 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Brain MRI Foundation Models for the Clinic: Findings from the FOMO25 Challenge
Apr 13, 2026Clinical deployment of automated brain MRI analysis faces a fundamental challenge: clinical data is heterogeneous and noisy, and high-quality labels are prohibitively costly to obtain. Self-supervised learning (SSL) can address this by leveraging the vast amounts of unlabeled data produced in clinical workflows to train robust \textit{foundation models} that adapt out-of-domain with minimal supervision. However, the development of foundation models for brain MRI has been limited by small pretraining datasets and in-domain benchmarking focused on high-quality, research-grade data. To address this gap, we organized the FOMO25 challenge as a satellite event at MICCAI 2025. FOMO25 provided participants with a large pretraining dataset, FOMO60K, and evaluated models on data sourced directly from clinical workflows in few-shot and out-of-domain settings. Tasks covered infarct classification, meningioma segmentation, and brain age regression, and considered both models trained on FOMO60K (method track) and any data (open track). Nineteen foundation models from sixteen teams were evaluated using a standardized containerized pipeline. Results show that (a) self-supervised pretraining improves generalization on clinical data under domain shift, with the strongest models trained \textit{out-of-domain} surpassing supervised baselines trained \textit{in-domain}. (b) No single pretraining objective benefits all tasks: MAE favors segmentation, hybrid reconstruction-contrastive objectives favor classification, and (c) strong performance was achieved by small pretrained models, and improvements from scaling model size and training duration did not yield reliable benefits.
Pixels Under Pressure: Exploring Fine-Tuning Paradigms for Foundation Models in High-Resolution Medical Imaging
Aug 19, 2025



Advancements in diffusion-based foundation models have improved text-to-image generation, yet most efforts have been limited to low-resolution settings. As high-resolution image synthesis becomes increasingly essential for various applications, particularly in medical imaging domains, fine-tuning emerges as a crucial mechanism for adapting these powerful pre-trained models to task-specific requirements and data distributions. In this work, we present a systematic study, examining the impact of various fine-tuning techniques on image generation quality when scaling to high resolution 512x512 pixels. We benchmark a diverse set of fine-tuning methods, including full fine-tuning strategies and parameter-efficient fine-tuning (PEFT). We dissect how different fine-tuning methods influence key quality metrics, including Fr\'echet Inception Distance (FID), Vendi score, and prompt-image alignment. We also evaluate the utility of generated images in a downstream classification task under data-scarce conditions, demonstrating that specific fine-tuning strategies improve both generation fidelity and downstream performance when synthetic images are used for classifier training and evaluation on real images. Our code is accessible through the project website - https://tehraninasab.github.io/PixelUPressure/.
Spatio-Temporal Conditional Diffusion Models for Forecasting Future Multiple Sclerosis Lesion Masks Conditioned on Treatments
Aug 09, 2025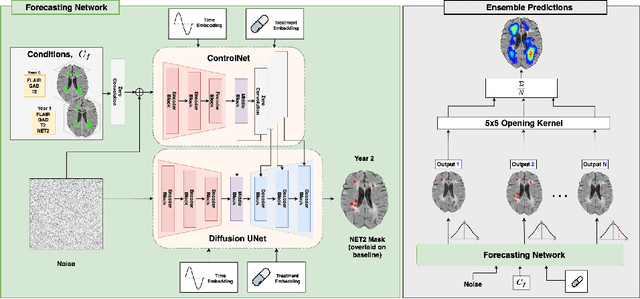



Image-based personalized medicine has the potential to transform healthcare, particularly for diseases that exhibit heterogeneous progression such as Multiple Sclerosis (MS). In this work, we introduce the first treatment-aware spatio-temporal diffusion model that is able to generate future masks demonstrating lesion evolution in MS. Our voxel-space approach incorporates multi-modal patient data, including MRI and treatment information, to forecast new and enlarging T2 (NET2) lesion masks at a future time point. Extensive experiments on a multi-centre dataset of 2131 patient 3D MRIs from randomized clinical trials for relapsing-remitting MS demonstrate that our generative model is able to accurately predict NET2 lesion masks for patients across six different treatments. Moreover, we demonstrate our model has the potential for real-world clinical applications through downstream tasks such as future lesion count and location estimation, binary lesion activity classification, and generating counterfactual future NET2 masks for several treatments with different efficacies. This work highlights the potential of causal, image-based generative models as powerful tools for advancing data-driven prognostics in MS.
AURA: A Multi-Modal Medical Agent for Understanding, Reasoning & Annotation
Jul 22, 2025



