 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA general tensor-structured compression scheme for efficient large language models
May 25, 2026Large language models (LLMs) are dominated by dense linear transformations, whose storage, memory and computational overheads hinder efficient adaptation and deployment while masking the functional impacts of structural simplification. Here we present Tensor Mixture (MixT), a general tensor-structured compression scheme that replaces targeted dense linear layers with natively executable mixtures of tensor operators. Operating directly on generic linear projections instead of model-specific components, MixT is potentially applicable across Transformer-based LLMs and other dense neural mappings. We evaluate MixT on Qwen3-8B and LLaMA2-7B under a unified recovery protocol, identifying a broad compressible regime in which MMLU accuracy is largely preserved before an abrupt transition at model-specific boundaries. This transition coincides with coordinated shifts in output entropy, prediction entropy and inter-layer geometry. At the LLaMA2-7B transition boundary, MixT reduces full-model parameters by 47.5\%, inference FLOPs by 37.1\%, training FLOPs by 52.1\% and peak inference memory by 60.4\%, demonstrating its practical potential for lower-cost LLM compression.
LiteResearcher: A Scalable Agentic RL Training Framework for Deep Research Agent
Apr 22, 2026Reinforcement Learning (RL) has emerged as a powerful training paradigm for LLM-based agents. However, scaling agentic RL for deep research remains constrained by two coupled challenges: hand-crafted synthetic data fails to elicit genuine real-world search capabilities, and real-world search dependency during RL training introduces instability and prohibitive cost, which limits the scalability of Agentic RL. LiteResearcher is a training framework that makes Agentic RL scalable: by constructing a lite virtual world that mirrors real-world search dynamics, we enable a continuously improving training recipe that empowers a tiny search agent to outperform large-scale open-source and commercial models (e.g., Tongyi DeepResearch and Claude-4.5 Sonnet). Specifically, on common benchmarks such as GAIA and Xbench, our LiteResearcher-4B achieves open-source state-of-the-art results of 71.3% and 78.0% respectively, demonstrating that scalable RL training is a key enabler for Deep Research Agents.
TrafficClaw: Generalizable Urban Traffic Control via Unified Physical Environment Modeling
Apr 19, 2026Urban traffic control is a system-level coordination problem spanning heterogeneous subsystems, including traffic signals, freeways, public transit, and taxi services. Existing optimization-based, reinforcement learning (RL), and emerging LLM-based approaches are largely designed for isolated tasks, limiting both cross-task generalization and the ability to capture coupled physical dynamics across subsystems. We argue that effective system-level control requires a unified physical environment in which subsystems share infrastructure, mobility demand, and spatiotemporal constraints, allowing local interventions to propagate through the network. To this end, we propose TrafficClaw, a framework for general urban traffic control built upon a unified runtime environment. TrafficClaw integrates heterogeneous subsystems into a shared dynamical system, enabling explicit modeling of cross-subsystem interactions and closed-loop agent-environment feedback. Within this environment, we develop an LLM agent with executable spatiotemporal reasoning and reusable procedural memory, supporting unified diagnostics across subsystems and continual strategy refinement. Furthermore, we introduce a multi-stage training pipeline with supervised initialization and agentic RL with system-level optimization, further enabling coordinated and system-aware performance. Experiments demonstrate that TrafficClaw achieves robust, transferable, and system-aware performance across unseen traffic scenarios, dynamics, and task configurations. Our project is available at https://github.com/usail-hkust/TrafficClaw.
Talk2DM: Enabling Natural Language Querying and Commonsense Reasoning for Vehicle-Road-Cloud Integrated Dynamic Maps with Large Language Models
Feb 12, 2026Dynamic maps (DM) serve as the fundamental information infrastructure for vehicle-road-cloud (VRC) cooperative autonomous driving in China and Japan. By providing comprehensive traffic scene representations, DM overcome the limitations of standalone autonomous driving systems (ADS), such as physical occlusions. Although DM-enhanced ADS have been successfully deployed in real-world applications in Japan, existing DM systems still lack a natural-language-supported (NLS) human interface, which could substantially enhance human-DM interaction. To address this gap, this paper introduces VRCsim, a VRC cooperative perception (CP) simulation framework designed to generate streaming VRC-CP data. Based on VRCsim, we construct a question-answering data set, VRC-QA, focused on spatial querying and reasoning in mixed-traffic scenes. Building upon VRCsim and VRC-QA, we further propose Talk2DM, a plug-and-play module that extends VRC-DM systems with NLS querying and commonsense reasoning capabilities. Talk2DM is built upon a novel chain-of-prompt (CoP) mechanism that progressively integrates human-defined rules with the commonsense knowledge of large language models (LLMs). Experiments on VRC-QA show that Talk2DM can seamlessly switch across different LLMs while maintaining high NLS query accuracy, demonstrating strong generalization capability. Although larger models tend to achieve higher accuracy, they incur significant efficiency degradation. Our results reveal that Talk2DM, powered by Qwen3:8B, Gemma3:27B, and GPT-oss models, achieves over 93\% NLS query accuracy with an average response time of only 2-5 seconds, indicating strong practical potential.
