 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoint Cloud Registration for Fusion between SPECT MPI and CTA Images
Apr 27, 2026Clinical fusion of Single Photon Emission Computed Tomography Myocardial Perfusion Imaging (SPECT MPI) and Computed Tomography Angiography (CTA) remains limited by cross-modality misregistration and reliance on manual landmarks, which can hinder accurate ischemia localization and lesion-level functional assessment. To address this issue, we propose a registration and fusion framework for SPECT MPI and CTA that integrates functional and structural information for comprehensive cardiac evaluation. The proposed pipeline performs U-Net-based segmentation on both modalities. On SPECT MPI, only the left ventricle (LV) is extracted, and anatomical landmarks are automatically derived from characteristic LV structures. On CTA, both ventricles are segmented, and their spatial relationship is used to automatically define landmarks at the interventricular septal junction. Scale-space consistency preprocessing and landmark-driven coarse registration are applied to mitigate initial misalignment. Based on this initialization, multiple fine registration methods are evaluated on LV epicardial surface point clouds, including ICP, SICP, CPD, CluReg, FFD, and BCPD-plus-plus. The resulting transformations are then propagated to voxel-level resampling for high-precision SPECT-CTA fusion. In a retrospective cohort of 60 patients, the proposed framework preserved sub-millimeter coronary detail from CTA while accurately overlaying quantitative SPECT perfusion. Among the evaluated methods, BCPD-plus-plus achieved the highest accuracy with a mean point cloud distance of 1.7 mm. By combining robust initialization, comparative fine registration, and voxel-level fusion, the proposed approach provides a practical solution for myocardial ischemia localization and functional evaluation of coronary lesions, while remaining independent of any specific fine registration algorithm.
Vehicle-as-Prompt: A Unified Deep Reinforcement Learning Framework for Heterogeneous Fleet Vehicle Routing Problem
Apr 06, 2026Unlike traditional homogeneous routing problems, the Heterogeneous Fleet Vehicle Routing Problem (HFVRP) involves heterogeneous fixed costs, variable travel costs, and capacity constraints, rendering solution quality highly sensitive to vehicle selection. Furthermore, real-world logistics applications often impose additional complex constraints, markedly increasing computational complexity. However, most existing Deep Reinforcement Learning (DRL)-based methods are restricted to homogeneous scenarios, leading to suboptimal performance when applied to HFVRP and its complex variants. To bridge this gap, we investigate HFVRP under complex constraints and develop a unified DRL framework capable of solving the problem across various variant settings. We introduce the Vehicle-as-Prompt (VaP) mechanism, which formulates the problem as a single-stage autoregressive decision process. Building on this, we propose VaP-CSMV, a framework featuring a cross-semantic encoder and a multi-view decoder that effectively addresses various problem variants and captures the complex mapping relationships between vehicle heterogeneity and customer node attributes. Extensive experimental results demonstrate that VaP-CSMV significantly outperforms existing state-of-the-art DRL-based neural solvers and achieves competitive solution quality compared to traditional heuristic solvers, while reducing inference time to mere seconds. Furthermore, the framework exhibits strong zero-shot generalization capabilities on large-scale and previously unseen problem variants, while ablation studies validate the vital contribution of each component.
