 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA New Framework to Analyse the Distributional Robustness of Deep Neural Networks
May 20, 2026Deep neural networks have achieved impressive performance on a variety of tasks, but their brittleness to distributional shifts remains a significant barrier to real-world deployment. In this paper, we propose a framework to analyse and quantify the distributional robustness of neural networks by studying the interactions between layer weights and activations. We model these interactions using Bernoulli distributions, using the separation between classes as a diagnostic proxy for robustness. We demonstrate the usefulness of this framework through models trained on CIFAR-10 and ImageNet. We show that our proposed metrics can distinguish between networks that have memorised their training data and those that have not. We also perform analogous experiments in the activation space and find that the same properties do not hold up. Additionally, we investigate the behaviour of our metrics under various distribution shifts and show that these shifts reduce separation under our path-based diagnostics. Our results suggest that this framework provides useful model-level diagnostics of representation structure and robustness.
From Forks to Forceps: A New Framework for Instance Segmentation of Surgical Instruments
Nov 26, 2022



Minimally invasive surgeries and related applications demand surgical tool classification and segmentation at the instance level. Surgical tools are similar in appearance and are long, thin, and handled at an angle. The fine-tuning of state-of-the-art (SOTA) instance segmentation models trained on natural images for instrument segmentation has difficulty discriminating instrument classes. Our research demonstrates that while the bounding box and segmentation mask are often accurate, the classification head mis-classifies the class label of the surgical instrument. We present a new neural network framework that adds a classification module as a new stage to existing instance segmentation models. This module specializes in improving the classification of instrument masks generated by the existing model. The module comprises multi-scale mask attention, which attends to the instrument region and masks the distracting background features. We propose training our classifier module using metric learning with arc loss to handle low inter-class variance of surgical instruments. We conduct exhaustive experiments on the benchmark datasets EndoVis2017 and EndoVis2018. We demonstrate that our method outperforms all (more than 18) SOTA methods compared with, and improves the SOTA performance by at least 12 points (20%) on the EndoVis2017 benchmark challenge and generalizes effectively across the datasets.
