 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBifDet: A 3D Bifurcation Detection Dataset for Airway-Tree Modeling
Apr 27, 2026Thoracic Computed Tomography (CT) scans offer detailed insights into the intricate branching network of the airway tree, which is essential for understanding various respiratory diseases. Airway bifurcations, where airway branches split, are crucial landmarks for understanding lung physiology, disease mechanisms and lesion localization. Despite the significance of bifurcation analysis, a notable lack of datasets annotated for this task hinders the development of advanced automated specialized detection or segmentation tools. In this paper, we introduce BifDet, the first publicly-available dataset specialized for 3D airway bifurcation detection, filling a critical gap in existing resources. Our dataset comprises carefully annotated CT scans from the ATM22 open-access cohort with bifurcation bounding boxes covering the parent and daughter branches. As a use-case for demonstrating the potential of BifDet, we fine-tune and evaluate RetinaNet and DETR for 3D airway bifurcations detection on CT scans. We provide detailed pipelines, including preprocessing steps and specific implementation design choices. Results are detailed over various categories of minimal bounding box sizes to serve as baseline to benchmark future research.
Leveraging whole slide difficulty in Multiple Instance Learning to improve prostate cancer grading
Mar 10, 2026Multiple Instance Learning (MIL) has been widely applied in histopathology to classify Whole Slide Images (WSIs) with slide-level diagnoses. While the ground truth is established by expert pathologists, the slides can be difficult to diagnose for non-experts and lead to disagreements between the annotators. In this paper, we introduce the notion of Whole Slide Difficulty (WSD), based on the disagreement between an expert and a non-expert pathologist. We propose two different methods to leverage WSD, a multi-task approach and a weighted classification loss approach, and we apply them to Gleason grading of prostate cancer slides. Results show that integrating WSD during training consistently improves the classification performance across different feature encoders and MIL methods, particularly for higher Gleason grades (i.e. worse diagnosis).
SINETRA: a Versatile Framework for Evaluating Single Neuron Tracking in Behaving Animals
Nov 14, 2024Accurately tracking neuronal activity in behaving animals presents significant challenges due to complex motions and background noise. The lack of annotated datasets limits the evaluation and improvement of such tracking algorithms. To address this, we developed SINETRA, a versatile simulator that generates synthetic tracking data for particles on a deformable background, closely mimicking live animal recordings. This simulator produces annotated 2D and 3D videos that reflect the intricate movements seen in behaving animals like Hydra Vulgaris. We evaluated four state-of-the-art tracking algorithms highlighting the current limitations of these methods in challenging scenarios and paving the way for improved cell tracking techniques in dynamic biological systems.