Accurate and Efficient Multi-Channel Time Series Forecasting via Sparse Attention Mechanism
Mar 19, 2026The task of multi-channel time series forecasting is ubiquitous in numerous fields such as finance, supply chain management, and energy planning. It is critical to effectively capture complex dynamic dependencies within and between channels for accurate predictions. However, traditional method paid few attentions on learning the interaction among channels. This paper proposes Linear-Network (Li-Net), a novel architecture designed for multi-channel time series forecasting that captures the linear and non-linear dependencies among channels. Li-Net dynamically compresses representations across sequence and channel dimensions, processes the information through a configurable non-linear module and subsequently reconstructs the forecasts. Moreover, Li-Net integrates a sparse Top-K Softmax attention mechanism within a multi-scale projection framework to address these challenges. A core innovation is its ability to seamlessly incorporate and fuse multi-modal embeddings, guiding the sparse attention process to focus on the most informative time steps and feature channels. Through the experiment results on multiple real-world benchmark datasets demonstrate that Li-Net achieves competitive performance compared to state-of-the-art baseline methods. Furthermore, Li-Net provides a superior balance between prediction accuracy and computational burden, exhibiting significantly lower memory usage and faster inference times. Detailed ablation studies and parameter sensitivity analyses validate the effectiveness of each key component in our proposed architecture. Keywords: Multivariate Time Series Forecasting, Sparse Attention Mechanism, Multimodal Information Fusion, Non-linear relationship
Imaging-Derived Coronary Fractional Flow Reserve: Advances in Physics-Based, Machine-Learning, and Physics-Informed Methods
Feb 17, 2026Purpose of Review Imaging derived fractional flow reserve (FFR) is rapidly evolving beyond conventional computational fluid dynamics (CFD) based pipelines toward machine learning (ML), deep learning (DL), and physics informed approaches that enable fast, wire free, and scalable functional assessment of coronary stenosis. This review synthesizes recent advances in CT and angiography based FFR, with particular emphasis on emerging physics informed neural networks and neural operators (PINNs and PINOs) and key considerations for their clinical translation. Recent Findings ML/DL approaches have markedly improved automation and computational speed, enabling prediction of pressure and FFR from anatomical descriptors or angiographic contrast dynamics. However, their real-world performance and generalizability can remain variable and sensitive to domain shift, due to multi-center heterogeneity, interpretability challenges, and differences in acquisition protocols and image quality. Physics informed learning introduces conservation structure and boundary condition consistency into model training, improving generalizability and reducing dependence on dense supervision while maintaining rapid inference. Recent evaluation trends increasingly highlight deployment oriented metrics, including calibration, uncertainty quantification, and quality control gatekeeping, as essential for safe clinical use. Summary The field is converging toward imaging derived FFR methods that are faster, more automated, and more reliable. While ML/DL offers substantial efficiency gains, physics informed frameworks such as PINNs and PINOs may provide a more robust balance between speed and physical consistency. Prospective multi center validation and standardized evaluation will be critical to support broad and safe clinical adoption.
PF-DAformer: Proximal Femur Segmentation via Domain Adaptive Transformer for Dual-Center QCT
Oct 30, 2025Quantitative computed tomography (QCT) plays a crucial role in assessing bone strength and fracture risk by enabling volumetric analysis of bone density distribution in the proximal femur. However, deploying automated segmentation models in practice remains difficult because deep networks trained on one dataset often fail when applied to another. This failure stems from domain shift, where scanners, reconstruction settings, and patient demographics vary across institutions, leading to unstable predictions and unreliable quantitative metrics. Overcoming this barrier is essential for multi-center osteoporosis research and for ensuring that radiomics and structural finite element analysis results remain reproducible across sites. In this work, we developed a domain-adaptive transformer segmentation framework tailored for multi-institutional QCT. Our model is trained and validated on one of the largest hip fracture related research cohorts to date, comprising 1,024 QCT images scans from Tulane University and 384 scans from Rochester, Minnesota for proximal femur segmentation. To address domain shift, we integrate two complementary strategies within a 3D TransUNet backbone: adversarial alignment via Gradient Reversal Layer (GRL), which discourages the network from encoding site-specific cues, and statistical alignment via Maximum Mean Discrepancy (MMD), which explicitly reduces distributional mismatches between institutions. This dual mechanism balances invariance and fine-grained alignment, enabling scanner-agnostic feature learning while preserving anatomical detail.
