 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOffline Meta-Reinforcement Learning for Industrial Insertion
Oct 12, 2021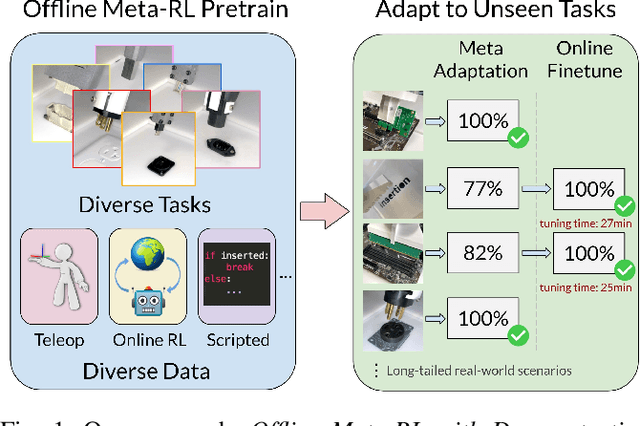
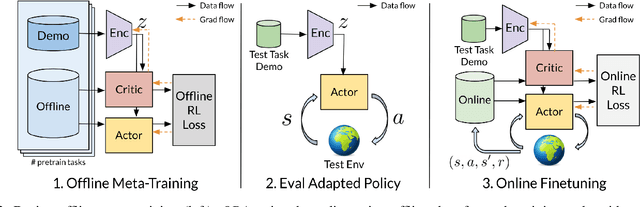


Reinforcement learning (RL) can in principle make it possible for robots to automatically adapt to new tasks, but in practice current RL methods require a very large number of trials to accomplish this. In this paper, we tackle rapid adaptation to new tasks through the framework of meta-learning, which utilizes past tasks to learn to adapt, with a specific focus on industrial insertion tasks. We address two specific challenges by applying meta-learning in this setting. First, conventional meta-RL algorithms require lengthy online meta-training phases. We show that this can be replaced with appropriately chosen offline data, resulting in an offline meta-RL method that only requires demonstrations and trials from each of the prior tasks, without the need to run costly meta-RL procedures online. Second, meta-RL methods can fail to generalize to new tasks that are too different from those seen at meta-training time, which poses a particular challenge in industrial applications, where high success rates are critical. We address this by combining contextual meta-learning with direct online finetuning: if the new task is similar to those seen in the prior data, then the contextual meta-learner adapts immediately, and if it is too different, it gradually adapts through finetuning. We show that our approach is able to quickly adapt to a variety of different insertion tasks, learning how to perform them with a success rate of 100% using only a fraction of the samples needed for learning the tasks from scratch. Experiment videos and details are available at https://sites.google.com/view/offline-metarl-insertion.
Evaluating model-based planning and planner amortization for continuous control
Oct 07, 2021
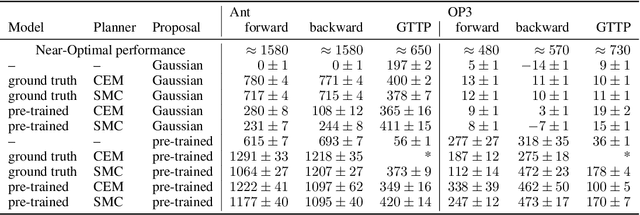
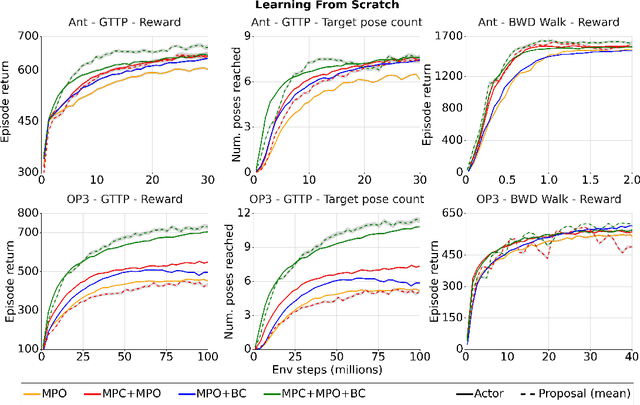
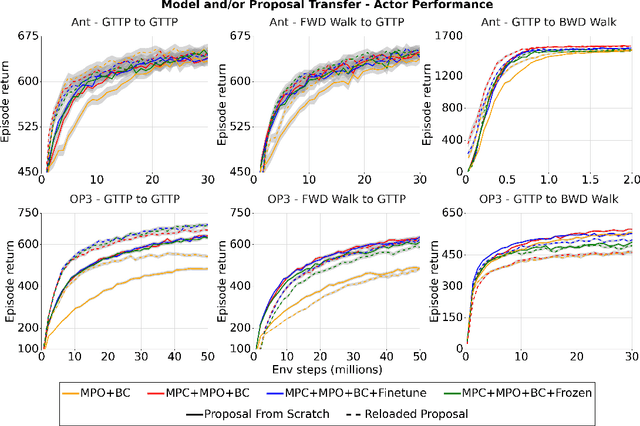