Curriculum Learning for Few-Shot Domain Adaptation in CT-based Airway Tree Segmentation
Nov 08, 2024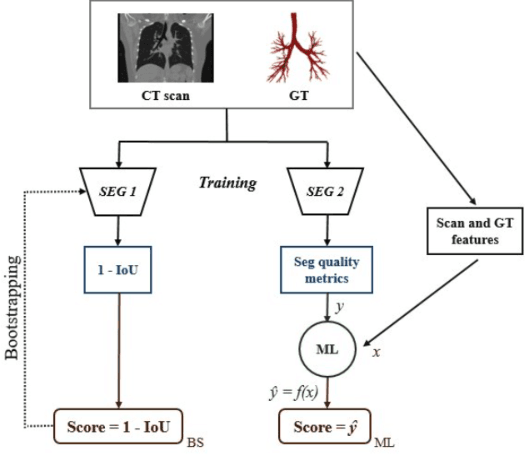
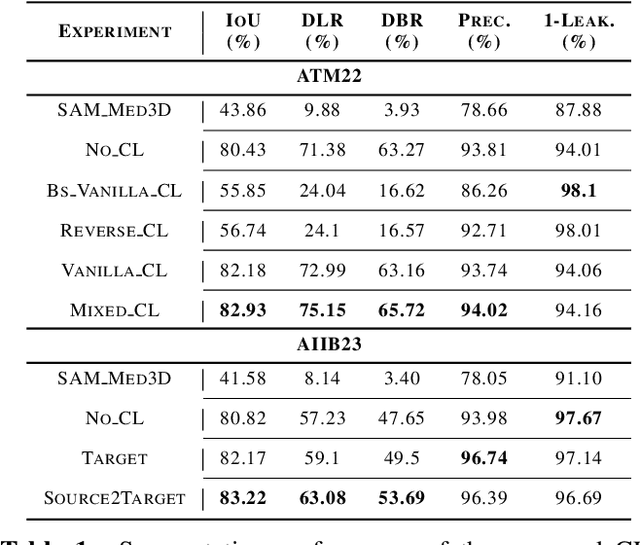
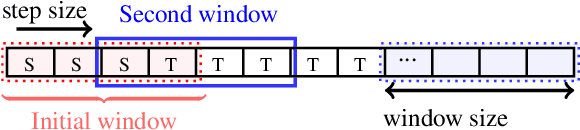
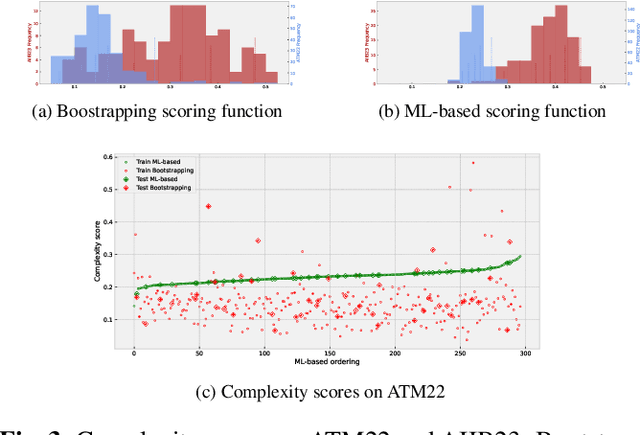
Despite advances with deep learning (DL), automated airway segmentation from chest CT scans continues to face challenges in segmentation quality and generalization across cohorts. To address these, we propose integrating Curriculum Learning (CL) into airway segmentation networks, distributing the training set into batches according to ad-hoc complexity scores derived from CT scans and corresponding ground-truth tree features. We specifically investigate few-shot domain adaptation, targeting scenarios where manual annotation of a full fine-tuning dataset is prohibitively expensive. Results are reported on two large open-cohorts (ATM22 and AIIB23) with high performance using CL for full training (Source domain) and few-shot fine-tuning (Target domain), but with also some insights on potential detrimental effects if using a classic Bootstrapping scoring function or if not using proper scan sequencing.
Dense Self-Supervised Learning for Medical Image Segmentation
Jul 29, 2024



Deep learning has revolutionized medical image segmentation, but it relies heavily on high-quality annotations. The time, cost and expertise required to label images at the pixel-level for each new task has slowed down widespread adoption of the paradigm. We propose Pix2Rep, a self-supervised learning (SSL) approach for few-shot segmentation, that reduces the manual annotation burden by learning powerful pixel-level representations directly from unlabeled images. Pix2Rep is a novel pixel-level loss and pre-training paradigm for contrastive SSL on whole images. It is applied to generic encoder-decoder deep learning backbones (e.g., U-Net). Whereas most SSL methods enforce invariance of the learned image-level representations under intensity and spatial image augmentations, Pix2Rep enforces equivariance of the pixel-level representations. We demonstrate the framework on a task of cardiac MRI segmentation. Results show improved performance compared to existing semi- and self-supervised approaches; and a 5-fold reduction in the annotation burden for equivalent performance versus a fully supervised U-Net baseline. This includes a 30% (resp. 31%) DICE improvement for one-shot segmentation under linear-probing (resp. fine-tuning). Finally, we also integrate the novel Pix2Rep concept with the Barlow Twins non-contrastive SSL, which leads to even better segmentation performance.