UPMAD-Net: A Brain Tumor Segmentation Network with Uncertainty Guidance and Adaptive Multimodal Feature Fusion
May 06, 2025
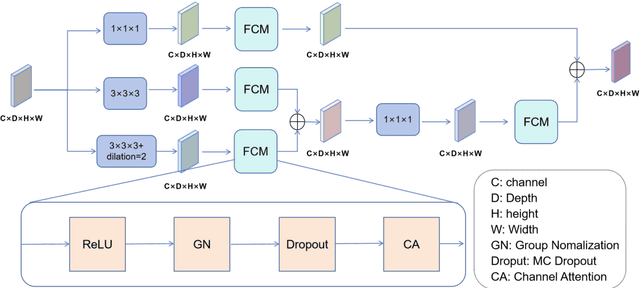


Background: Brain tumor segmentation has a significant impact on the diagnosis and treatment of brain tumors. Accurate brain tumor segmentation remains challenging due to their irregular shapes, vague boundaries, and high variability. Objective: We propose a brain tumor segmentation method that combines deep learning with prior knowledge derived from a region-growing algorithm. Methods: The proposed method utilizes a multi-scale feature fusion (MSFF) module and adaptive attention mechanisms (AAM) to extract multi-scale features and capture global contextual information. To enhance the model's robustness in low-confidence regions, the Monte Carlo Dropout (MC Dropout) strategy is employed for uncertainty estimation. Results: Extensive experiments demonstrate that the proposed method achieves superior performance on Brain Tumor Segmentation (BraTS) datasets, significantly outperforming various state-of-the-art methods. On the BraTS2021 dataset, the test Dice scores are 89.18% for Enhancing Tumor (ET) segmentation, 93.67% for Whole Tumor (WT) segmentation, and 91.23% for Tumor Core (TC) segmentation. On the BraTS2019 validation set, the validation Dice scores are 87.43%, 90.92%, and 90.40% for ET, WT, and TC segmentation, respectively. Ablation studies further confirmed the contribution of each module to segmentation accuracy, indicating that each component played a vital role in overall performance improvement. Conclusion: This study proposed a novel 3D brain tumor segmentation network based on the U-Net architecture. By incorporating the prior knowledge and employing the uncertainty estimation method, the robustness and performance were improved. The code for the proposed method is available at https://github.com/chenzhao2023/UPMAD_Net_BrainSeg.
Myocardial Region-guided Feature Aggregation Net for Automatic Coronary artery Segmentation and Stenosis Assessment using Coronary Computed Tomography Angiography
Apr 27, 2025



Coronary artery disease (CAD) remains a leading cause of mortality worldwide, requiring accurate segmentation and stenosis detection using Coronary Computed Tomography angiography (CCTA). Existing methods struggle with challenges such as low contrast, morphological variability and small vessel segmentation. To address these limitations, we propose the Myocardial Region-guided Feature Aggregation Net, a novel U-shaped dual-encoder architecture that integrates anatomical prior knowledge to enhance robustness in coronary artery segmentation. Our framework incorporates three key innovations: (1) a Myocardial Region-guided Module that directs attention to coronary regions via myocardial contour expansion and multi-scale feature fusion, (2) a Residual Feature Extraction Encoding Module that combines parallel spatial channel attention with residual blocks to enhance local-global feature discrimination, and (3) a Multi-scale Feature Fusion Module for adaptive aggregation of hierarchical vascular features. Additionally, Monte Carlo dropout f quantifies prediction uncertainty, supporting clinical interpretability. For stenosis detection, a morphology-based centerline extraction algorithm separates the vascular tree into anatomical branches, enabling cross-sectional area quantification and stenosis grading. The superiority of MGFA-Net was demonstrated by achieving an Dice score of 85.04%, an accuracy of 84.24%, an HD95 of 6.1294 mm, and an improvement of 5.46% in true positive rate for stenosis detection compared to3D U-Net. The integrated segmentation-to-stenosis pipeline provides automated, clinically interpretable CAD assessment, bridging deep learning with anatomical prior knowledge for precision medicine. Our code is publicly available at http://github.com/chenzhao2023/MGFA_CCTA
ICGM-FRAX: Iterative Cross Graph Matching for Hip Fracture Risk Assessment using Dual-energy X-ray Absorptiometry Images
Apr 21, 2025Hip fractures represent a major health concern, particularly among the elderly, often leading decreased mobility and increased mortality. Early and accurate detection of at risk individuals is crucial for effective intervention. In this study, we propose Iterative Cross Graph Matching for Hip Fracture Risk Assessment (ICGM-FRAX), a novel approach for predicting hip fractures using Dual-energy X-ray Absorptiometry (DXA) images. ICGM-FRAX involves iteratively comparing a test (subject) graph with multiple template graphs representing the characteristics of hip fracture subjects to assess the similarity and accurately to predict hip fracture risk. These graphs are obtained as follows. The DXA images are separated into multiple regions of interest (RoIs), such as the femoral head, shaft, and lesser trochanter. Radiomic features are then calculated for each RoI, with the central coordinates used as nodes in a graph. The connectivity between nodes is established according to the Euclidean distance between these coordinates. This process transforms each DXA image into a graph, where each node represents a RoI, and edges derived by the centroids of RoIs capture the spatial relationships between them. If the test graph closely matches a set of template graphs representing subjects with incident hip fractures, it is classified as indicating high hip fracture risk. We evaluated our method using 547 subjects from the UK Biobank dataset, and experimental results show that ICGM-FRAX achieved a sensitivity of 0.9869, demonstrating high accuracy in predicting hip fractures.