Tracking large chemical reaction networks and rare events by neural networks
Dec 13, 2025Chemical reaction networks are widely used to model stochastic dynamics in chemical kinetics, systems biology and epidemiology. Solving the chemical master equation that governs these systems poses a significant challenge due to the large state space exponentially growing with system sizes. The development of autoregressive neural networks offers a flexible framework for this problem; however, its efficiency is limited especially for high-dimensional systems and in scenarios with rare events. Here, we push the frontier of neural-network approach by exploiting faster optimizations such as natural gradient descent and time-dependent variational principle, achieving a 5- to 22-fold speedup, and by leveraging enhanced-sampling strategies to capture rare events. We demonstrate reduced computational cost and higher accuracy over the previous neural-network method in challenging reaction networks, including the mitogen-activated protein kinase (MAPK) cascade network, the hitherto largest biological network handled by the previous approaches of solving the chemical master equation. We further apply the approach to spatially extended reaction-diffusion systems, the Schlögl model with rare events, on two-dimensional lattices, beyond the recent tensor-network approach that handles one-dimensional lattices. The present approach thus enables efficient modeling of chemical reaction networks in general.
Inverse Knowledge Search over Verifiable Reasoning: Synthesizing a Scientific Encyclopedia from a Long Chains-of-Thought Knowledge Base
Oct 30, 2025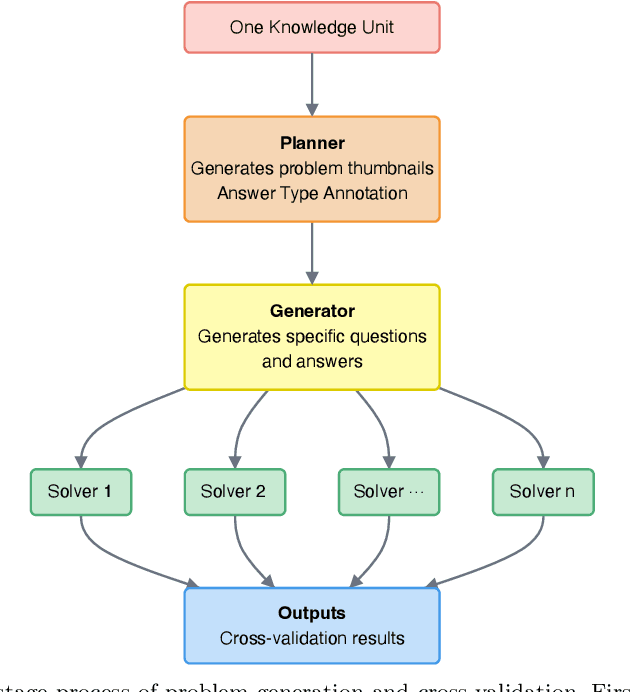
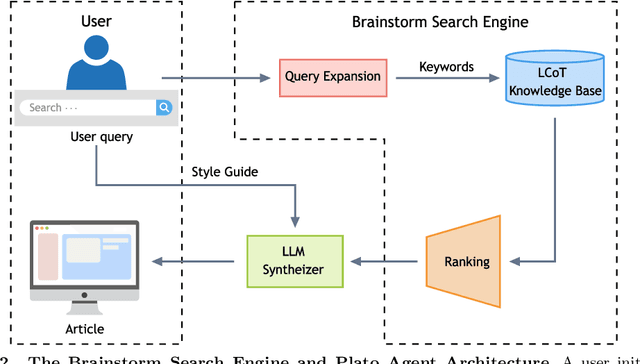
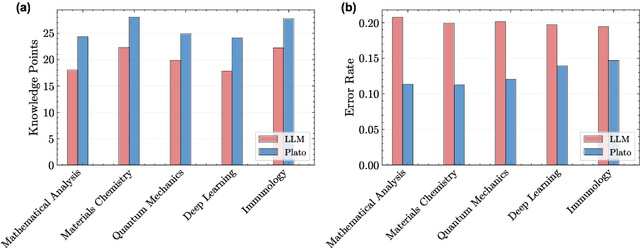
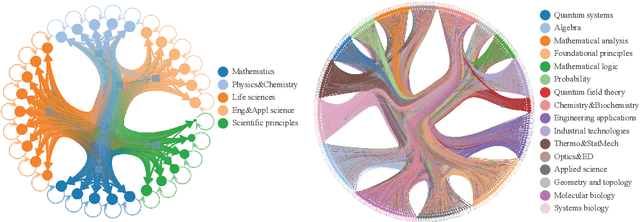
Most scientific materials compress reasoning, presenting conclusions while omitting the derivational chains that justify them. This compression hinders verification by lacking explicit, step-wise justifications and inhibits cross-domain links by collapsing the very pathways that establish the logical and causal connections between concepts. We introduce a scalable framework that decompresses scientific reasoning, constructing a verifiable Long Chain-of-Thought (LCoT) knowledge base and projecting it into an emergent encyclopedia, SciencePedia. Our