 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Achieving Human Parity on Visual Question Answering
Nov 18, 2021

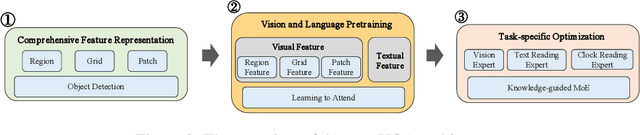
The Visual Question Answering (VQA) task utilizes both visual image and language analysis to answer a textual question with respect to an image. It has been a popular research topic with an increasing number of real-world applications in the last decade. This paper describes our recent research of AliceMind-MMU (ALIbaba's Collection of Encoder-decoders from Machine IntelligeNce lab of Damo academy - MultiMedia Understanding) that obtains similar or even slightly better results than human being does on VQA. This is achieved by systematically improving the VQA pipeline including: (1) pre-training with comprehensive visual and textual feature representation; (2) effective cross-modal interaction with learning to attend; and (3) A novel knowledge mining framework with specialized expert modules for the complex VQA task. Treating different types of visual questions with corresponding expertise needed plays an important role in boosting the performance of our VQA architecture up to the human level. An extensive set of experiments and analysis are conducted to demonstrate the effectiveness of the new research work.
ODMTCNet: An Interpretable Multi-view Deep Neural Network Architecture for Image Feature Representation
Oct 28, 2021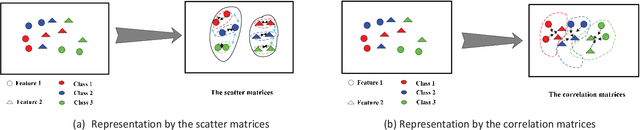
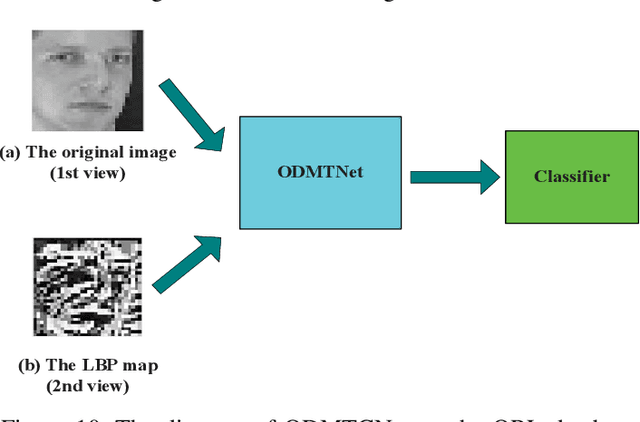

This work proposes an interpretable multi-view deep neural network architecture, namely optimal discriminant multi-view tensor convolutional network (ODMTCNet), by integrating statistical machine learning (SML) principles with the deep neural network (DNN) architecture.
VRT: A Video Restoration Transformer
Jan 28, 2022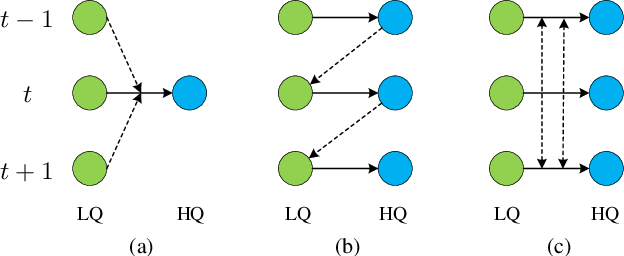
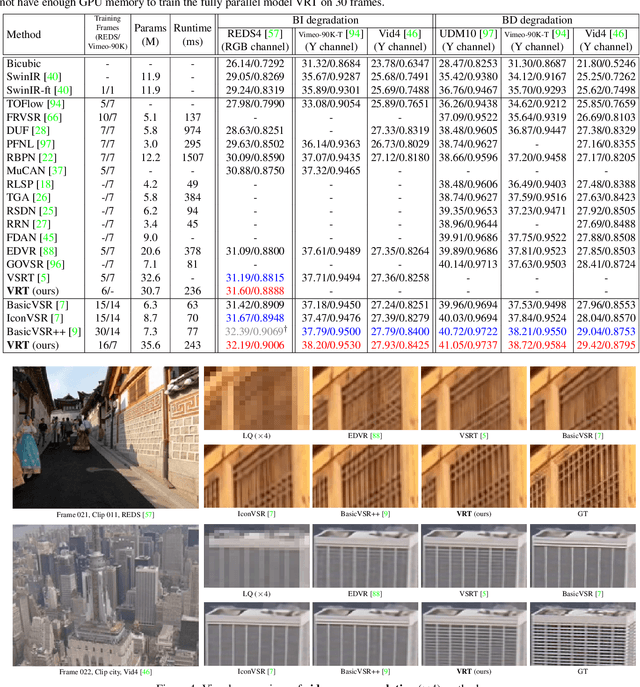
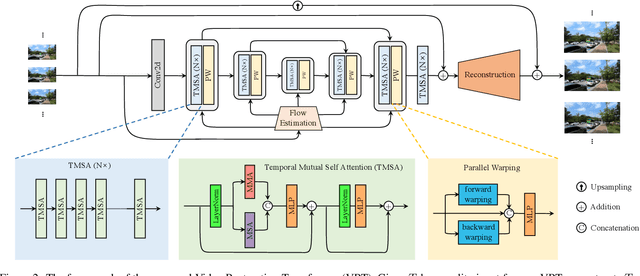
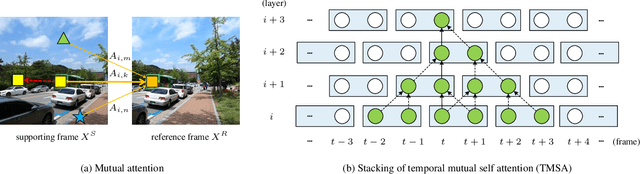