FedDA-TSformer: Federated Domain Adaptation with Vision TimeSformer for Left Ventricle Segmentation on Gated Myocardial Perfusion SPECT Image
Feb 23, 2025Background and Purpose: Functional assessment of the left ventricle using gated myocardial perfusion (MPS) single-photon emission computed tomography relies on the precise extraction of the left ventricular contours while simultaneously ensuring the security of patient data. Methods: In this paper, we introduce the integration of Federated Domain Adaptation with TimeSformer, named 'FedDA-TSformer' for left ventricle segmentation using MPS. FedDA-TSformer captures spatial and temporal features in gated MPS images, leveraging spatial attention, temporal attention, and federated learning for improved domain adaptation while ensuring patient data security. In detail, we employed Divide-Space-Time-Attention mechanism to extract spatio-temporal correlations from the multi-centered MPS datasets, ensuring that predictions are spatio-temporally consistent. To achieve domain adaptation, we align the model output on MPS from three different centers using local maximum mean discrepancy (LMMD) loss. This approach effectively addresses the dual requirements of federated learning and domain adaptation, enhancing the model's performance during training with multi-site datasets while ensuring the protection of data from different hospitals. Results: Our FedDA-TSformer was trained and evaluated using MPS datasets collected from three hospitals, comprising a total of 150 subjects. Each subject's cardiac cycle was divided into eight gates. The model achieved Dice Similarity Coefficients (DSC) of 0.842 and 0.907 for left ventricular (LV) endocardium and epicardium segmentation, respectively. Conclusion: Our proposed FedDA-TSformer model addresses the challenge of multi-center generalization, ensures patient data privacy protection, and demonstrates effectiveness in left ventricular (LV) segmentation.
MsMorph: An Unsupervised pyramid learning network for brain image registration
Oct 23, 2024In the field of medical image analysis, image registration is a crucial technique. Despite the numerous registration models that have been proposed, existing methods still fall short in terms of accuracy and interpretability. In this paper, we present MsMorph, a deep learning-based image registration framework aimed at mimicking the manual process of registering image pairs to achieve more similar deformations, where the registered image pairs exhibit consistency or similarity in features. By extracting the feature differences between image pairs across various as-pects using gradients, the framework decodes semantic information at different scales and continuously compen-sates for the predicted deformation field, driving the optimization of parameters to significantly improve registration accuracy. The proposed method simulates the manual approach to registration, focusing on different regions of the image pairs and their neighborhoods to predict the deformation field between the two images, which provides strong interpretability. We compared several existing registration methods on two public brain MRI datasets, including LPBA and Mindboggle. The experimental results show that our method consistently outperforms state of the art in terms of metrics such as Dice score, Hausdorff distance, average symmetric surface distance, and non-Jacobian. The source code is publicly available at https://github.com/GaodengFan/MsMorph