 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlphaStar Unplugged: Large-Scale Offline Reinforcement Learning
Aug 07, 2023



StarCraft II is one of the most challenging simulated reinforcement learning environments; it is partially observable, stochastic, multi-agent, and mastering StarCraft II requires strategic planning over long time horizons with real-time low-level execution. It also has an active professional competitive scene. StarCraft II is uniquely suited for advancing offline RL algorithms, both because of its challenging nature and because Blizzard has released a massive dataset of millions of StarCraft II games played by human players. This paper leverages that and establishes a benchmark, called AlphaStar Unplugged, introducing unprecedented challenges for offline reinforcement learning. We define a dataset (a subset of Blizzard's release), tools standardizing an API for machine learning methods, and an evaluation protocol. We also present baseline agents, including behavior cloning, offline variants of actor-critic and MuZero. We improve the state of the art of agents using only offline data, and we achieve 90% win rate against previously published AlphaStar behavior cloning agent.
Exploring the Space of Key-Value-Query Models with Intention
May 17, 2023Attention-based models have been a key element of many recent breakthroughs in deep learning. Two key components of Attention are the structure of its input (which consists of keys, values and queries) and the computations by which these three are combined. In this paper we explore the space of models that share said input structure but are not restricted to the computations of Attention. We refer to this space as Keys-Values-Queries (KVQ) Space. Our goal is to determine whether there are any other stackable models in KVQ Space that Attention cannot efficiently approximate, which we can implement with our current deep learning toolbox and that solve problems that are interesting to the community. Maybe surprisingly, the solution to the standard least squares problem satisfies these properties. A neural network module that is able to compute this solution not only enriches the set of computations that a neural network can represent but is also provably a strict generalisation of Linear Attention. Even more surprisingly the computational complexity of this module is exactly the same as that of Attention, making it a suitable drop in replacement. With this novel connection between classical machine learning (least squares) and modern deep learning (Attention) established we justify a variation of our model which generalises regular Attention in the same way. Both new modules are put to the test an a wide spectrum of tasks ranging from few-shot learning to policy distillation that confirm their real-worlds applicability.
On the Limitations of Elo: Real-World Games, are Transitive, not Additive
Jun 21, 2022
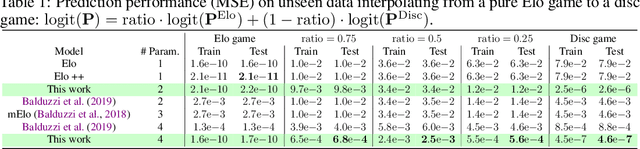
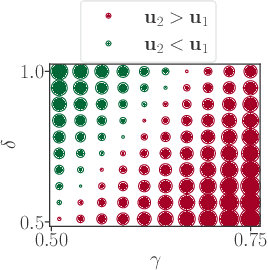
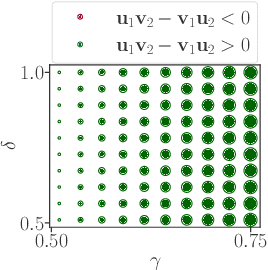
Real-world competitive games, such as chess, go, or StarCraft II, rely on Elo models to measure the strength of their players. Since these games are not fully transitive, using Elo implicitly assumes they have a strong transitive component that can correctly be identified and extracted. In this study, we investigate the challenge of identifying the strength of the transitive component in games. First, we show that Elo models can fail to extract this transitive component, even in elementary transitive games. Then, based on this observation, we propose an extension of the Elo score: we end up with a disc ranking system that assigns each player two scores, which we refer to as skill and consistency. Finally, we propose an empirical validation on payoff matrices coming from real-world games played by bots and humans.
Pick Your Battles: Interaction Graphs as Population-Level Objectives for Strategic Diversity
Oct 08, 2021Strategic diversity is often essential in games: in multi-player games, for example, evaluating a player against a diverse set of strategies will yield a more accurate estimate of its performance. Furthermore, in games with non-transitivities diversity allows a player to cover several winning strategies. However, despite the significance of strategic diversity, training agents that exhibit diverse behaviour remains a challenge. In this paper we study how to construct diverse populations of agents by carefully structuring how individuals within a population interact. Our approach is based on interaction graphs, which control the flow of information between agents during training and can encourage agents to specialise on different strategies, leading to improved overall performance. We provide evidence for the importance of diversity in multi-agent training and analyse the effect of applying different interaction graphs on the training trajectories, diversity and performance of populations in a range of games. This is an extended version of the long abstract published at AAMAS.
Open-Ended Learning Leads to Generally Capable Agents
Jul 31, 2021
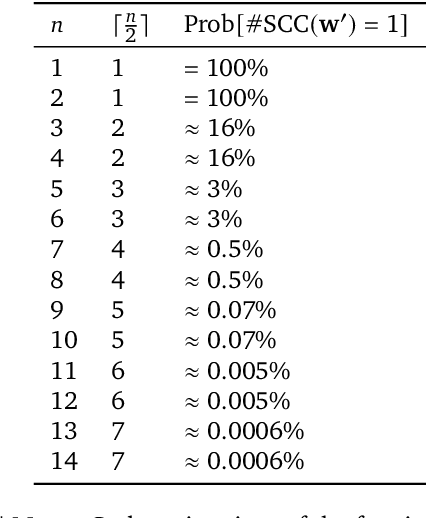
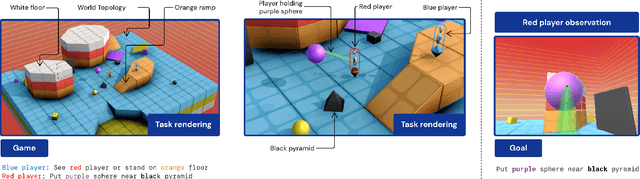