Video restoration (e.g., video super-resolution) aims to restore high-quality frames from low-quality frames. Different from single image restoration, video restoration generally requires to utilize temporal information from multiple adjacent but usually misaligned video frames. Existing deep methods generally tackle with this by exploiting a sliding window strategy or a recurrent architecture, which either is restricted by frame-by-frame restoration or lacks long-range modelling ability. In this paper, we propose a Video Restoration Transformer (VRT) with parallel frame prediction and long-range temporal dependency modelling abilities. More specifically, VRT is composed of multiple scales, each of which consists of two kinds of modules: temporal mutual self attention (TMSA) and parallel warping. TMSA divides the video into small clips, on which mutual attention is applied for joint motion estimation, feature alignment and feature fusion, while self attention is used for feature extraction. To enable cross-clip interactions, the video sequence is shifted for every other layer. Besides, parallel warping is used to further fuse information from neighboring frames by parallel feature warping. Experimental results on three tasks, including video super-resolution, video deblurring and video denoising, demonstrate that VRT outperforms the state-of-the-art methods by large margins ($\textbf{up to 2.16dB}$) on nine benchmark datasets.
COVID-19 Prognosis via Self-Supervised Representation Learning and Multi-Image Prediction
Jan 25, 2021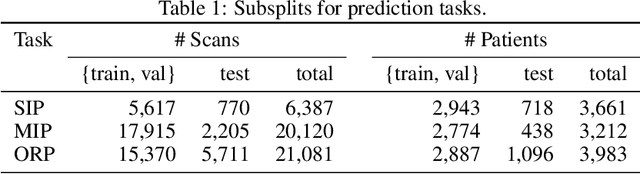
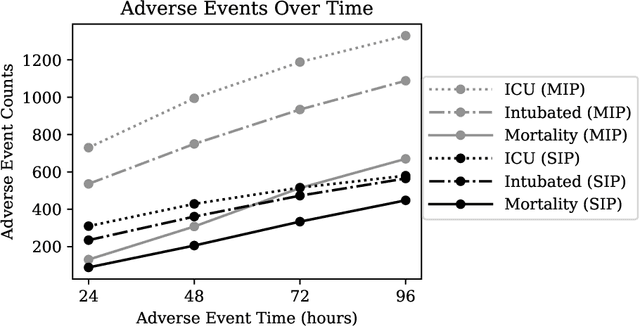
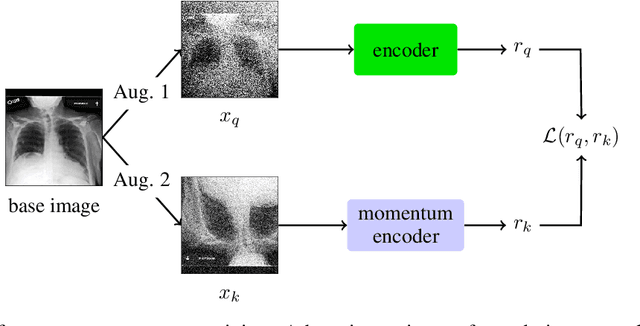
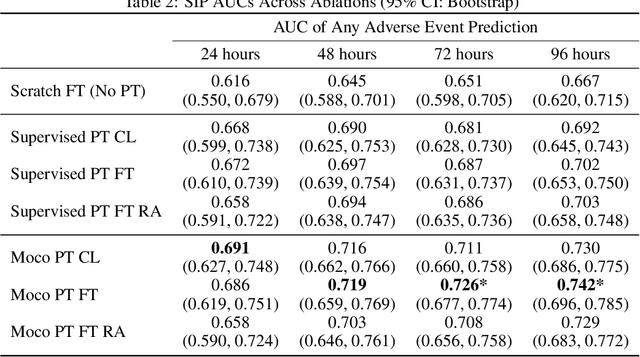
The rapid spread of COVID-19 cases in recent months has strained hospital resources, making rapid and accurate triage of patients presenting to emergency departments a necessity. Machine learning techniques using clinical data such as chest X-rays have been used to predict which patients are most at risk of deterioration. We consider the task of predicting two types of patient