There is a widespread intuition that model-based control methods should be able to surpass the data efficiency of model-free approaches. In this paper we attempt to evaluate this intuition on various challenging locomotion tasks. We take a hybrid approach, combining model predictive control (MPC) with a learned model and model-free policy learning; the learned policy serves as a proposal for MPC. We find that well-tuned model-free agents are strong baselines even for high DoF control problems but MPC with learned proposals and models (trained on the fly or transferred from related tasks) can significantly improve performance and data efficiency in hard multi-task/multi-goal settings. Finally, we show that it is possible to distil a model-based planner into a policy that amortizes the planning computation without any loss of performance. Videos of agents performing different tasks can be seen at https://sites.google.com/view/mbrl-amortization/home.
Learning Dynamics Models for Model Predictive Agents
Sep 29, 2021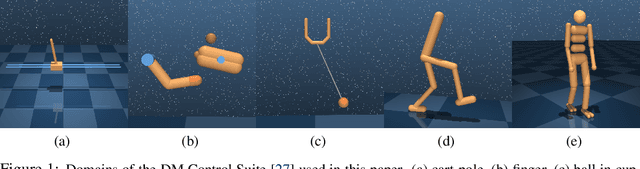
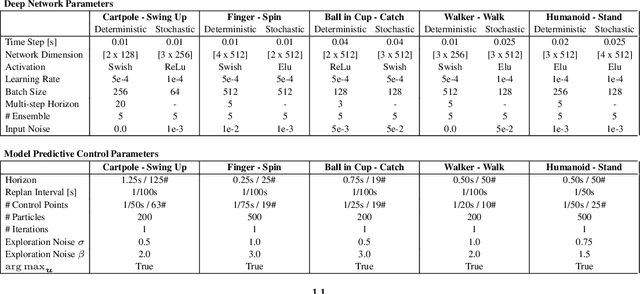
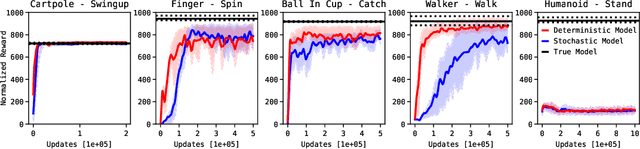
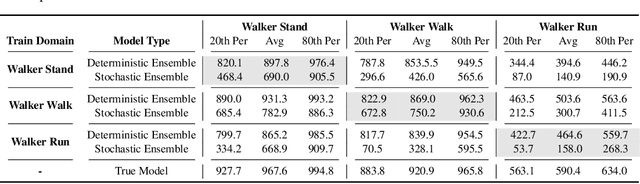
Model-Based Reinforcement Learning involves learning a \textit{dynamics model} from data, and then using this model to optimise behaviour, most often with an online \textit{planner}. Much of the recent research along these lines presents a particular set of design choices, involving problem definition, model learning and planning. Given the multiple contributions, it is difficult to evaluate the effects of each. This paper sets out to disambiguate the role of different design choices for learning dynamics models, by comparing their performance to planning with a ground-truth model -- the simulator. First, we collect a rich dataset from the training sequence of a model-free agent on 5 domains of the DeepMind Control Suite. Second, we train feed-forward dynamics models in a supervised fashion, and evaluate planner performance while varying and analysing different model design choices, including ensembling, stochasticity, multi-step training and timestep size. Besides the quantitative analysis, we describe a set of qualitative findings, rules of thumb, and future research directions for planning with learned dynamics models. Videos of the results are available at https://sites.google.com/view/learning-better-models.
