 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTiny Aya: Bridging Scale and Multilingual Depth
Mar 12, 2026Tiny Aya redefines what a small multilingual language model can achieve. Trained on 70 languages and refined through region-aware posttraining, it delivers state-of-the-art in translation quality, strong multilingual understanding, and high-quality target-language generation, all with just 3.35B parameters. The release includes a pretrained foundation model, a globally balanced instruction-tuned variant, and three region-specialized models targeting languages from Africa, South Asia, Europe, Asia-Pacific, and West Asia. This report details the training strategy, data composition, and comprehensive evaluation framework behind Tiny Aya, and presents an alternative scaling path for multilingual AI: one centered on efficiency, balanced performance across languages, and practical deployment.
Safe Domain Randomization via Uncertainty-Aware Out-of-Distribution Detection and Policy Adaptation
Jul 08, 2025



Deploying reinforcement learning (RL) policies in real-world involves significant challenges, including distribution shifts, safety concerns, and the impracticality of direct interactions during policy refinement. Existing methods, such as domain randomization (DR) and off-dynamics RL, enhance policy robustness by direct interaction with the target domain, an inherently unsafe practice. We propose Uncertainty-Aware RL (UARL), a novel framework that prioritizes safety during training by addressing Out-Of-Distribution (OOD) detection and policy adaptation without requiring direct interactions in target domain. UARL employs an ensemble of critics to quantify policy uncertainty and incorporates progressive environmental randomization to prepare the policy for diverse real-world conditions. By iteratively refining over high-uncertainty regions of the state space in simulated environments, UARL enhances robust generalization to the target domain without explicitly training on it. We evaluate UARL on MuJoCo benchmarks and a quadrupedal robot, demonstrating its effectiveness in reliable OOD detection, improved performance, and enhanced sample efficiency compared to baselines.
On the Societal Impact of Open Foundation Models
Feb 27, 2024

Foundation models are powerful technologies: how they are released publicly directly shapes their societal impact. In this position paper, we focus on open foundation models, defined here as those with broadly available model weights (e.g. Llama 2, Stable Diffusion XL). We identify five distinctive properties (e.g. greater customizability, poor monitoring) of open foundation models that lead to both their benefits and risks. Open foundation models present significant benefits, with some caveats, that span innovation, competition, the distribution of decision-making power, and transparency. To understand their risks of misuse, we design a risk assessment framework for analyzing their marginal risk. Across several misuse vectors (e.g. cyberattacks, bioweapons), we find that current research is insufficient to effectively characterize the marginal risk of open foundation models relative to pre-existing technologies. The framework helps explain why the marginal risk is low in some cases, clarifies disagreements about misuse risks by revealing that past work has focused on different subsets of the framework with different assumptions, and articulates a way forward for more constructive debate. Overall, our work helps support a more grounded assessment of the societal impact of open foundation models by outlining what research is needed to empirically validate their theoretical benefits and risks.
The Curious Case of Absolute Position Embeddings
Oct 23, 2022



Transformer language models encode the notion of word order using positional information. Most commonly, this positional information is represented by absolute position embeddings (APEs), that are learned from the pretraining data. However, in natural language, it is not absolute position that matters, but relative position, and the extent to which APEs can capture this type of information has not been investigated. In this work, we observe that models trained with APE over-rely on positional information to the point that they break-down when subjected to sentences with shifted position information. Specifically, when models are subjected to sentences starting from a non-zero position (excluding the effect of priming), they exhibit noticeably degraded performance on zero to full-shot tasks, across a range of model families and model sizes. Our findings raise questions about the efficacy of APEs to model the relativity of position information, and invite further introspection on the sentence and word order processing strategies employed by these models.