deterioration based on chest X-rays: adverse event deterioration (i.e., transfer to the intensive care unit, intubation, or mortality) and increased oxygen requirements beyond 6 L per day. Due to the relative scarcity of COVID-19 patient data, existing solutions leverage supervised pretraining on related non-COVID images, but this is limited by the differences between the pretraining data and the target COVID-19 patient data. In this paper, we use self-supervised learning based on the momentum contrast (MoCo) method in the pretraining phase to learn more general image representations to use for downstream tasks. We present three results. The first is deterioration prediction from a single image, where our model achieves an area under receiver operating characteristic curve (AUC) of 0.742 for predicting an adverse event within 96 hours (compared to 0.703 with supervised pretraining) and an AUC of 0.765 for predicting oxygen requirements greater than 6 L a day at 24 hours (compared to 0.749 with supervised pretraining). We then propose a new transformer-based architecture that can process sequences of multiple images for prediction and show that this model can achieve an improved AUC of 0.786 for predicting an adverse event at 96 hours and an AUC of 0.848 for predicting mortalities at 96 hours. A small pilot clinical study suggested that the prediction accuracy of our model is comparable to that of experienced radiologists analyzing the same information.
MUST-GAN: Multi-level Statistics Transfer for Self-driven Person Image Generation
Nov 23, 2020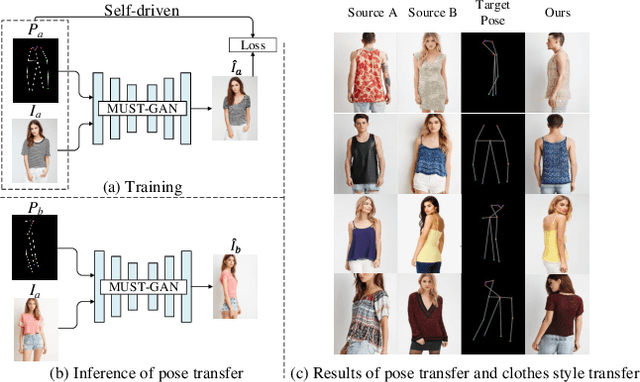
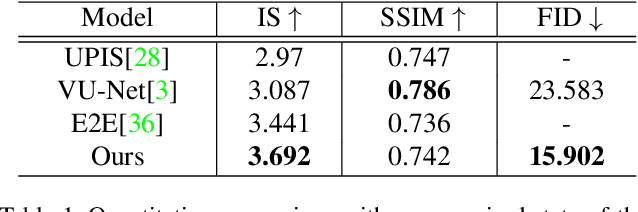
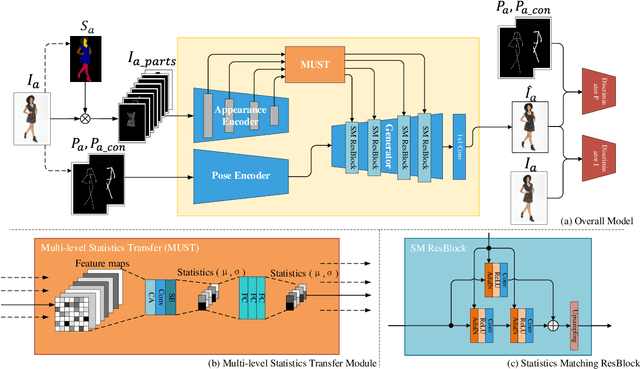
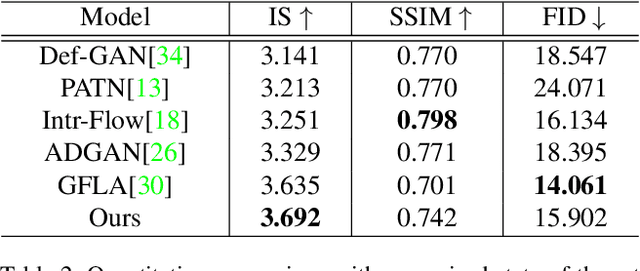