Recent advancements in Large Language Models (LLMs) have catalyzed a paradigm shift from static prediction systems to agentic AI agents capable of reasoning, interacting with tools, and adapting to complex tasks. While LLM-based agentic systems have shown promise across many domains, their application to medical imaging remains in its infancy. In this work, we introduce AURA, the first visual linguistic explainability agent designed specifically for comprehensive analysis, explanation, and evaluation of medical images. By enabling dynamic interactions, contextual explanations, and hypothesis testing, AURA represents a significant advancement toward more transparent, adaptable, and clinically aligned AI systems. We highlight the promise of agentic AI in transforming medical image analysis from static predictions to interactive decision support. Leveraging Qwen-32B, an LLM-based architecture, AURA integrates a modular toolbox comprising: (i) a segmentation suite with phase grounding, pathology segmentation, and anatomy segmentation to localize clinically meaningful regions; (ii) a counterfactual image-generation module that supports reasoning through image-level explanations; and (iii) a set of evaluation tools including pixel-wise difference-map analysis, classification, and advanced state-of-the-art components to assess diagnostic relevance and visual interpretability.
Language-Guided Trajectory Traversal in Disentangled Stable Diffusion Latent Space for Factorized Medical Image Generation
Mar 30, 2025



Text-to-image diffusion models have demonstrated a remarkable ability to generate photorealistic images from natural language prompts. These high-resolution, language-guided synthesized images are essential for the explainability of disease or exploring causal relationships. However, their potential for disentangling and controlling latent factors of variation in specialized domains like medical imaging remains under-explored. In this work, we present the first investigation of the power of pre-trained vision-language foundation models, once fine-tuned on medical image datasets, to perform latent disentanglement for factorized medical image generation and interpolation. Through extensive experiments on chest X-ray and skin datasets, we illustrate that fine-tuned, language-guided Stable Diffusion inherently learns to factorize key attributes for image generation, such as the patient's anatomical structures or disease diagnostic features. We devise a framework to identify, isolate, and manipulate key attributes through latent space trajectory traversal of generative models, facilitating precise control over medical image synthesis.
RL4Med-DDPO: Reinforcement Learning for Controlled Guidance Towards Diverse Medical Image Generation using Vision-Language Foundation Models
Mar 20, 2025



Vision-Language Foundation Models (VLFM) have shown a tremendous increase in performance in terms of generating high-resolution, photorealistic natural images. While VLFMs show a rich understanding of semantic content across modalities, they often struggle with fine-grained alignment tasks that require precise correspondence between image regions and textual descriptions a limitation in medical imaging, where accurate localization and detection of clinical features are essential for diagnosis and analysis. To address this issue, we propose a multi-stage architecture where a pre-trained VLFM provides a cursory semantic understanding, while a reinforcement learning (RL) algorithm refines the alignment through an iterative process that optimizes for understanding semantic context. The reward signal is designed to align the semantic information of the text with synthesized images. We demonstrate the effectiveness of our method on a medical imaging skin dataset where the generated images exhibit improved generation quality and alignment with prompt over the fine-tuned Stable Diffusion. We also show that the synthesized samples could be used to improve disease classifier performance for underrepresented subgroups through augmentation.
Conditional Diffusion Models are Medical Image Classifiers that Provide Explainability and Uncertainty for Free
Feb 06, 2025