Questions Are All You Need to Train a Dense Passage Retriever
Jun 21, 2022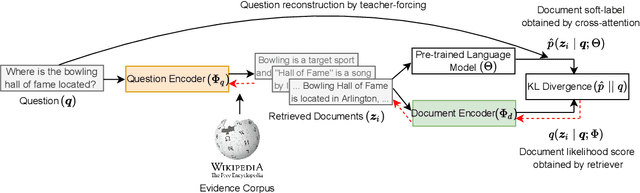
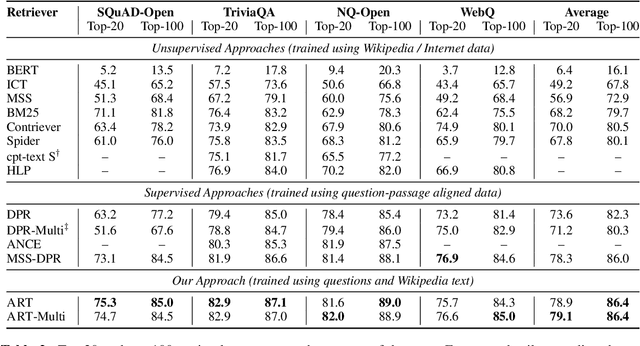
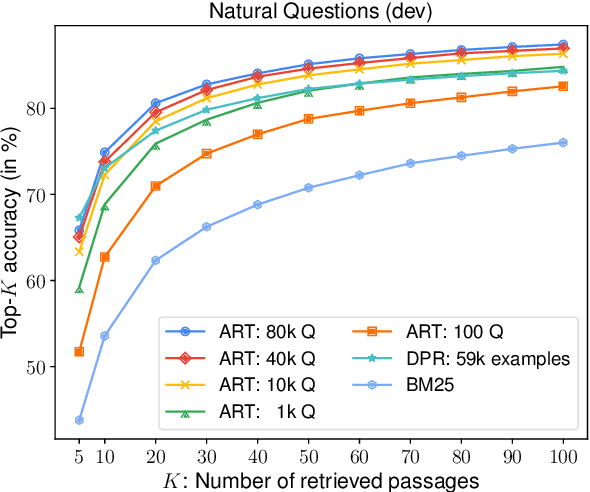
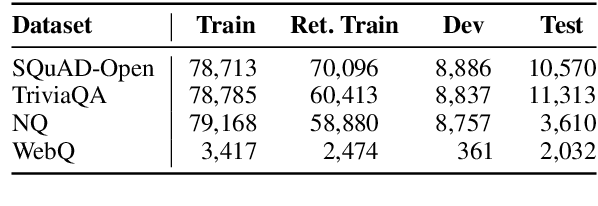
We introduce ART, a new corpus-level autoencoding approach for training dense retrieval models that does not require any labeled training data. Dense retrieval is a central challenge for open-domain tasks, such as Open QA, where state-of-the-art methods typically require large supervised datasets with custom hard-negative mining and denoising of positive examples. ART, in contrast, only requires access to unpaired inputs and outputs (e.g. questions and potential answer documents). It uses a new document-retrieval autoencoding scheme, where (1) an input question is used to retrieve a set of evidence documents, and (2) the documents are then used to compute the probability of reconstructing the original question. Training for retrieval based on question reconstruction enables effective unsupervised learning of both document and question encoders, which can be later incorporated into complete Open QA systems without any further finetuning. Extensive experiments demonstrate that ART obtains state-of-the-art results on multiple QA retrieval benchmarks with only generic initialization from a pre-trained language model, removing the need for labeled data and task-specific losses.