pipeline operationalizes an endpoint-driven, reductionist strategy: a Socratic agent, guided by a curriculum of around 200 courses, generates approximately 3 million first-principles questions. To ensure high fidelity, multiple independent solver models generate LCoTs, which are then rigorously filtered by prompt sanitization and cross-model answer consensus, retaining only those with verifiable endpoints. This verified corpus powers the Brainstorm Search Engine, which performs inverse knowledge search -- retrieving diverse, first-principles derivations that culminate in a target concept. This engine, in turn, feeds the Plato synthesizer, which narrates these verified chains into coherent articles. The initial SciencePedia comprises approximately 200,000 fine-grained entries spanning mathematics, physics, chemistry, biology, engineering, and computation. In evaluations across six disciplines, Plato-synthesized articles (conditioned on retrieved LCoTs) exhibit substantially higher knowledge-point density and significantly lower factual error rates than an equally-prompted baseline without retrieval (as judged by an external LLM). Built on this verifiable LCoT knowledge base, this reasoning-centric approach enables trustworthy, cross-domain scientific synthesis at scale and establishes the foundation for an ever-expanding encyclopedia.
Quantum Flow Matching
Aug 17, 2025



Flow matching has rapidly become a dominant paradigm in classical generative modeling, offering an efficient way to interpolate between two complex distributions. We extend this idea to the quantum realm and introduce Quantum Flow Matching (QFM)-a fully quantum-circuit realization that offers efficient interpolation between two density matrices. QFM offers systematic preparation of density matrices and generation of samples for accurately estimating observables, and can be realized on a quantum computer without the need for costly circuit redesigns. We validate its versatility on a set of applications: (i) generating target states with prescribed magnetization and entanglement entropy, (ii) estimating nonequilibrium free-energy differences to test the quantum Jarzynski equality, and (iii) expediting the study on superdiffusion breakdown. These results position QFM as a unifying and promising framework for generative modeling across quantum systems.