Pose-guided person image generation usually involves using paired source-target images to supervise the training, which significantly increases the data preparation effort and limits the application of the models. To deal with this problem, we propose a novel multi-level statistics transfer model, which disentangles and transfers multi-level appearance features from person images and merges them with pose features to reconstruct the source person images themselves. So that the source images can be used as supervision for self-driven person image generation. Specifically, our model extracts multi-level features from the appearance encoder and learns the optimal appearance representation through attention mechanism and attributes statistics. Then we transfer them to a pose-guided generator for re-fusion of appearance and pose. Our approach allows for flexible manipulation of person appearance and pose properties to perform pose transfer and clothes style transfer tasks. Experimental results on the DeepFashion dataset demonstrate our method's superiority compared with state-of-the-art supervised and unsupervised methods. In addition, our approach also performs well in the wild.
Enhanced Balancing GAN: Minority-class Image Generation
Oct 31, 2020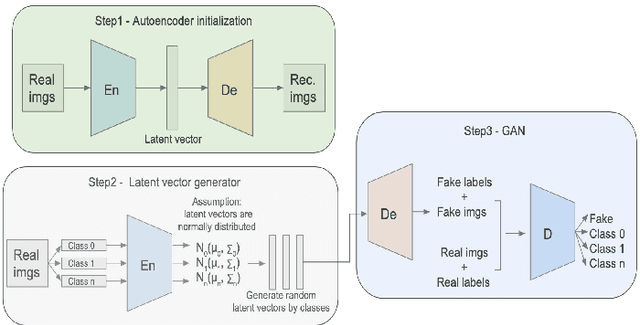
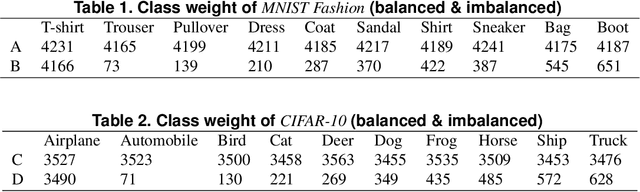
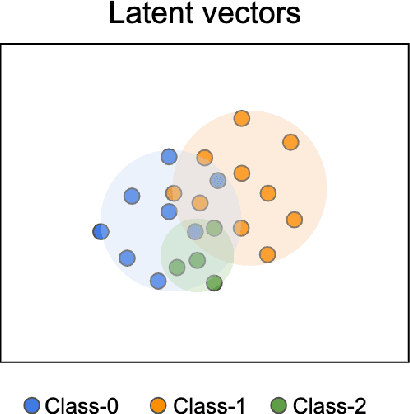
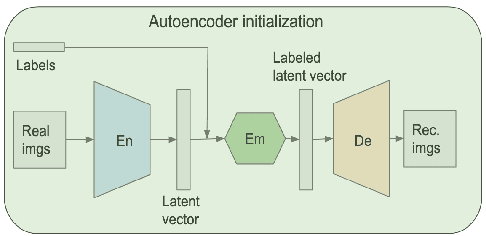
Generative adversarial networks (GANs) are one of the most powerful generative models, but always require a large and balanced dataset to train. Traditional GANs are not applicable to generate minority-class images in a highly imbalanced dataset. Balancing GAN (BAGAN) is proposed to mitigate this problem, but it is unstable when images in different classes look similar, e.g. flowers and cells. In this work, we propose a supervised autoencoder with an intermediate embedding model to disperse the labeled latent vectors. With the improved autoencoder initialization, we also build an architecture of BAGAN with gradient penalty (BAGAN-GP). Our proposed model overcomes the unstable issue in original BAGAN and converges faster to high quality generations. Our model achieves high performance on the imbalanced scale-down version of MNIST Fashion, CIFAR-10, and one small-scale medical image dataset.