Is Curiosity All You Need? On the Utility of Emergent Behaviours from Curious Exploration
Sep 17, 2021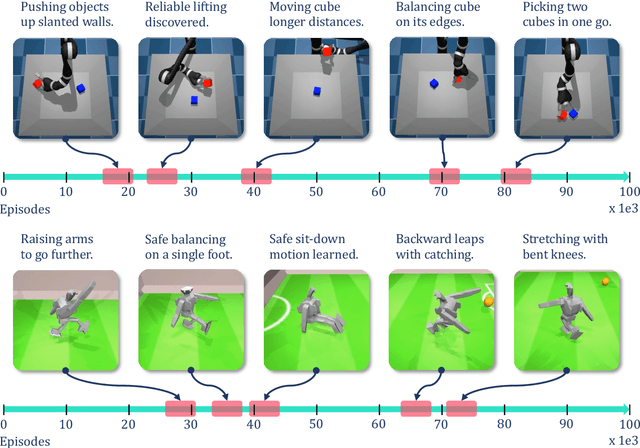


Curiosity-based reward schemes can present powerful exploration mechanisms which facilitate the discovery of solutions for complex, sparse or long-horizon tasks. However, as the agent learns to reach previously unexplored spaces and the objective adapts to reward new areas, many behaviours emerge only to disappear due to being overwritten by the constantly shifting objective. We argue that merely using curiosity for fast environment exploration or as a bonus reward for a specific task does not harness the full potential of this technique and misses useful skills. Instead, we propose to shift the focus towards retaining the behaviours which emerge during curiosity-based learning. We posit that these self-discovered behaviours serve as valuable skills in an agent's repertoire to solve related tasks. Our experiments demonstrate the continuous shift in behaviour throughout training and the benefits of a simple policy snapshot method to reuse discovered behaviour for transfer tasks.
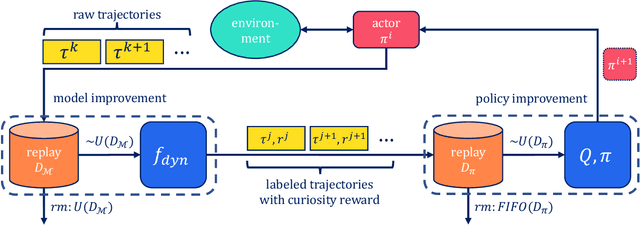
Collect & Infer -- a fresh look at data-efficient Reinforcement Learning
Aug 23, 2021This position paper proposes a fresh look at Reinforcement Learning (RL) from the perspective of data-efficiency. Data-efficient RL has gone through three major stages: pure on-line RL where every data-point is considered only once, RL with a replay buffer where additional learning is done on a portion of the experience, and finally transition memory based RL, where, conceptually, all transitions are stored and re-used in every update step. While inferring knowledge from all explicitly stored experience has lead to a tremendous gain in data-efficiency, the question of how this data is collected has been vastly understudied. We argue that data-efficiency can only be achieved through careful consideration of both aspects. We propose to make this insight explicit via a paradigm that we call 'Collect and Infer', which explicitly models RL as two separate but interconnected processes, concerned with data collection and knowledge inference respectively. We discuss implications of the paradigm, how its ideas are reflected in the literature, and how it can guide future research into data efficient RL.