Discriminative classifiers have become a foundational tool in deep learning for medical imaging, excelling at learning separable features of complex data distributions. However, these models often need careful design, augmentation, and training techniques to ensure safe and reliable deployment. Recently, diffusion models have become synonymous with generative modeling in 2D. These models showcase robustness across a range of tasks including natural image classification, where classification is performed by comparing reconstruction errors across images generated for each possible conditioning input. This work presents the first exploration of the potential of class conditional diffusion models for 2D medical image classification. First, we develop a novel majority voting scheme shown to improve the performance of medical diffusion classifiers. Next, extensive experiments on the CheXpert and ISIC Melanoma skin cancer datasets demonstrate that foundation and trained-from-scratch diffusion models achieve competitive performance against SOTA discriminative classifiers without the need for explicit supervision. In addition, we show that diffusion classifiers are intrinsically explainable, and can be used to quantify the uncertainty of their predictions, increasing their trustworthiness and reliability in safety-critical, clinical contexts. Further information is available on our project page: https://faverogian.github.io/med-diffusion-classifier.github.io/
Probabilistic Temporal Prediction of Continuous Disease Trajectories and Treatment Effects Using Neural SDEs
Jun 18, 2024



Personalized medicine based on medical images, including predicting future individualized clinical disease progression and treatment response, would have an enormous impact on healthcare and drug development, particularly for diseases (e.g. multiple sclerosis (MS)) with long term, complex, heterogeneous evolutions and no cure. In this work, we present the first stochastic causal temporal framework to model the continuous temporal evolution of disease progression via Neural Stochastic Differential Equations (NSDE). The proposed causal inference model takes as input the patient's high dimensional images (MRI) and tabular data, and predicts both factual and counterfactual progression trajectories on different treatments in latent space. The NSDE permits the estimation of high-confidence personalized trajectories and treatment effects. Extensive experiments were performed on a large, multi-centre, proprietary dataset of patient 3D MRI and clinical data acquired during several randomized clinical trials for MS treatments. Our results present the first successful uncertainty-based causal Deep Learning (DL) model to: (a) accurately predict future patient MS disability evolution (e.g. EDSS) and treatment effects leveraging baseline MRI, and (b) permit the discovery of subgroups of patients for which the model has high confidence in their response to treatment even in clinical trials which did not reach their clinical endpoints.
DeCoDEx: Confounder Detector Guidance for Improved Diffusion-based Counterfactual Explanations
May 15, 2024



Deep learning classifiers are prone to latching onto dominant confounders present in a dataset rather than on the causal markers associated with the target class, leading to poor generalization and biased predictions. Although explainability via counterfactual image generation has been successful at exposing the problem, bias mitigation strategies that permit accurate explainability in the presence of dominant and diverse artifacts remain unsolved. In this work, we propose the DeCoDEx framework and show how an external, pre-trained binary artifact detector can be leveraged during inference to guide a diffusion-based counterfactual image generator towards accurate explainability. Experiments on the CheXpert dataset, using both synthetic artifacts and real visual artifacts (support devices), show that the proposed method successfully synthesizes the counterfactual images that change the causal pathology markers associated with Pleural Effusion while preserving or ignoring the visual artifacts. Augmentation of ERM and Group-DRO classifiers with the DeCoDEx generated images substantially improves the results across underrepresented groups that are out of distribution for each class. The code is made publicly available at https://github.com/NimaFathi/DeCoDEx.
HyperFusion: A Hypernetwork Approach to Multimodal Integration of Tabular and Medical Imaging Data for Predictive Modeling
Mar 20, 2024



The integration of diverse clinical modalities such as medical imaging and the tabular data obtained by the patients' Electronic Health Records (EHRs) is a crucial aspect of modern healthcare. The integrative analysis of multiple sources can provide a comprehensive understanding of a patient's condition and can enhance diagnoses and treatment decisions. Deep Neural Networks (DNNs) consistently showcase outstanding performance in a wide range of multimodal tasks in the medical domain. However, the complex endeavor of effectively merging medical imaging with clinical, demographic and genetic information represented as numerical tabular data remains a highly active and ongoing research pursuit. We present a novel framework based on hypernetworks to fuse clinical imaging and tabular data by conditioning the image processing on the EHR's values and measurements. This approach aims to leverage the complementary information present in these modalities to enhance the accuracy of various medical applications. We demonstrate the strength and the generality of our method on two different brain Magnetic Resonance Imaging (MRI) analysis tasks, namely, brain age prediction conditioned by subject's sex, and multiclass Alzheimer's Disease (AD) classification conditioned by tabular data. We show that our framework outperforms both single-modality models and state-of-the-art MRI-tabular data fusion methods. The code, enclosed to this manuscript will be made publicly available.