QU-BraTS: MICCAI BraTS 2020 Challenge on Quantifying Uncertainty in Brain Tumor Segmentation -- Analysis of Ranking Metrics and Benchmarking Results
Dec 19, 2021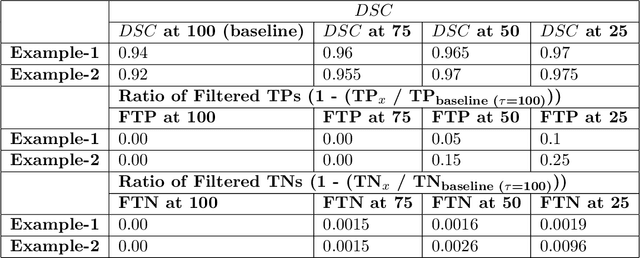
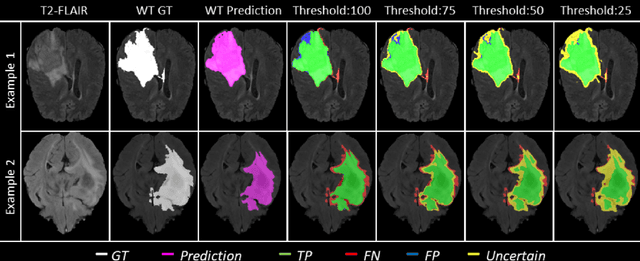
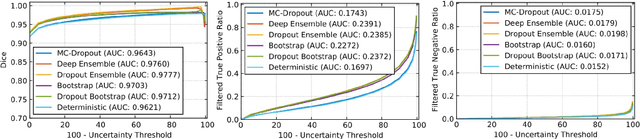
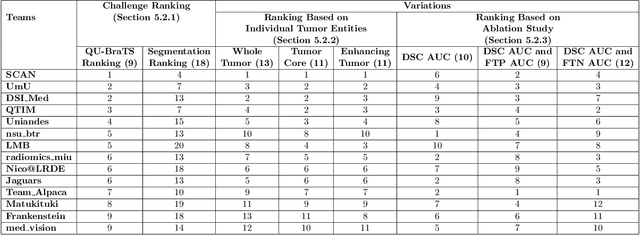
Deep learning (DL) models have provided the state-of-the-art performance in a wide variety of medical imaging benchmarking challenges, including the Brain Tumor Segmentation (BraTS) challenges. However, the task of focal pathology multi-compartment segmentation (e.g., tumor and lesion sub-regions) is particularly challenging, and potential errors hinder the translation of DL models into clinical workflows. Quantifying the reliability of DL model predictions in the form of uncertainties, could enable clinical review of the most uncertain regions, thereby building trust and paving the way towards clinical translation. Recently, a number of uncertainty estimation methods have been introduced for DL medical image segmentation tasks. Developing metrics to evaluate and compare the performance of uncertainty measures will assist the end-user in making more informed decisions. In this study, we explore and evaluate a metric developed during the BraTS 2019-2020 task on uncertainty quantification (QU-BraTS), and designed to assess and rank uncertainty estimates for brain tumor multi-compartment segmentation. This metric (1) rewards uncertainty estimates that produce high confidence in correct assertions, and those that assign low confidence levels at incorrect assertions, and (2) penalizes uncertainty measures that lead to a higher percentages of under-confident correct assertions. We further benchmark the segmentation uncertainties generated by 14 independent participating teams of QU-BraTS 2020, all of which also participated in the main BraTS segmentation task. Overall, our findings confirm the importance and complementary value that uncertainty estimates provide to segmentation algorithms, and hence highlight the need for uncertainty quantification in medical image analyses. Our evaluation code is made publicly available at https://github.com/RagMeh11/QU-BraTS.
Analysis of MRI Biomarkers for Brain Cancer Survival Prediction
Sep 03, 2021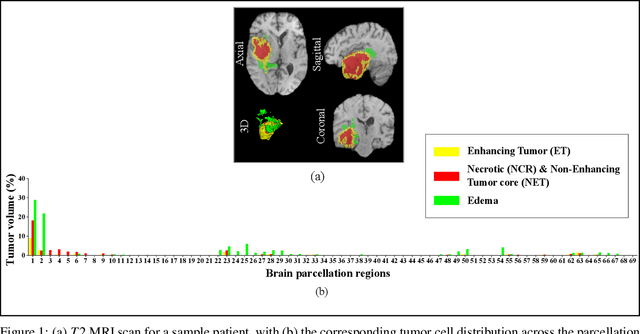
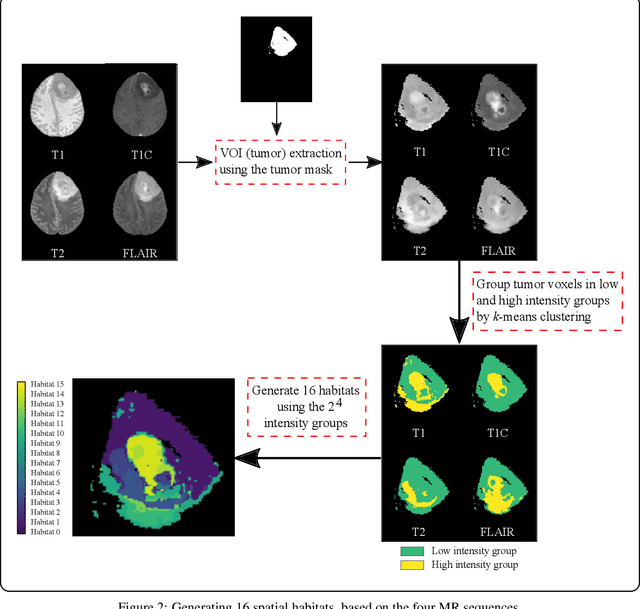