From data to functa: Your data point is a function and you should treat it like one
Jan 28, 2022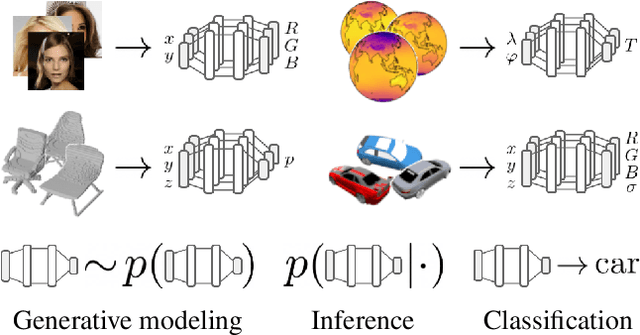
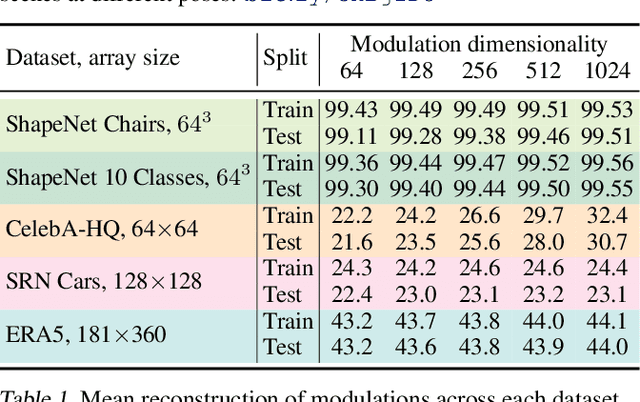


It is common practice in deep learning to represent a measurement of the world on a discrete grid, e.g. a 2D grid of pixels. However, the underlying signal represented by these measurements is often continuous, e.g. the scene depicted in an image. A powerful continuous alternative is then to represent these measurements using an implicit neural representation, a neural function trained to output the appropriate measurement value for any input spatial location. In this paper, we take this idea to its next level: what would it take to perform deep learning on these functions instead, treating them as data? In this context we refer to the data as functa, and propose a framework for deep learning on functa. This view presents a number of challenges around efficient conversion from data to functa, compact representation of functa, and effectively solving downstream tasks on functa. We outline a recipe to overcome these challenges and apply it to a wide range of data modalities including images, 3D shapes, neural radiance fields (NeRF) and data on manifolds. We demonstrate that this approach has various compelling properties across data modalities, in particular on the canonical tasks of generative modeling, data imputation, novel view synthesis and classification.