ScaleCap: Inference-Time Scalable Image Captioning via Dual-Modality Debiasing
Jun 24, 2025
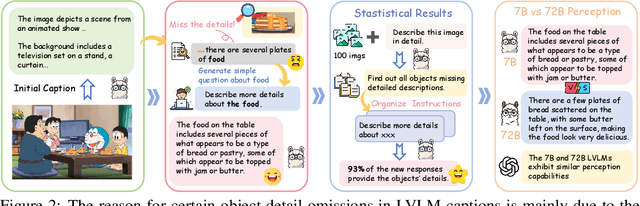

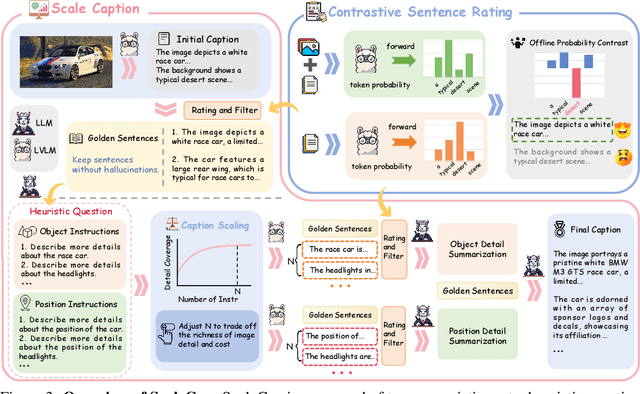
This paper presents ScaleCap, an inference-time scalable image captioning strategy that generates comprehensive and detailed image captions. The key challenges of high-quality image captioning lie in the inherent biases of LVLMs: multimodal bias resulting in imbalanced descriptive granularity, offering detailed accounts of some elements while merely skimming over others; linguistic bias leading to hallucinated descriptions of non-existent objects. To address these issues, we propose a scalable debiased captioning strategy, which continuously enriches and calibrates the caption with increased inference budget. Specifically, we propose two novel components: heuristic question answering and contrastive sentence rating. The former generates content-specific questions based on the image and answers them to progressively inject relevant information into the caption. The latter employs sentence-level offline contrastive decoding to effectively identify and eliminate hallucinations caused by linguistic biases. With increased inference cost, more heuristic questions are raised by ScaleCap to progressively capture additional visual details, generating captions that are more accurate, balanced, and informative. Extensive modality alignment experiments demonstrate the effectiveness of ScaleCap. Annotating 450K images with ScaleCap and using them for LVLM pretraining leads to consistent performance gains across 11 widely used benchmarks. Furthermore, ScaleCap showcases superb richness and fidelity of generated captions with two additional tasks: replacing images with captions in VQA task, and reconstructing images from captions to assess semantic coverage. Code is available at https://github.com/Cooperx521/ScaleCap.
Towards Storage-Efficient Visual Document Retrieval: An Empirical Study on Reducing Patch-Level Embeddings
Jun 05, 2025Despite the strong performance of ColPali/ColQwen2 in Visualized Document Retrieval (VDR), it encodes each page into multiple patch-level embeddings and leads to excessive memory usage. This empirical study investigates methods to reduce patch embeddings per page at minimum performance degradation. We evaluate two token-reduction strategies: token pruning and token merging. Regarding token pruning, we surprisingly observe that a simple random strategy outperforms other sophisticated pruning methods, though still far from satisfactory. Further analysis reveals that pruning is inherently unsuitable for VDR as it requires removing certain page embeddings without query-specific information. Turning to token merging (more suitable for VDR), we search for the optimal combinations of merging strategy across three dimensions and develop Light-ColPali/ColQwen2. It maintains 98.2% of retrieval performance with only 11.8% of original memory usage, and preserves 94.6% effectiveness at 2.8% memory footprint. We expect our empirical findings and resulting Light-ColPali/ColQwen2 offer valuable insights and establish a competitive baseline for future research towards efficient VDR.
MM-IFEngine: Towards Multimodal Instruction Following
Apr 10, 2025The Instruction Following (IF) ability measures how well Multi-modal Large Language Models (MLLMs) understand exactly what users are telling them and whether they are doing it right. Existing multimodal instruction following training data is scarce, the benchmarks are simple with atomic instructions, and the evaluation strategies are imprecise for tasks demanding exact output constraints. To address this, we present MM-IFEngine, an effective pipeline to generate high-quality image-instruction pairs. Our MM-IFEngine pipeline yields large-scale, diverse, and high-quality training data MM-IFInstruct-23k, which is suitable for Supervised Fine-Tuning (SFT) and extended as MM-IFDPO-23k for Direct Preference Optimization (DPO). We further introduce MM-IFEval, a challenging and diverse multi-modal instruction-following benchmark that includes (1) both compose-level constraints for output responses and perception-level constraints tied to the input images, and (2) a comprehensive evaluation pipeline incorporating both rule-based assessment and judge model. We conduct SFT and DPO experiments and demonstrate that fine-tuning MLLMs on MM-IFInstruct-23k and MM-IFDPO-23k achieves notable gains on various IF benchmarks, such as MM-IFEval (+10.2$\%$), MIA (+7.6$\%$), and IFEval (+12.3$\%$). The full data and evaluation code will be released on https://github.com/SYuan03/MM-IFEngine.