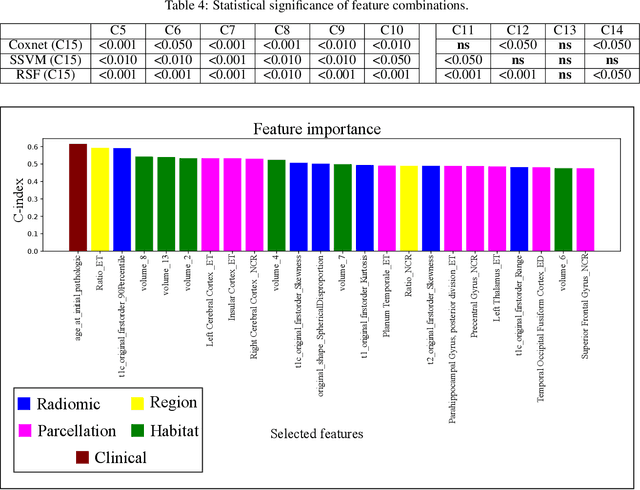
Prediction of Overall Survival (OS) of brain cancer patients from multi-modal MRI is a challenging field of research. Most of the existing literature on survival prediction is based on Radiomic features, which does not consider either non-biological factors or the functional neurological status of the patient(s). Besides, the selection of an appropriate cut-off for survival and the presence of censored data create further problems. Application of deep learning models for OS prediction is also limited due to the lack of large annotated publicly available datasets. In this scenario we analyse the potential of two novel neuroimaging feature families, extracted from brain parcellation atlases and spatial habitats, along with classical radiomic and geometric features; to study their combined predictive power for analysing overall survival. A cross validation strategy with grid search is proposed to simultaneously select and evaluate the most predictive feature subset based on its predictive power. A Cox Proportional Hazard (CoxPH) model is employed for univariate feature selection, followed by the prediction of patient-specific survival functions by three multivariate parsimonious models viz. Coxnet, Random survival forests (RSF) and Survival SVM (SSVM). The brain cancer MRI data used for this research was taken from two open-access collections TCGA-GBM and TCGA-LGG available from The Cancer Imaging Archive (TCIA). Corresponding survival data for each patient was downloaded from The Cancer Genome Atlas (TCGA). A high cross validation $C-index$ score of $0.82\pm.10$ was achieved using RSF with the best $24$ selected features. Age was found to be the most important biological predictor. There were $9$, $6$, $6$ and $2$ features selected from the parcellation, habitat, radiomic and region-based feature groups respectively.
Dissecting Deep Networks into an Ensemble of Generative Classifiers for Robust Predictions
Jun 18, 2020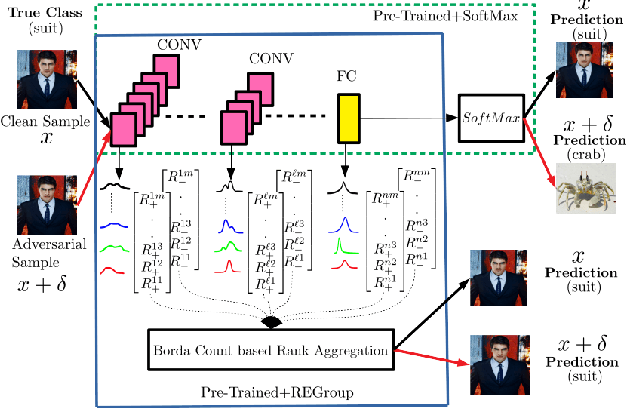
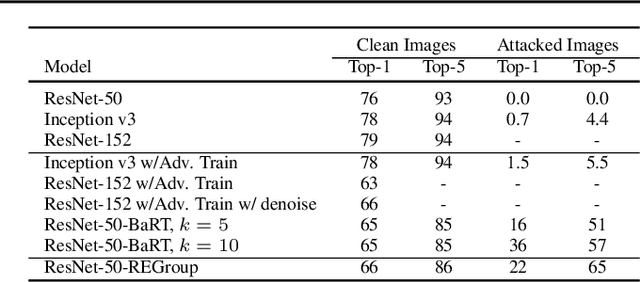
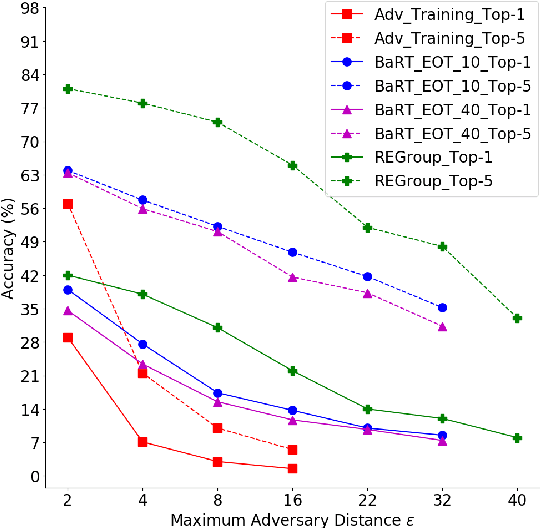
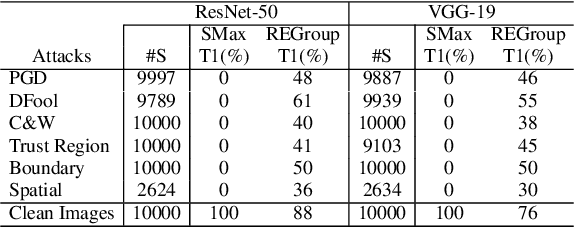
Deep Neural Networks (DNNs) are often criticized for being susceptible to adversarial attacks. Most successful defense strategies adopt adversarial training or random input transformations that typically require retraining or fine-tuning the model to achieve reasonable performance. In this work, our investigations of intermediate representations of a pre-trained DNN lead to an interesting discovery pointing to intrinsic robustness to adversarial attacks. We