Automatic Identification of the End-Diastolic and End-Systolic Cardiac Frames from Invasive Coronary Angiography Videos
Oct 06, 2021
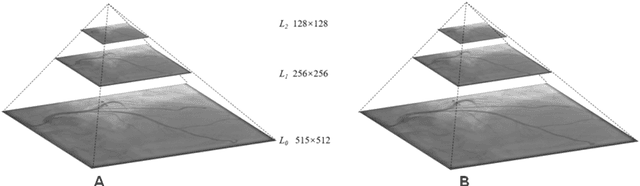
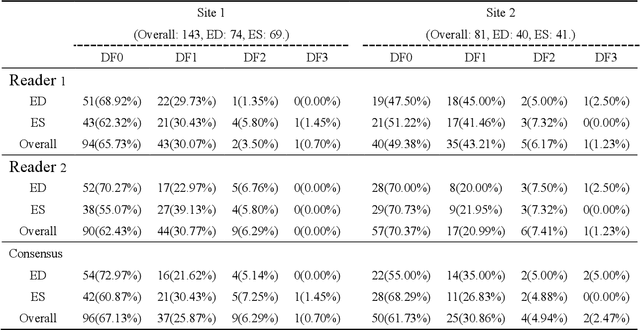
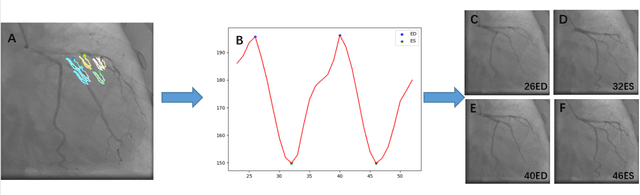
Automatic identification of proper image frames at the end-diastolic (ED) and end-systolic (ES) frames during the review of invasive coronary angiograms (ICA) is important to assess blood flow during a cardiac cycle, reconstruct the 3D arterial anatomy from bi-planar views, and generate the complementary fusion map with myocardial images. The current identification method primarily relies on visual interpretation, making it not only time-consuming but also less reproducible. In this paper, we propose a new method to automatically identify angiographic image frames associated with the ED and ES cardiac phases by using the trajectories of key vessel points (i.e. landmarks). More specifically, a detection algorithm is first used to detect the key points of coronary arteries, and then an optical flow method is employed to track the trajectories of the selected key points. The ED and ES frames are identified based on all these trajectories. Our method was tested with 62 ICA videos from two separate medical centers (22 and 9 patients in sites 1 and 2, respectively). Comparing consensus interpretations by two human expert readers, excellent agreement was achieved by the proposed algorithm: the agreement rates within a one-frame range were 92.99% and 92.73% for the automatic identification of the ED and ES image frames, respectively. In conclusion, the proposed automated method showed great potential for being an integral part of automated ICA image analysis.
QU-BraTS: MICCAI BraTS 2020 Challenge on Quantifying Uncertainty in Brain Tumor Segmentation -- Analysis of Ranking Metrics and Benchmarking Results
Dec 19, 2021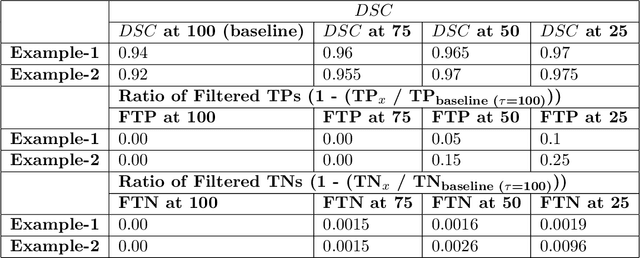
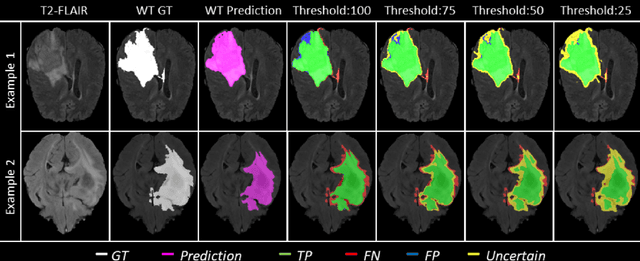
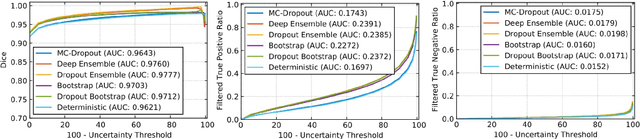
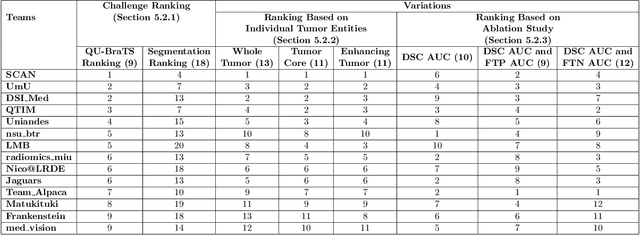
