-Thought reasoning to rectify visible region segmentation and identify residual occluders strictly within the Semantic Planning phase, and (2) a Diverse Hypothesis Generator that addresses the ambiguity of invisible regions by offering diverse, plausible semantic interpretations, surpassing the limited pixel-level variations of standard random seed sampling. Furthermore, addressing the limitations of traditional metrics in assessing inferred invisible content, we introduce the MAC-Score (MLLM Amodal Completion Score), a novel human-aligned evaluation metric. Validated against human judgment and ground truth, these metrics establish a robust standard for assessing structural completeness and semantic consistency with visible context. Extensive experiments demonstrate that our framework significantly outperforms state-of-the-art methods across multiple datasets. Our project is available at: https://fanhongxing.github.io/remac-page.
RoboTracer: Mastering Spatial Trace with Reasoning in Vision-Language Models for Robotics
Dec 15, 2025Spatial tracing, as a fundamental embodied interaction ability for robots, is inherently challenging as it requires multi-step metric-grounded reasoning compounded with complex spatial referring and real-world metric measurement. However, existing methods struggle with this compositional task. To this end, we propose RoboTracer, a 3D-aware VLM that first achieves both 3D spatial referring and measuring via a universal spatial encoder and a regression-supervised decoder to enhance scale awareness during supervised fine-tuning (SFT). Moreover, RoboTracer advances multi-step metric-grounded reasoning via reinforcement fine-tuning (RFT) with metric-sensitive process rewards, supervising key intermediate perceptual cues to accurately generate spatial traces. To support SFT and RFT training, we introduce TraceSpatial, a large-scale dataset of 30M QA pairs, spanning outdoor/indoor/tabletop scenes and supporting complex reasoning processes (up to 9 steps). We further present TraceSpatial-Bench, a challenging benchmark filling the gap to evaluate spatial tracing. Experimental results show that RoboTracer surpasses baselines in spatial understanding, measuring, and referring, with an average success rate of 79.1%, and also achieves SOTA performance on TraceSpatial-Bench by a large margin, exceeding Gemini-2.5-Pro by 36% accuracy. Notably, RoboTracer can be integrated with various control policies to execute long-horizon, dynamic tasks across diverse robots (UR5, G1 humanoid) in cluttered real-world scenes.
InterMoE: Individual-Specific 3D Human Interaction Generation via Dynamic Temporal-Selective MoE
Nov 17, 2025



Generating high-quality human interactions holds significant value for applications like virtual reality and robotics. However, existing methods often fail to preserve unique individual characteristics or fully adhere to textual descriptions. To address these challenges, we introduce InterMoE, a novel framework built on a Dynamic Temporal-Selective Mixture of Experts. The core of InterMoE is a routing mechanism that synergistically uses both high-level text semantics and low-level motion context to dispatch temporal motion features to specialized experts. This allows experts to dynamically determine the selection capacity and focus on critical temporal features, thereby preserving specific individual characteristic identities while ensuring high semantic fidelity. Extensive experiments show that InterMoE achieves state-of-the-art performance in individual-specific high-fidelity 3D human interaction generation, reducing FID scores by 9% on the InterHuman dataset and 22% on InterX.
TIGeR: Tool-Integrated Geometric Reasoning in Vision-Language Models for Robotics
Oct 08, 2025