find that we can learn a generative classifier by statistically characterizing the neural response of an intermediate layer to clean training samples. The predictions of multiple such intermediate-layer based classifiers, when aggregated, show unexpected robustness to adversarial attacks. Specifically, we devise an ensemble of these generative classifiers that rank-aggregates their predictions via a Borda count-based consensus. Our proposed approach uses a subset of the clean training data and a pre-trained model, and yet is agnostic to network architectures or the adversarial attack generation method. We show extensive experiments to establish that our defense strategy achieves state-of-the-art performance on the ImageNet validation set.
CovidAID: COVID-19 Detection Using Chest X-Ray
Apr 21, 2020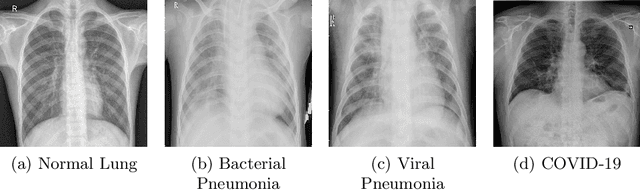
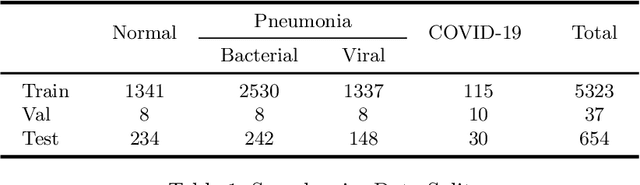

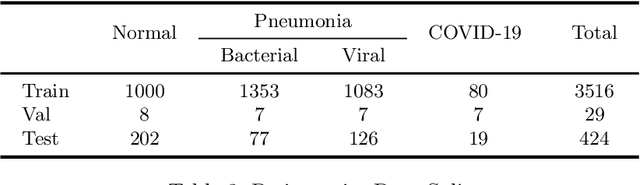
The exponential increase in COVID-19 patients is overwhelming healthcare systems across the world. With limited testing kits, it is impossible for every patient with respiratory illness to be tested using conventional techniques (RT-PCR). The tests also have long turn-around time, and limited sensitivity. Detecting possible COVID-19 infections on Chest X-Ray may help quarantine high risk patients while test results are awaited. X-Ray machines are already available in most healthcare systems, and with most modern X-Ray systems already digitized, there is no transportation time involved for the samples either. In this work we propose the use of chest X-Ray to prioritize the selection of patients for further RT-PCR testing. This may be useful in an inpatient setting where the present systems are struggling to decide whether to keep the patient in the ward along with other patients or isolate them in COVID-19 areas. It would also help in identifying patients with high likelihood of COVID with a false negative RT-PCR who would need repeat testing. Further, we propose the use of modern AI techniques to detect the COVID-19 patients using X-Ray images in an automated manner, particularly in settings where radiologists are not available, and help make the proposed testing technology scalable. We present CovidAID: COVID-19 AI Detector, a novel deep neural network based model to triage patients for appropriate testing. On the publicly available covid-chestxray-dataset [2], our model gives 90.5% accuracy with 100% sensitivity (recall) for the COVID-19 infection. We significantly improve upon the results of Covid-Net [10] on the same dataset.