Improving Passage Retrieval with Zero-Shot Question Generation
Apr 15, 2022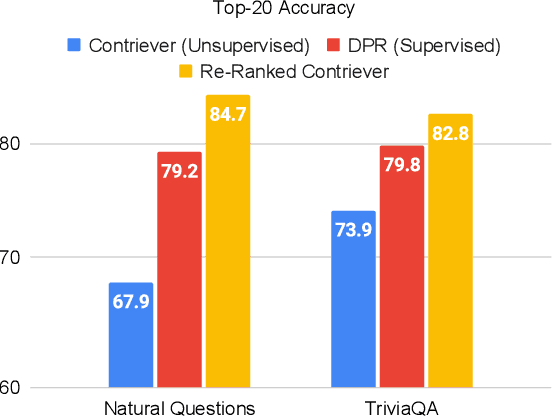
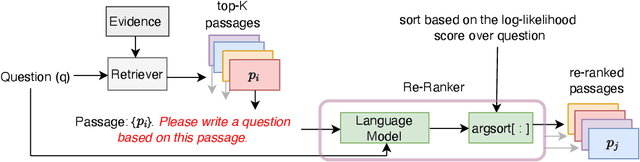
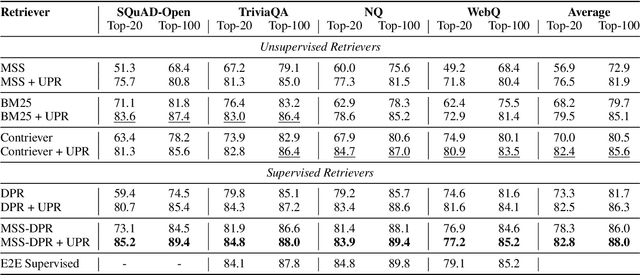
We propose a simple and effective re-ranking method for improving passage retrieval in open question answering. The re-ranker re-scores retrieved passages with a zero-shot question generation model, which uses a pre-trained language model to compute the probability of the input question conditioned on a retrieved passage. This approach can be applied on top of any retrieval method (e.g. neural or keyword-based), does not require any domain- or task-specific training (and therefore is expected to generalize better to data distribution shifts), and provides rich cross-attention between query and passage (i.e. it must explain every token in the question). When evaluated on a number of open-domain retrieval datasets, our re-ranker improves strong unsupervised retrieval models by 6%-18% absolute and strong supervised models by up to 12% in terms of top-20 passage retrieval accuracy. We also obtain new state-of-the-art results on full open-domain question answering by simply adding the new re-ranker to existing models with no further changes.
New Insights on Reducing Abrupt Representation Change in Online Continual Learning
Mar 08, 2022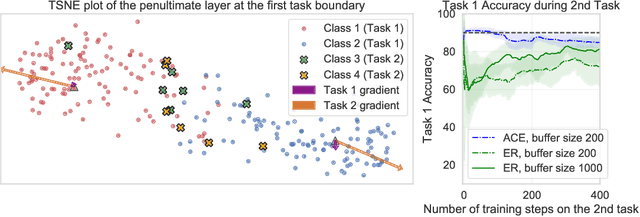
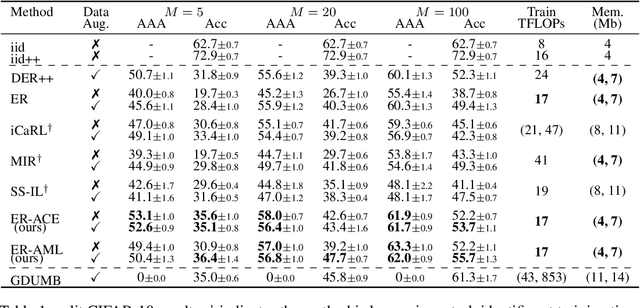
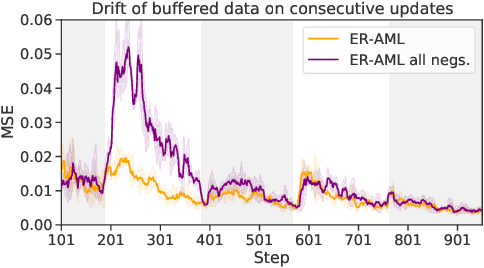
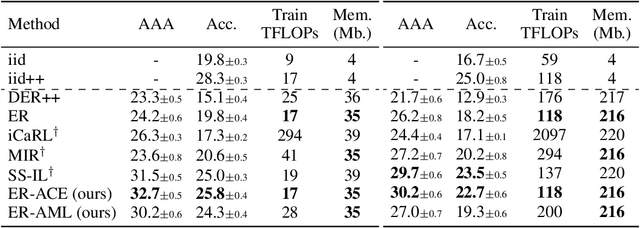
In the online continual learning paradigm, agents must learn from a changing distribution while respecting memory and compute constraints. Experience Replay (ER), where a small subset of past data is stored and replayed alongside new data, has emerged as a simple and effective learning strategy. In this work, we focus on the change in representations of observed data that arises when previously unobserved classes appear in the incoming data stream, and new classes must be