Vision-Language Models (VLMs) have shown remarkable capabilities in spatial reasoning, yet they remain fundamentally limited to qualitative precision and lack the computational precision required for real-world robotics. Current approaches fail to leverage metric cues from depth sensors and camera calibration, instead reducing geometric problems to pattern recognition tasks that cannot deliver the centimeter-level accuracy essential for robotic manipulation. We present TIGeR (Tool-Integrated Geometric Reasoning), a novel framework that transforms VLMs from perceptual estimators to geometric computers by enabling them to generate and execute precise geometric computations through external tools. Rather than attempting to internalize complex geometric operations within neural networks, TIGeR empowers models to recognize geometric reasoning requirements, synthesize appropriate computational code, and invoke specialized libraries for exact calculations. To support this paradigm, we introduce TIGeR-300K, a comprehensive tool-invocation-oriented dataset covering point transformations, pose estimation, trajectory generation, and spatial compatibility verification, complete with tool invocation sequences and intermediate computations. Through a two-stage training pipeline combining supervised fine-tuning (SFT) and reinforcement fine-tuning (RFT) with our proposed hierarchical reward design, TIGeR achieves SOTA performance on geometric reasoning benchmarks while demonstrating centimeter-level precision in real-world robotic manipulation tasks.
VoxHammer: Training-Free Precise and Coherent 3D Editing in Native 3D Space
Aug 26, 2025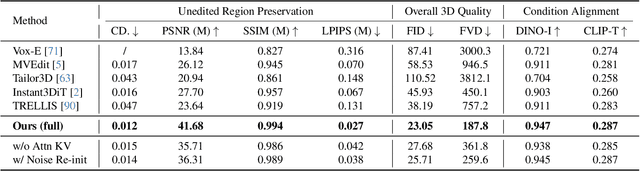
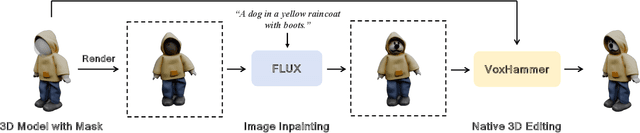

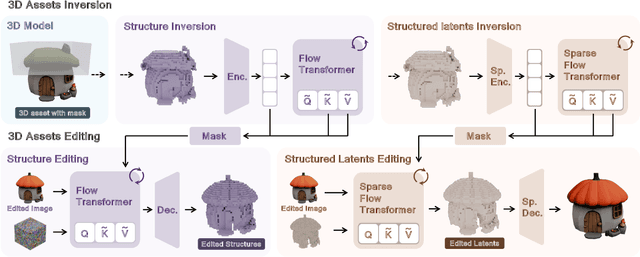
3D local editing of specified regions is crucial for game industry and robot interaction. Recent methods typically edit rendered multi-view images and then reconstruct 3D models, but they face challenges in precisely preserving unedited regions and overall coherence. Inspired by structured 3D generative models, we propose VoxHammer, a novel training-free approach that performs precise and coherent editing in 3D latent space. Given a 3D model, VoxHammer first predicts its inversion trajectory and obtains its inverted latents and key-value tokens at each timestep. Subsequently, in the denoising and editing phase, we replace the denoising features of preserved regions with the corresponding inverted latents and cached key-value tokens. By retaining these contextual features, this approach ensures consistent reconstruction of preserved areas and coherent integration of edited parts. To evaluate the consistency of preserved regions, we constructed Edit3D-Bench, a human-annotated dataset comprising hundreds of samples, each with carefully labeled 3D editing regions. Experiments demonstrate that VoxHammer significantly outperforms existing methods in terms of both 3D consistency of preserved regions and overall quality. Our method holds promise for synthesizing high-quality edited paired data, thereby laying the data foundation for in-context 3D generation. See our project page at https://huanngzh.github.io/VoxHammer-Page/.
AnimaX: Animating the Inanimate in 3D with Joint Video-Pose Diffusion Models
Jun 24, 2025We present AnimaX, a feed-forward 3D animation framework that bridges the motion priors of video diffusion models with the controllable structure of skeleton-based animation. Traditional motion synthesis methods are either restricted to fixed skeletal topologies or require costly optimization in high-dimensional deformation spaces. In contrast, AnimaX effectively transfers video-based motion knowledge to the 3D domain, supporting diverse articulated meshes with arbitrary skeletons. Our method represents 3D motion as multi-view, multi-frame 2D pose maps, and enables joint video-pose diffusion conditioned on template renderings and a textual motion prompt. We introduce shared positional encodings and modality-aware embeddings to ensure spatial-temporal alignment between video and pose sequences, effectively transferring video priors to motion generation task. The resulting multi-view pose sequences are triangulated into 3D joint positions and converted into mesh animation via inverse kinematics. Trained on a newly curated dataset of 160,000 rigged sequences, AnimaX achieves state-of-the-art results on VBench in generalization, motion fidelity, and efficiency, offering a scalable solution for category-agnostic 3D animation. Project page: \href{https://anima-x.github.io/}{https://anima-x.github.io/}.