Deep Radiomics for Brain Tumor Detection and Classification from Multi-Sequence MRI
Mar 21, 2019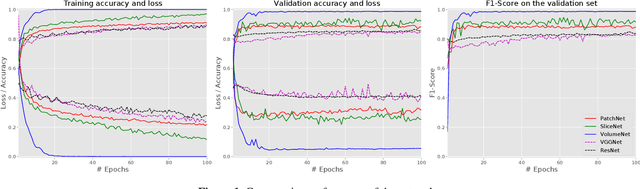
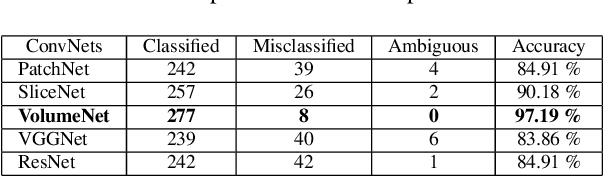
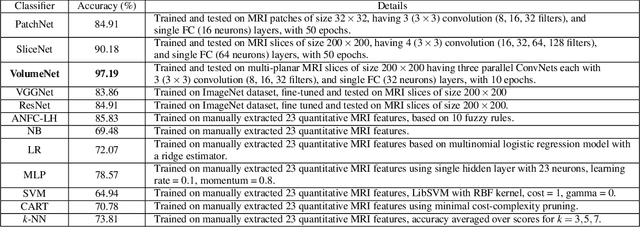
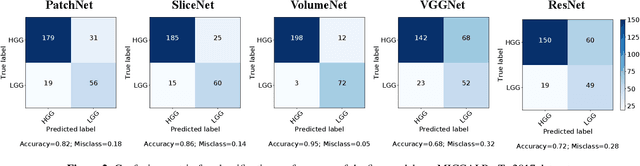
Glioma constitutes 80% of malignant primary brain tumors and is usually classified as HGG and LGG. The LGG tumors are less aggressive, with slower growth rate as compared to HGG, and are responsive to therapy. Tumor biopsy being challenging for brain tumor patients, noninvasive imaging techniques like Magnetic Resonance Imaging (MRI) have been extensively employed in diagnosing brain tumors. Therefore automated systems for the detection and prediction of the grade of tumors based on MRI data becomes necessary for assisting doctors in the framework of augmented intelligence. In this paper, we thoroughly investigate the power of Deep ConvNets for classification of brain tumors using multi-sequence MR images. We propose novel ConvNet models, which are trained from scratch, on MRI patches, slices, and multi-planar volumetric slices. The suitability of transfer learning for the task is next studied by applying two existing ConvNets models (VGGNet and ResNet) trained on ImageNet dataset, through fine-tuning of the last few layers. LOPO testing, and testing on the holdout dataset are used to evaluate the performance of the ConvNets. Results demonstrate that the proposed ConvNets achieve better accuracy in all cases where the model is trained on the multi-planar volumetric dataset. Unlike conventional models, it obtains a testing accuracy of 95% for the low/high grade glioma classification problem. A score of 97% is generated for classification of LGG with/without 1p/19q codeletion, without any additional effort towards extraction and selection of features. We study the properties of self-learned kernels/ filters in different layers, through visualization of the intermediate layer outputs. We also compare the results with that of state-of-the-art methods, demonstrating a maximum improvement of 7% on the grading performance of ConvNets and 9% on the prediction of 1p/19q codeletion status.