Deep ContourFlow: Advancing Active Contours with Deep Learning
Jul 15, 2024



This paper introduces a novel approach that combines unsupervised active contour models with deep learning for robust and adaptive image segmentation. Indeed, traditional active contours, provide a flexible framework for contour evolution and learning offers the capacity to learn intricate features and patterns directly from raw data. Our proposed methodology leverages the strengths of both paradigms, presenting a framework for both unsupervised and one-shot approaches for image segmentation. It is capable of capturing complex object boundaries without the need for extensive labeled training data. This is particularly required in histology, a field facing a significant shortage of annotations due to the challenging and time-consuming nature of the annotation process. We illustrate and compare our results to state of the art methods on a histology dataset and show significant improvements.
Few-Shot Airway-Tree Modeling using Data-Driven Sparse Priors
Jul 05, 2024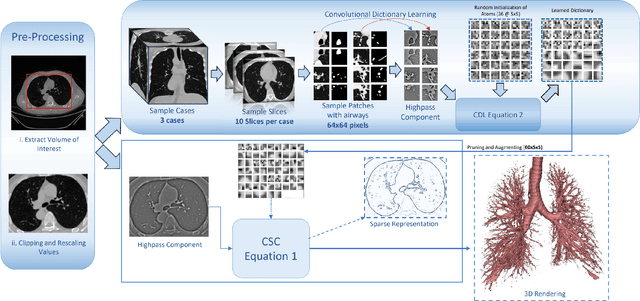
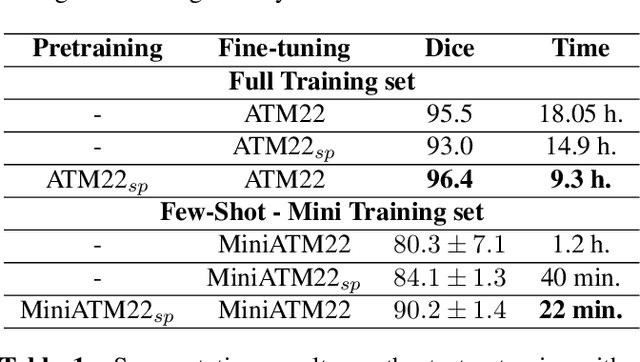
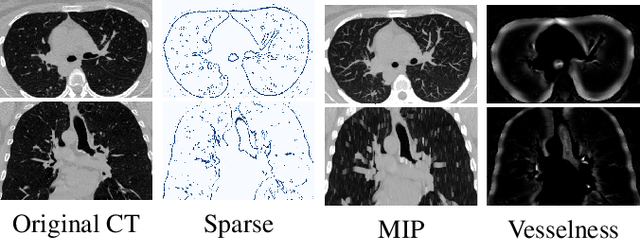
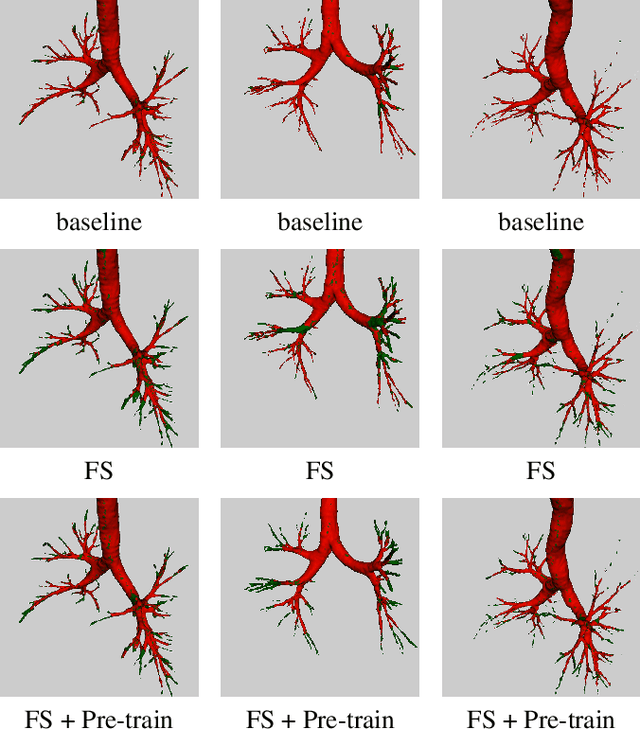
The lack of large annotated datasets in medical imaging is an intrinsic burden for supervised Deep Learning (DL) segmentation models. Few-shot learning approaches are cost-effective solutions to transfer pre-trained models using only limited annotated data. However, such methods can be prone to overfitting due to limited data diversity especially when segmenting complex, diverse, and sparse tubular structures like airways. Furthermore, crafting informative image representations has played a crucial role in medical imaging, enabling discriminative enhancement of anatomical details. In this paper, we initially train a data-driven sparsification module to enhance airways efficiently in lung CT scans. We then incorporate these sparse representations in a standard supervised segmentation pipeline as a pretraining step to enhance the performance of the DL models. Results presented on the ATM public challenge cohort show the effectiveness of using sparse priors in pre-training, leading to segmentation Dice score increase by 1% to 10% in full-scale and few-shot learning scenarios, respectively.
Push the Boundary of SAM: A Pseudo-label Correction Framework for Medical Segmentation
