 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQU-BraTS: MICCAI BraTS 2020 Challenge on Quantifying Uncertainty in Brain Tumor Segmentation -- Analysis of Ranking Metrics and Benchmarking Results
Dec 19, 2021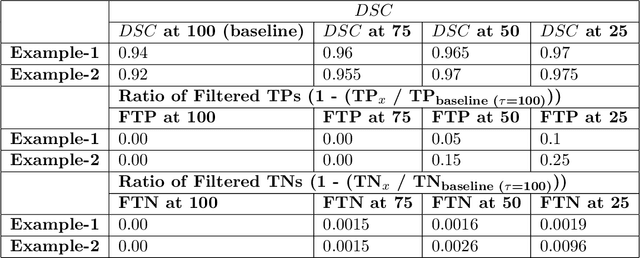
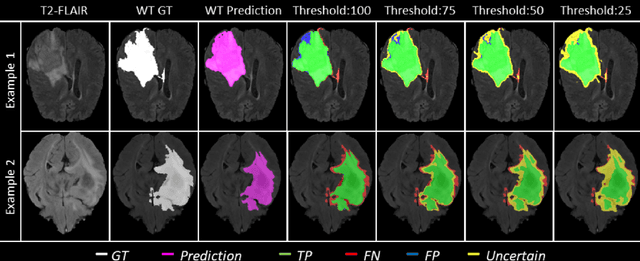
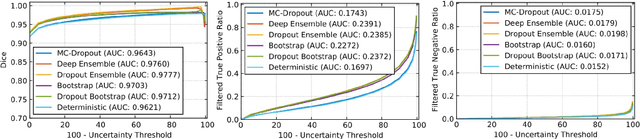
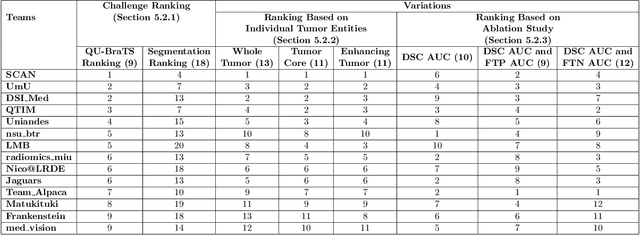
Deep learning (DL) models have provided the state-of-the-art performance in a wide variety of medical imaging benchmarking challenges, including the Brain Tumor Segmentation (BraTS) challenges. However, the task of focal pathology multi-compartment segmentation (e.g., tumor and lesion sub-regions) is particularly challenging, and potential errors hinder the translation of DL models into clinical workflows. Quantifying the reliability of DL model predictions in the form of uncertainties, could enable clinical review of the most uncertain regions, thereby building trust and paving the way towards clinical translation. Recently, a number of uncertainty estimation methods have been introduced for DL medical image segmentation tasks. Developing metrics to evaluate and compare the performance of uncertainty measures will assist the end-user in making more informed decisions. In this study, we explore and evaluate a metric developed during the BraTS 2019-2020 task on uncertainty quantification (QU-BraTS), and designed to assess and rank uncertainty estimates for brain tumor multi-compartment segmentation. This metric (1) rewards uncertainty estimates that produce high confidence in correct assertions, and those that assign low confidence levels at incorrect assertions, and (2) penalizes uncertainty measures that lead to a higher percentages of under-confident correct assertions. We further benchmark the segmentation uncertainties generated by 14 independent participating teams of QU-BraTS 2020, all of which also participated in the main BraTS segmentation task. Overall, our findings confirm the importance and complementary value that uncertainty estimates provide to segmentation algorithms, and hence highlight the need for uncertainty quantification in medical image analyses. Our evaluation code is made publicly available at https://github.com/RagMeh11/QU-BraTS.