A Joint 3D-2D based Method for Free Space Detection on Roads
Jan 15, 2018

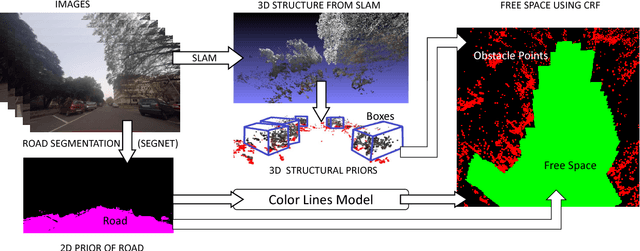
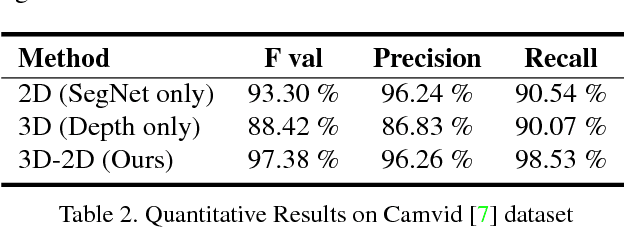
In this paper, we address the problem of road segmentation and free space detection in the context of autonomous driving. Traditional methods either use 3-dimensional (3D) cues such as point clouds obtained from LIDAR, RADAR or stereo cameras or 2-dimensional (2D) cues such as lane markings, road boundaries and object detection. Typical 3D point clouds do not have enough resolution to detect fine differences in heights such as between road and pavement. Image based 2D cues fail when encountering uneven road textures such as due to shadows, potholes, lane markings or road restoration. We propose a novel free road space detection technique combining both 2D and 3D cues. In particular, we use CNN based road segmentation from 2D images and plane/box fitting on sparse depth data obtained from SLAM as priors to formulate an energy minimization using conditional random field (CRF), for road pixels classification. While the CNN learns the road texture and is unaffected by depth boundaries, the 3D information helps in overcoming texture based classification failures. Finally, we use the obtained road segmentation with the 3D depth data from monocular SLAM to detect the free space for the navigation purposes. Our experiments on KITTI odometry dataset, Camvid dataset, as well as videos captured by us, validate the superiority of the proposed approach over the state of the art.
Batch based Monocular SLAM for Egocentric Videos
Jul 18, 2017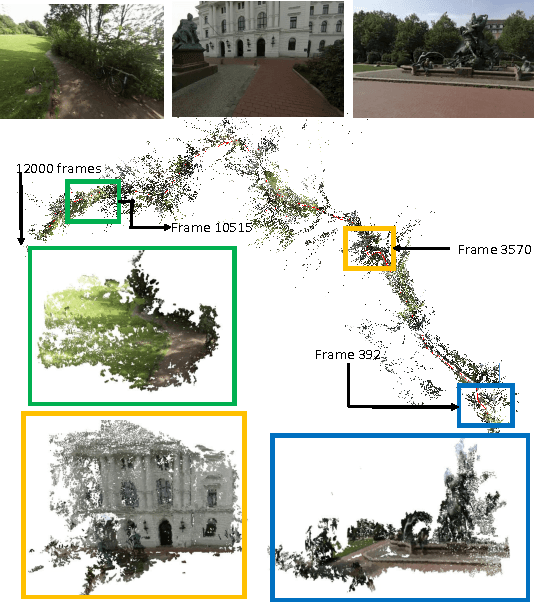

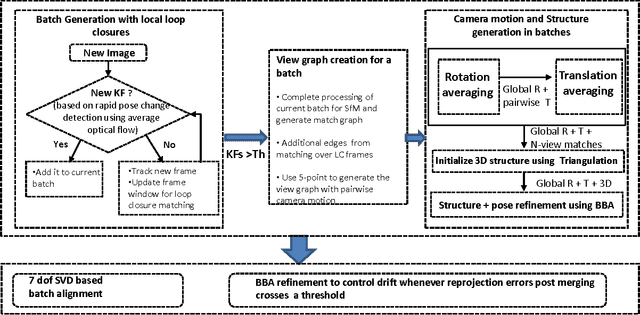
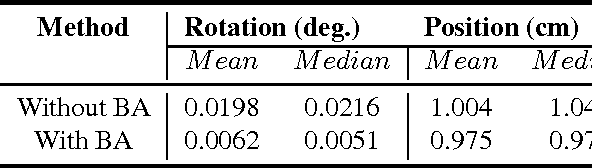
Simultaneous Localization and Mapping (SLAM) from a monocular camera has been a well researched area. However, estimating camera pose and 3d geometry reliably for egocentric videos still remain a challenge. Some of the common causes of failures are dominant 3D rotations and low parallax between successive frames, resulting in unreliable pose and 3d estimates. For forward moving cameras, with no opportunities for loop closures, the drift leads to eventual failures for traditional feature based and direct SLAM techniques. We propose a novel batch mode structure from motion based technique for robust SLAM in such scenarios. In contrast to most of the existing techniques, we process frames in short batches, wherein we exploit short loop closures arising out of to-and-fro motion of wearer's head, and stabilize the egomotion estimates by 2D batch mode techniques such as motion averaging on pairwise epipolar results. Once pose estimates are obtained reliably over a batch, we refine the 3d estimate by triangulation and batch mode Bundle Adjustment (BA). Finally, we merge the batches using 3D correspondences and carry out a BA refinement post merging. We present both qualitative and quantitative comparison of our method on various public first and third person video datasets, to establish the robustness and accuracy of our algorithm over the state of the art.