Aug 02, 2023Segment anything model (SAM) has emerged as the leading approach for zero-shot learning in segmentation, offering the advantage of avoiding pixel-wise annotation. It is particularly appealing in medical image segmentation where annotation is laborious and expertise-demanding. However, the direct application of SAM often yields inferior results compared to conventional fully supervised segmentation networks. While using SAM generated pseudo label could also benefit the training of fully supervised segmentation, the performance is limited by the quality of pseudo labels. In this paper, we propose a novel label corruption to push the boundary of SAM-based segmentation. Our model utilizes a novel noise detection module to distinguish between noisy labels from clean labels. This enables us to correct the noisy labels using an uncertainty-based self-correction module, thereby enriching the clean training set. Finally, we retrain the network with updated labels to optimize its weights for future predictions. One key advantage of our model is its ability to train deep networks using SAM-generated pseudo labels without relying on a subset of expert-level annotations. We demonstrate the effectiveness of our proposed model on both X-ray and lung CT datasets, indicating its ability to improve segmentation accuracy and outperform baseline methods in label correction.
Cardiac Adipose Tissue Segmentation via Image-Level Annotations
Jun 09, 2022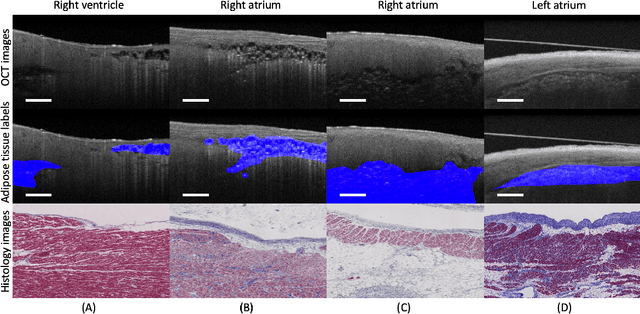
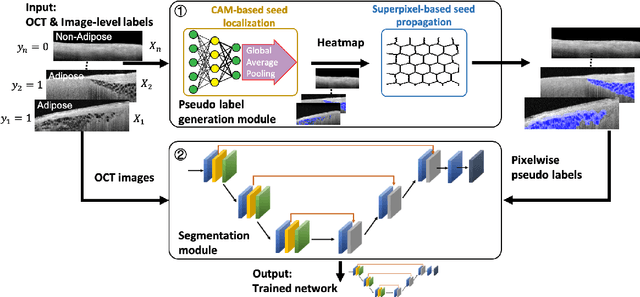

Automatically identifying the structural substrates underlying cardiac abnormalities can potentially provide real-time guidance for interventional procedures. With the knowledge of cardiac tissue substrates, the treatment of complex arrhythmias such as atrial fibrillation and ventricular tachycardia can be further optimized by detecting arrhythmia substrates to target for treatment (i.e., adipose) and identifying critical structures to avoid. Optical coherence tomography (OCT) is a real-time imaging modality that aids in addressing this need. Existing approaches for cardiac image analysis mainly rely on fully supervised learning techniques, which suffer from the drawback of workload on labor-intensive annotation process of pixel-wise labeling. To lessen the need for pixel-wise