 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQU-BraTS: MICCAI BraTS 2020 Challenge on Quantifying Uncertainty in Brain Tumor Segmentation -- Analysis of Ranking Metrics and Benchmarking Results
Dec 19, 2021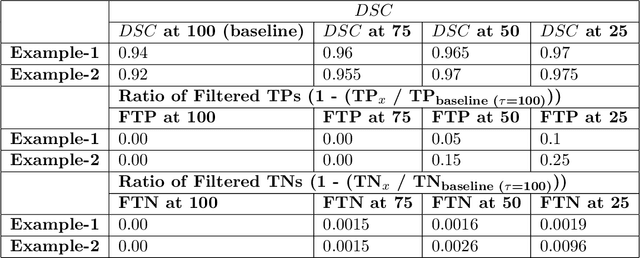
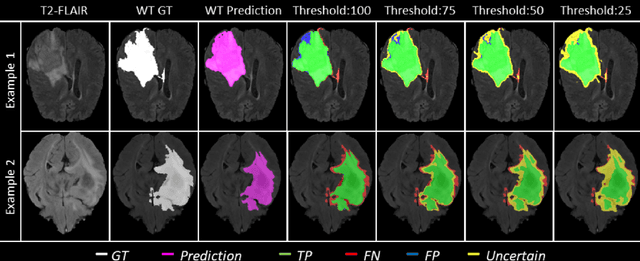
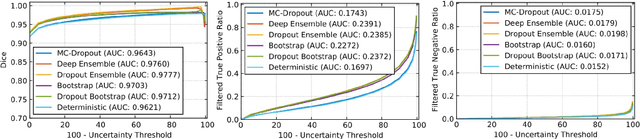
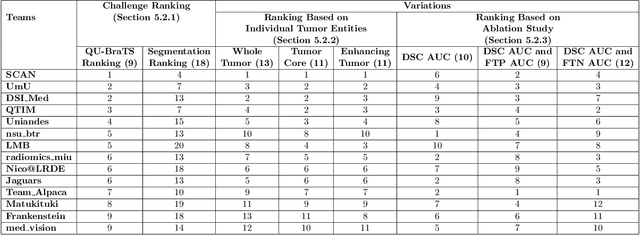
Deep learning (DL) models have provided the state-of-the-art performance in a wide variety of medical imaging benchmarking challenges, including the Brain Tumor Segmentation (BraTS) challenges. However, the task of focal pathology multi-compartment segmentation (e.g., tumor and lesion sub-regions) is particularly challenging, and potential errors hinder the translation of DL models into clinical workflows. Quantifying the reliability of DL model predictions in the form of uncertainties, could enable clinical review of the most uncertain regions, thereby building trust and paving the way towards clinical translation. Recently, a number of uncertainty estimation methods have been introduced for DL medical image segmentation tasks. Developing metrics to evaluate and compare the performance of uncertainty measures will assist the end-user in making more informed decisions. In this study, we explore and evaluate a metric developed during the BraTS 2019-2020 task on uncertainty quantification (QU-BraTS), and designed to assess and rank uncertainty estimates for brain tumor multi-compartment segmentation. This metric (1) rewards uncertainty estimates that produce high confidence in correct assertions, and those that assign low confidence levels at incorrect assertions, and (2) penalizes uncertainty measures that lead to a higher percentages of under-confident correct assertions. We further benchmark the segmentation uncertainties generated by 14 independent participating teams of QU-BraTS 2020, all of which also participated in the main BraTS segmentation task. Overall, our findings confirm the importance and complementary value that uncertainty estimates provide to segmentation algorithms, and hence highlight the need for uncertainty quantification in medical image analyses. Our evaluation code is made publicly available at https://github.com/RagMeh11/QU-BraTS.
Artificial Intelligence Governance and Ethics: Global Perspectives
Jun 28, 2019Artificial intelligence (AI) is a technology which is increasingly being utilised in society and the economy worldwide, and its implementation is planned to become more prevalent in coming years. AI is increasingly being embedded in our lives, supplementing our pervasive use of digital technologies. But this is being accompanied by disquiet over problematic and dangerous implementations of AI, or indeed, even AI itself deciding to do dangerous and problematic actions, especially in fields such as the military, medicine and criminal justice. These developments have led to concerns about whether and how AI systems adhere, and will adhere to ethical standards. These concerns have stimulated a global conversation on AI ethics, and have resulted in various actors from different countries and sectors issuing ethics and governance initiatives and guidelines for AI. Such developments form the basis for our research in this report, combining our international and interdisciplinary expertise to give an insight into what is happening in Australia, China, Europe, India and the US.