Computing Egomotion with Local Loop Closures for Egocentric Videos
Jan 17, 2017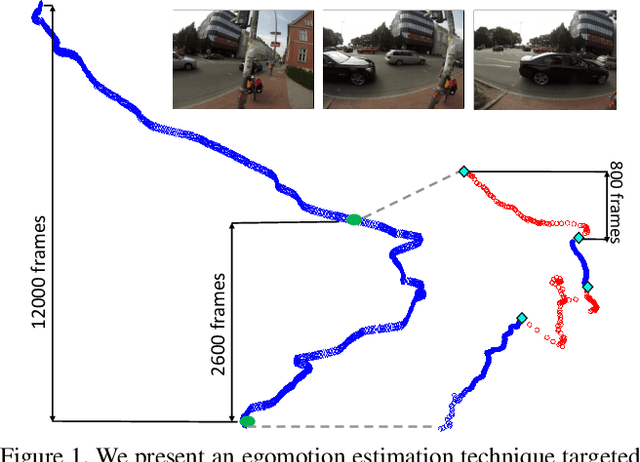
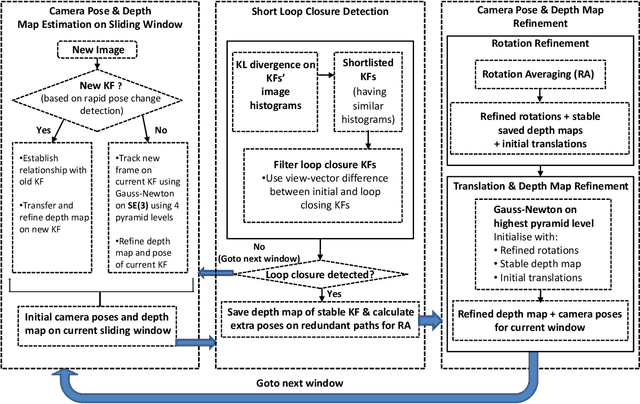

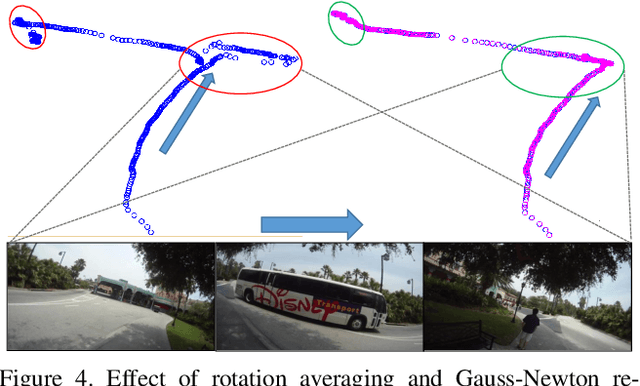
Finding the camera pose is an important step in many egocentric video applications. It has been widely reported that, state of the art SLAM algorithms fail on egocentric videos. In this paper, we propose a robust method for camera pose estimation, designed specifically for egocentric videos. In an egocentric video, the camera views the same scene point multiple times as the wearer's head sweeps back and forth. We use this specific motion profile to perform short loop closures aligned with wearer's footsteps. For egocentric videos, depth estimation is usually noisy. In an important departure, we use 2D computations for rotation averaging which do not rely upon depth estimates. The two modification results in much more stable algorithm as is evident from our experiments on various egocentric video datasets for different egocentric applications. The proposed algorithm resolves a long standing problem in egocentric vision and unlocks new usage scenarios for future applications.