labeling, we develop a two-stage deep learning framework for cardiac adipose tissue segmentation using image-level annotations on OCT images of human cardiac substrates. In particular, we integrate class activation mapping with superpixel segmentation to solve the sparse tissue seed challenge raised in cardiac tissue segmentation. Our study bridges the gap between the demand on automatic tissue analysis and the lack of high-quality pixel-wise annotations. To the best of our knowledge, this is the first study that attempts to address cardiac tissue segmentation on OCT images via weakly supervised learning techniques. Within an in-vitro human cardiac OCT dataset, we demonstrate that our weakly supervised approach on image-level annotations achieves comparable performance as fully supervised methods trained on pixel-wise annotations.
Suggestive Annotation of Brain MR Images with Gradient-guided Sampling
Jun 02, 2022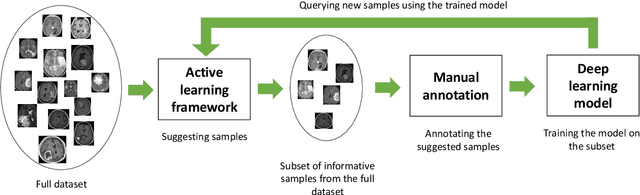
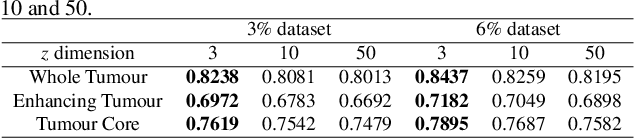
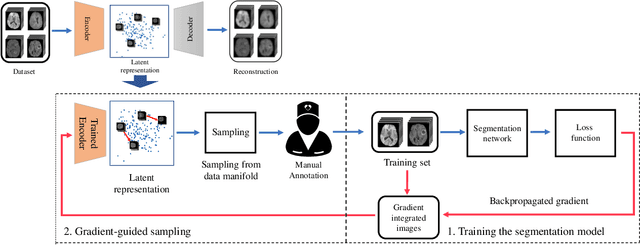

Machine learning has been widely adopted for medical image analysis in recent years given its promising performance in image segmentation and classification tasks. The success of machine learning, in particular supervised learning, depends on the availability of manually annotated datasets. For medical imaging applications, such annotated datasets are not easy to acquire, it takes a substantial amount of time and resource to curate an annotated medical image set. In this paper, we propose an efficient annotation framework for brain MR images that can suggest informative sample images for human experts to annotate. We evaluate the framework on two different brain image analysis tasks, namely brain tumour segmentation and whole brain segmentation. Experiments show that for brain tumour segmentation task on the BraTS 2019 dataset, training a segmentation model with only 7% suggestively annotated image samples can achieve a performance comparable to that of training on the full dataset. For whole brain segmentation on the MALC dataset, training with 42% suggestively annotated image samples can achieve a comparable performance to training on the full dataset. The proposed framework demonstrates a promising way to save manual annotation cost and improve data efficiency in medical imaging applications.