On Multi-objective Policy Optimization as a Tool for Reinforcement Learning
Jun 15, 2021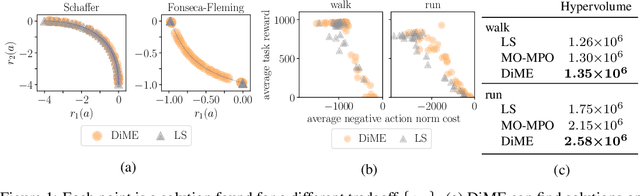
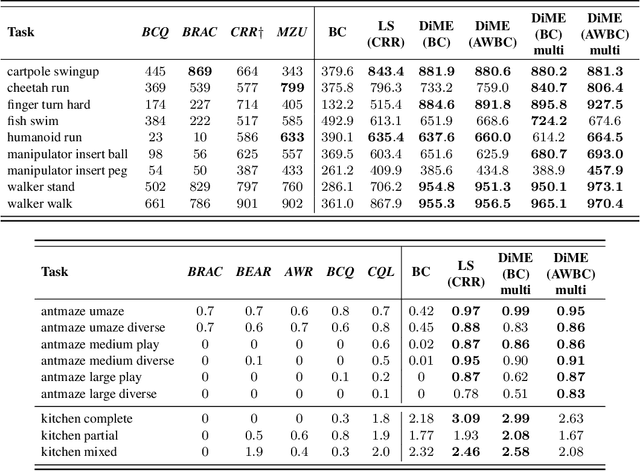
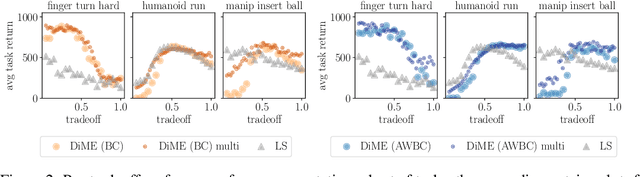

Many advances that have improved the robustness and efficiency of deep reinforcement learning (RL) algorithms can, in one way or another, be understood as introducing additional objectives, or constraints, in the policy optimization step. This includes ideas as far ranging as exploration bonuses, entropy regularization, and regularization toward teachers or data priors when learning from experts or in offline RL. Often, task reward and auxiliary objectives are in conflict with each other and it is therefore natural to treat these examples as instances of multi-objective (MO) optimization problems. We study the principles underlying MORL and introduce a new algorithm, Distillation of a Mixture of Experts (DiME), that is intuitive and scale-invariant under some conditions. We highlight its strengths on standard MO benchmark problems and consider case studies in which we recast offline RL and learning from experts as MO problems. This leads to a natural algorithmic formulation that sheds light on the connection between existing approaches. For offline RL, we use the MO perspective to derive a simple algorithm, that optimizes for the standard RL objective plus a behavioral cloning term. This outperforms state-of-the-art on two established offline RL benchmarks.
From Motor Control to Team Play in Simulated Humanoid Football
May 25, 2021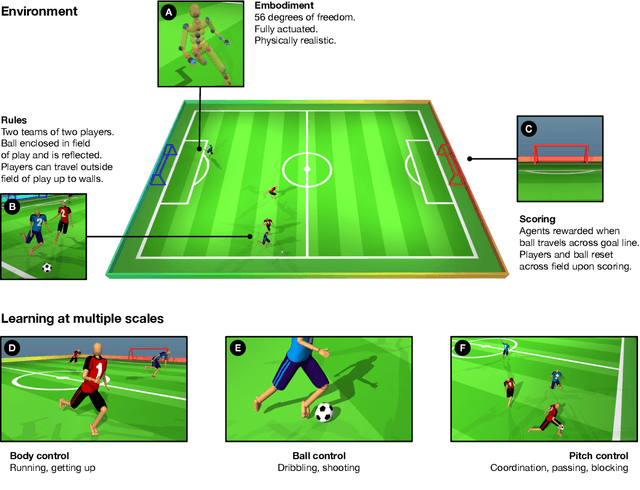

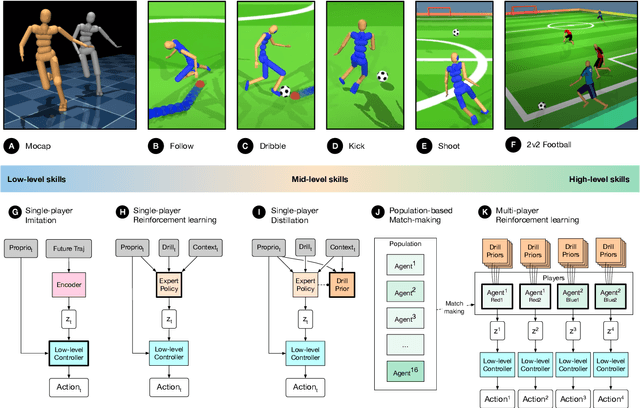

Intelligent behaviour in the physical world exhibits structure at multiple spatial and temporal scales. Although movements are ultimately executed at the level of instantaneous muscle tensions or joint torques, they must be selected to serve goals defined on much longer timescales, and in terms of relations that extend far beyond the body itself, ultimately involving coordination with other agents. Recent research in artificial intelligence has shown the promise of learning-based approaches to the respective problems of complex movement, longer-term planning and multi-agent coordination. However, there is limited research aimed at their integration. We study this problem by training teams of physically simulated humanoid avatars to play football in a realistic virtual environment. We develop a method that combines imitation learning, single- and multi-agent reinforcement learning and population-based training, and makes use of transferable representations of behaviour for decision making at different levels of abstraction. In a sequence of stages, players first learn to control a fully articulated body to perform realistic, human-like movements such as running and turning; they then acquire mid-level football skills such as dribbling and shooting; finally, they develop awareness of others and play as a team, bridging the gap between low-level motor control at a timescale of milliseconds, and coordinated goal-directed behaviour as a team at the timescale of tens of seconds. We investigate the emergence of behaviours at different levels of abstraction, as well as the representations that underlie these behaviours using several analysis techniques, including statistics from real-world sports analytics. Our work constitutes a complete demonstration of integrated decision-making at multiple scales in a physically embodied multi-agent setting. See project video at https://youtu.be/KHMwq9pv7mg.