Deep learning (DL) models have provided the state-of-the-art performance in a wide variety of medical imaging benchmarking challenges, including the Brain Tumor Segmentation (BraTS) challenges. However, the task of focal pathology multi-compartment segmentation (e.g., tumor and lesion sub-regions) is particularly challenging, and potential errors hinder the translation of DL models into clinical workflows. Quantifying the reliability of DL model predictions in the form of uncertainties, could enable clinical review of the most uncertain regions, thereby building trust and paving the way towards clinical translation. Recently, a number of uncertainty estimation methods have been introduced for DL medical image segmentation tasks. Developing metrics to evaluate and compare the performance of uncertainty measures will assist the end-user in making more informed decisions. In this study, we explore and evaluate a metric developed during the BraTS 2019-2020 task on uncertainty quantification (QU-BraTS), and designed to assess and rank uncertainty estimates for brain tumor multi-compartment segmentation. This metric (1) rewards uncertainty estimates that produce high confidence in correct assertions, and those that assign low confidence levels at incorrect assertions, and (2) penalizes uncertainty measures that lead to a higher percentages of under-confident correct assertions. We further benchmark the segmentation uncertainties generated by 14 independent participating teams of QU-BraTS 2020, all of which also participated in the main BraTS segmentation task. Overall, our findings confirm the importance and complementary value that uncertainty estimates provide to segmentation algorithms, and hence highlight the need for uncertainty quantification in medical image analyses. Our evaluation code is made publicly available at https://github.com/RagMeh11/QU-BraTS.
Critical configurations for three projective views
Dec 10, 2021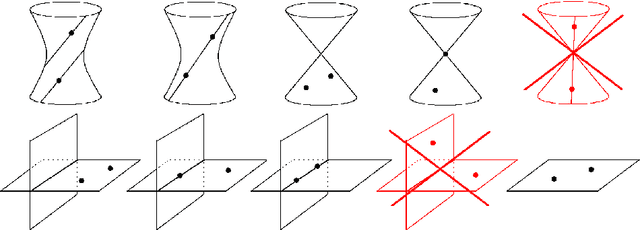
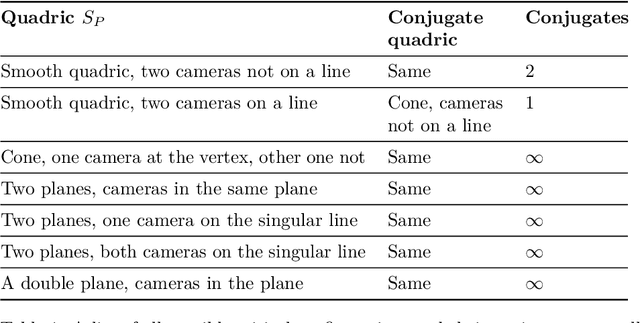
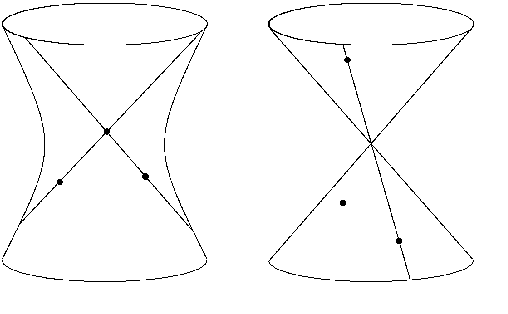
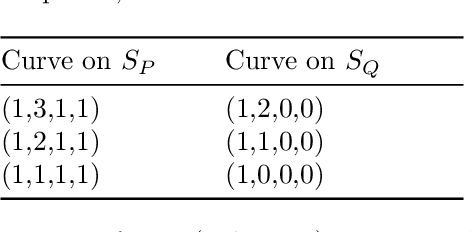
The problem of structure from motion is concerned with recovering the 3-dimensional structure of an object from a set of 2-dimensional images. Generally, all information can be uniquely recovered if enough images and image points are provided, yet there are certain cases where unique recovery is impossible; these are called critical configurations. In this paper we use an algebraic approach to study the critical configurations for three projective cameras. We show that all critical configurations lie on the intersection of quadric surfaces, and classify exactly which intersections constitute a critical configuration.