distinguished from previous ones. We shed new light on this question by showing that applying ER causes the newly added classes' representations to overlap significantly with the previous classes, leading to highly disruptive parameter updates. Based on this empirical analysis, we propose a new method which mitigates this issue by shielding the learned representations from drastic adaptation to accommodate new classes. We show that using an asymmetric update rule pushes new classes to adapt to the older ones (rather than the reverse), which is more effective especially at task boundaries, where much of the forgetting typically occurs. Empirical results show significant gains over strong baselines on standard continual learning benchmarks
Robust Policy Learning over Multiple Uncertainty Sets
Mar 04, 2022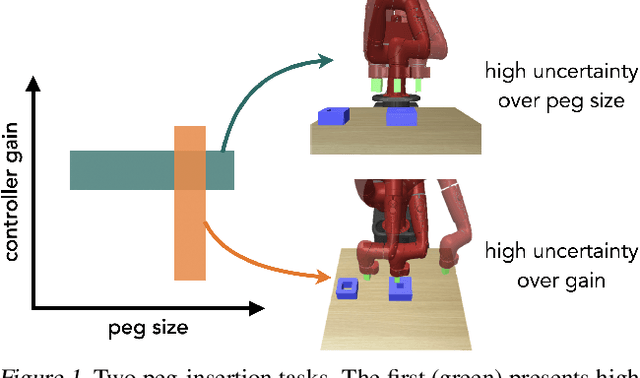
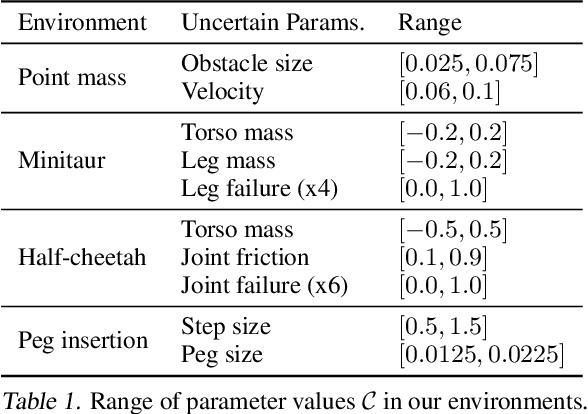
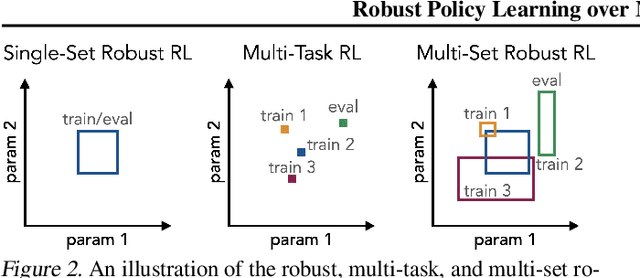

Reinforcement learning (RL) agents need to be robust to variations in safety-critical environments. While system identification methods provide a way to infer the variation from online experience, they can fail in settings where fast identification is not possible. Another dominant approach is robust RL which produces a policy that can handle worst-case scenarios, but these methods are generally designed to achieve robustness to a single uncertainty set that must be specified at train time. Towards a more general solution, we formulate the multi-set robustness problem to learn a policy robust to different perturbation sets. We then design an algorithm that enjoys the benefits of both system identification and robust RL: it reduces uncertainty where possible given a few interactions, but can still act robustly with respect to the remaining uncertainty. On a diverse set of control tasks, our approach demonstrates improved worst-case performance on new environments compared to prior methods based on system identification and on robust RL alone.