Neural Production Systems
Mar 02, 2021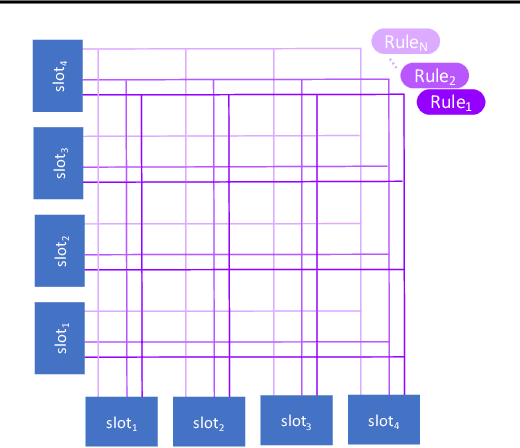

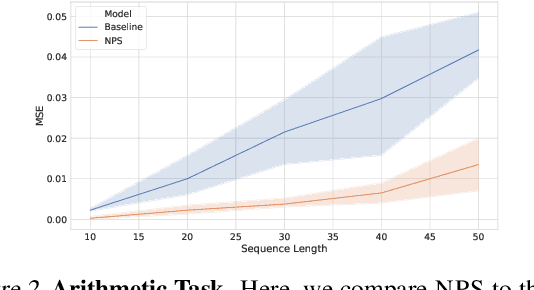
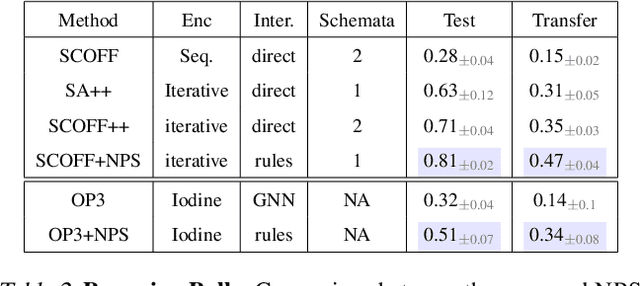
Visual environments are structured, consisting of distinct objects or entities. These entities have properties -- both visible and latent -- that determine the manner in which they interact with one another. To partition images into entities, deep-learning researchers have proposed structural inductive biases such as slot-based architectures. To model interactions among entities, equivariant graph neural nets (GNNs) are used, but these are not particularly well suited to the task for two reasons. First, GNNs do not predispose interactions to be sparse, as relationships among independent entities are likely to be. Second, GNNs do not factorize knowledge about interactions in an entity-conditional manner. As an alternative, we take inspiration from cognitive science and resurrect a classic approach, production systems, which consist of a set of rule templates that are applied by binding placeholder variables in the rules to specific entities. Rules are scored on their match to entities, and the best fitting rules are applied to update entity properties. In a series of experiments, we demonstrate that this architecture achieves a flexible, dynamic flow of control and serves to factorize entity-specific and rule-based information. This disentangling of knowledge achieves robust future-state prediction in rich visual environments, outperforming state-of-the-art methods using GNNs, and allows for the extrapolation from simple (few object) environments to more complex environments.