MANTRA: A Machine Learning reference lightcurve dataset for astronomical transient event recognition
Jun 30, 2020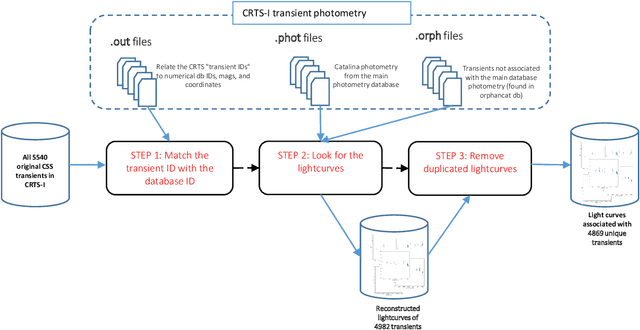
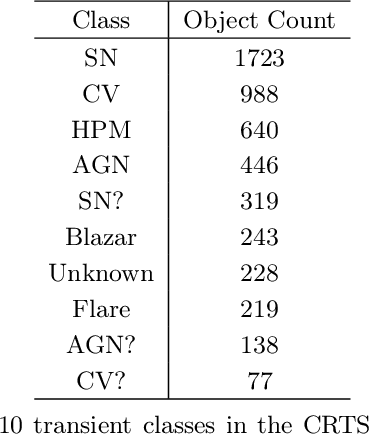
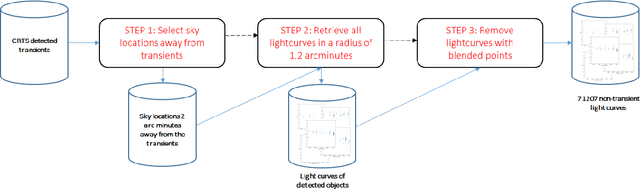
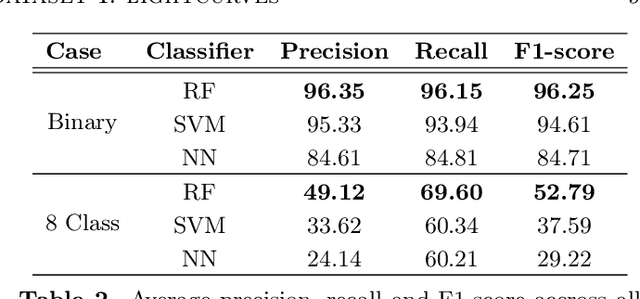
We introduce MANTRA, an annotated dataset of 4869 transient and 71207 non-transient object lightcurves built from the Catalina Real Time Transient Survey. We provide public access to this dataset as a plain text file to facilitate standardized quantitative comparison of astronomical transient event recognition algorithms. Some of the classes included in the dataset are: supernovae, cataclysmic variables, active galactic nuclei, high proper motion stars, blazars and flares. As an example of the tasks that can be performed on the dataset we experiment with multiple data pre-processing methods, feature selection techniques and popular machine learning algorithms (Support Vector Machines, Random Forests and Neural Networks). We assess quantitative performance in two classification tasks: binary (transient/non-transient) and eight-class classification. The best performing algorithm in both tasks is the Random Forest Classifier. It achieves an F1-score of 96.25% in the binary classification and 52.79% in the eight-class classification. For the eight-class classification, non-transients ( 96.83% ) is the class with the highest F1-score, while the lowest corresponds to high-proper-motion stars ( 16.79% ); for supernovae it achieves a value of 54.57% , close to the average across classes. The next release of MANTRA includes images and benchmarks with deep learning models.
Classifying Image Sequences of Astronomical Transients with Deep Neural Networks
Apr 28, 2020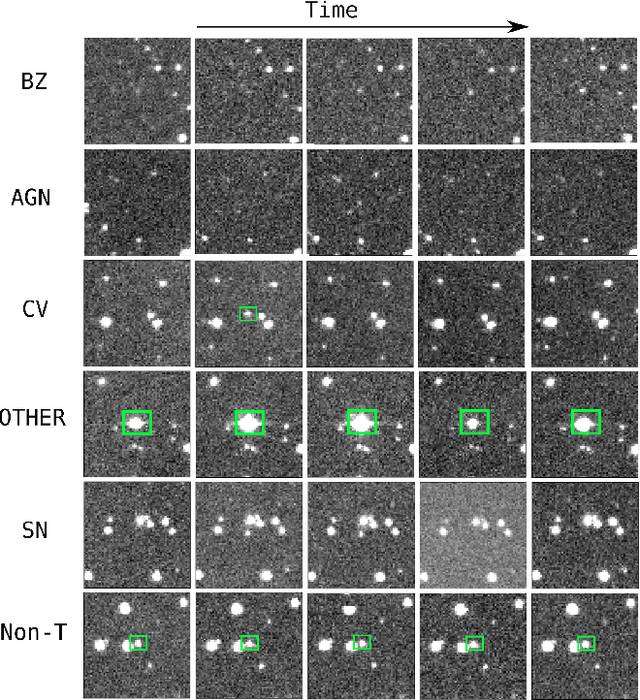


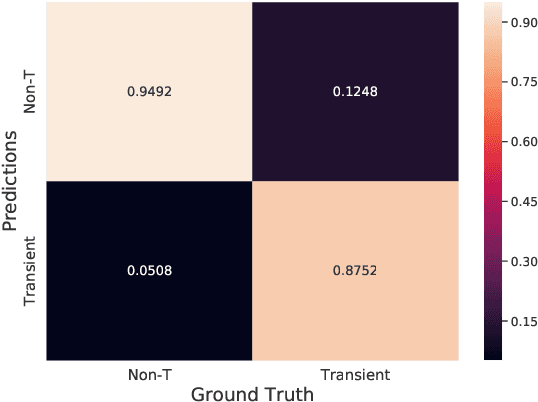
Supervised classification of temporal sequences of astronomical images into meaningful transient astrophysical phenomena has been considered a hard problem because it requires the intervention of human experts. The classifier uses the expert's knowledge to find heuristic features to process the images, for instance, by performing image subtraction or by extracting sparse information such as flux time series in the form of light curves. We present a successful deep learning approach that learns directly from imaging data. Our method models explicitly the spatio-temporal patterns with Deep Convolutional Neural Networks and Gated Recurrent Units. We train these deep neural networks using 1.3 million real astronomical images from the Catalina Real-Time Transient Survey to classify the sequences into five different types of astronomical transient classes. The TAO-Net (for Transient Astronomical Objects Network) architecture achieves on the five-type classification task an average F1-score of 54.58$\pm$13.32, almost nine points higher than the F1-score of 45.49 $\pm$ 13.75 from the random forest classification on light curves. The achievement TAO-Net opens the possibility to develop new deep-learning architectures for early transient detection. We make available the training dataset and trained models of TAO-Net to allow for future extensions of this work.