Estimating causal effects with optimization-based methods: A review and empirical comparison
Feb 28, 2022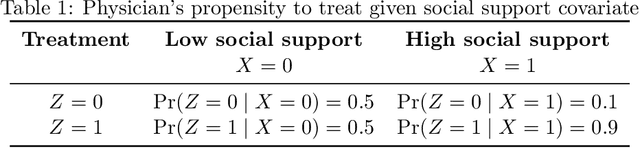
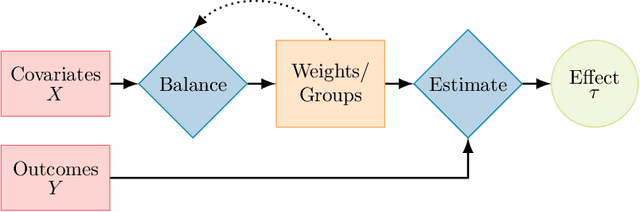
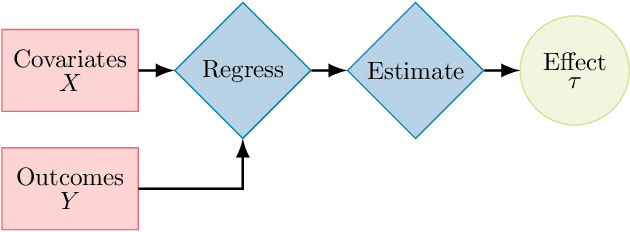
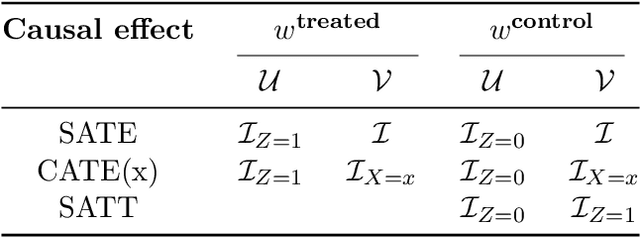
In the absence of randomized controlled and natural experiments, it is necessary to balance the distributions of (observable) covariates of the treated and control groups in order to obtain an unbiased estimate of a causal effect of interest; otherwise, a different effect size may be estimated, and incorrect recommendations may be given. To achieve this balance, there exist a wide variety of methods. In particular, several methods based on optimization models have been recently proposed in the causal inference literature. While these optimization-based methods empirically showed an improvement over a limited number of other causal inference methods in their relative ability to balance the distributions of covariates and to estimate causal effects, they have not been thoroughly compared to each other and to other noteworthy causal inference methods. In addition, we believe that there exist several unaddressed opportunities that operational researchers could contribute with their advanced knowledge of optimization, for the benefits of the applied researchers that use causal inference tools. In this review paper, we present an overview of the causal inference literature and describe in more detail the optimization-based causal inference methods, provide a comparative analysis of the prevailing optimization-based methods, and discuss opportunities for new methods.
* In Press, Corrected Proof
Efficient Continual Learning Ensembles in Neural Network Subspaces
Feb 20, 2022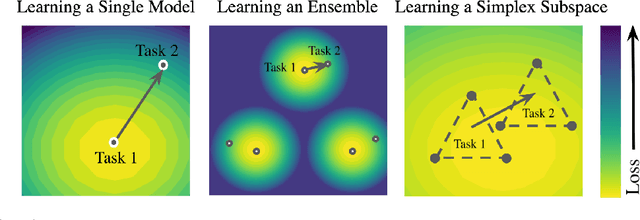
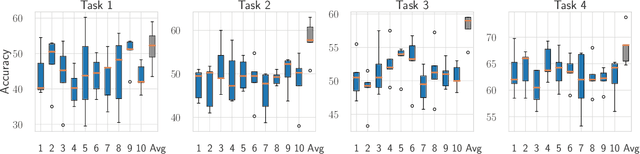

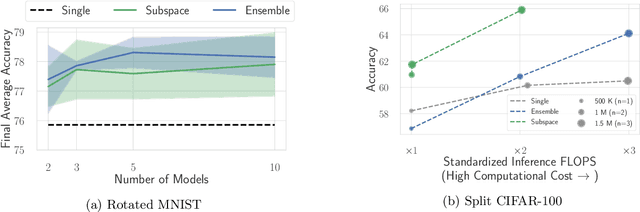
A growing body of research in continual learning focuses on the catastrophic forgetting problem. While many attempts have been made to alleviate this problem, the majority of the methods assume a single model in the continual learning setup. In this work, we question this assumption and show that employing ensemble models can be a simple yet effective method to improve continual performance. However, the training and inference cost of ensembles can increase linearly with the number of models. Motivated by this limitation, we leverage the recent advances in the deep learning optimization literature, such as mode connectivity and neural network subspaces, to derive a new method that is both computationally advantageous and can outperform the state-of-the-art continual learning algorithms.