Counterfactual Credit Assignment in Model-Free Reinforcement Learning
Nov 18, 2020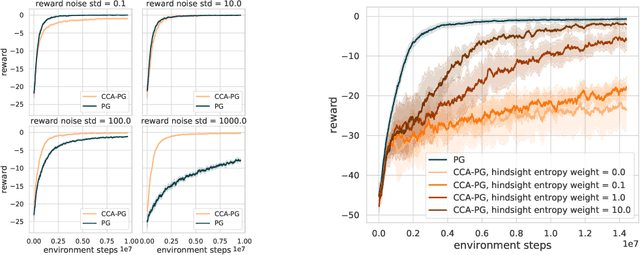
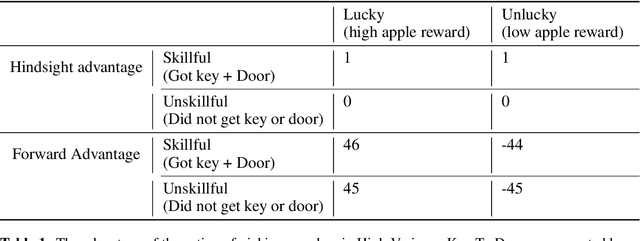

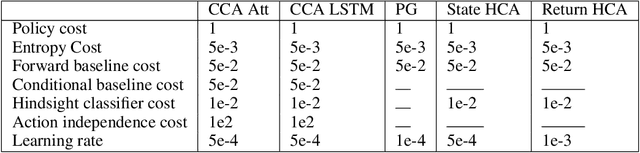
Credit assignment in reinforcement learning is the problem of measuring an action influence on future rewards. In particular, this requires separating skill from luck, ie. disentangling the effect of an action on rewards from that of external factors and subsequent actions. To achieve this, we adapt the notion of counterfactuals from causality theory to a model-free RL setup. The key idea is to condition value functions on future events, by learning to extract relevant information from a trajectory. We then propose to use these as future-conditional baselines and critics in policy gradient algorithms and we develop a valid, practical variant with provably lower variance, while achieving unbiasedness by constraining the hindsight information not to contain information about the agent actions. We demonstrate the efficacy and validity of our algorithm on a number of illustrative problems.
Game Plan: What AI can do for Football, and What Football can do for AI
Nov 18, 2020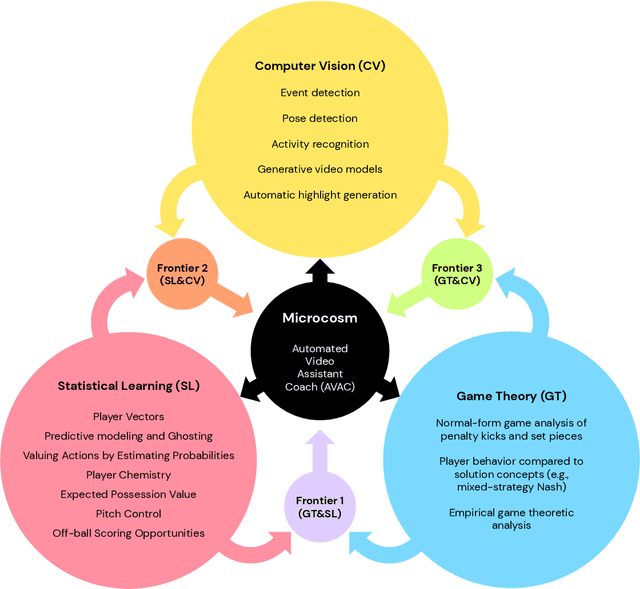



The rapid progress in artificial intelligence (AI) and machine learning has opened unprecedented analytics possibilities in various team and individual sports, including baseball, basketball, and tennis. More recently, AI techniques have been applied to football, due to a huge increase in data collection by professional teams, increased computational power, and advances in machine learning, with the goal of better addressing new scientific challenges involved in the analysis of both individual players' and coordinated teams' behaviors. The research challenges associated with predictive and prescriptive football analytics require new developments and progress at the intersection of statistical learning, game theory, and computer vision. In this paper, we provide an overarching perspective highlighting how the combination of these fields, in particular, forms a unique microcosm for AI research, while offering mutual benefits for professional teams, spectators, and broadcasters in the years to come. We illustrate that this duality makes football analytics a game changer of tremendous value, in terms of not only changing the game of football itself, but also in terms of what this domain can mean for the field of AI. We review the state-of-the-art and exemplify the types of analysis enabled by combining the aforementioned fields, including illustrative examples of counterfactual analysis using predictive models, and the combination of game-theoretic analysis of penalty kicks with statistical learning of player attributes. We conclude by highlighting envisioned downstream impacts, including possibilities for extensions to other sports (real and virtual).