In this work we create agents that can perform well beyond a single, individual task, that exhibit much wider generalisation of behaviour to a massive, rich space of challenges. We define a universe of tasks within an environment domain and demonstrate the ability to train agents that are generally capable across this vast space and beyond. The environment is natively multi-agent, spanning the continuum of competitive, cooperative, and independent games, which are situated within procedurally generated physical 3D worlds. The resulting space is exceptionally diverse in terms of the challenges posed to agents, and as such, even measuring the learning progress of an agent is an open research problem. We propose an iterative notion of improvement between successive generations of agents, rather than seeking to maximise a singular objective, allowing us to quantify progress despite tasks being incomparable in terms of achievable rewards. We show that through constructing an open-ended learning process, which dynamically changes the training task distributions and training objectives such that the agent never stops learning, we achieve consistent learning of new behaviours. The resulting agent is able to score reward in every one of our humanly solvable evaluation levels, with behaviour generalising to many held-out points in the universe of tasks. Examples of this zero-shot generalisation include good performance on Hide and Seek, Capture the Flag, and Tag. Through analysis and hand-authored probe tasks we characterise the behaviour of our agent, and find interesting emergent heuristic behaviours such as trial-and-error experimentation, simple tool use, option switching, and cooperation. Finally, we demonstrate that the general capabilities of this agent could unlock larger scale transfer of behaviour through cheap finetuning.
Behavior Priors for Efficient Reinforcement Learning
Oct 27, 2020
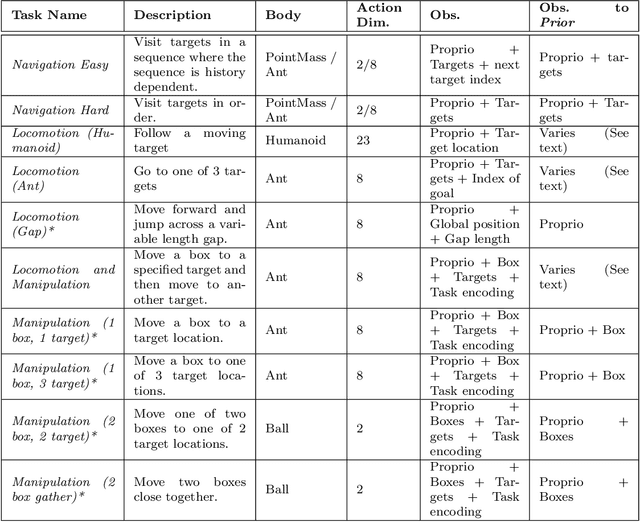
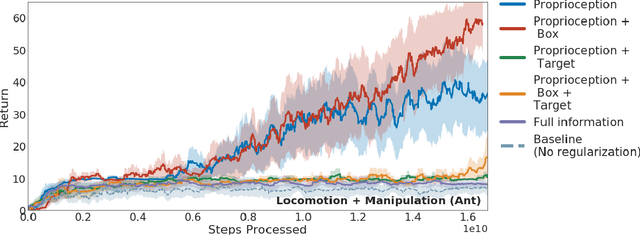

As we deploy reinforcement learning agents to solve increasingly challenging problems, methods that allow us to inject prior knowledge about the structure of the world and effective solution strategies becomes increasingly important. In this work we consider how information and architectural constraints can be combined with ideas from the probabilistic modeling literature to learn behavior priors that capture the common movement and interaction patterns that are shared across a set of related tasks or contexts. For example the day-to day behavior of humans comprises distinctive locomotion and manipulation patterns that recur across many different situations and goals. We discuss how such behavior patterns can be captured using probabilistic trajectory models and how these can be integrated effectively into reinforcement learning schemes, e.g.\ to facilitate multi-task and transfer learning. We then extend these ideas to latent variable models and consider a formulation to learn hierarchical priors that capture different aspects of the behavior in reusable modules. We discuss how such latent variable formulations connect to related work on hierarchical reinforcement learning (HRL) and mutual information and curiosity based objectives, thereby offering an alternative perspective on existing ideas. We demonstrate the effectiveness of our framework by applying it to a range of simulated continuous control domains.
Real World Games Look Like Spinning Tops
Apr 20, 2020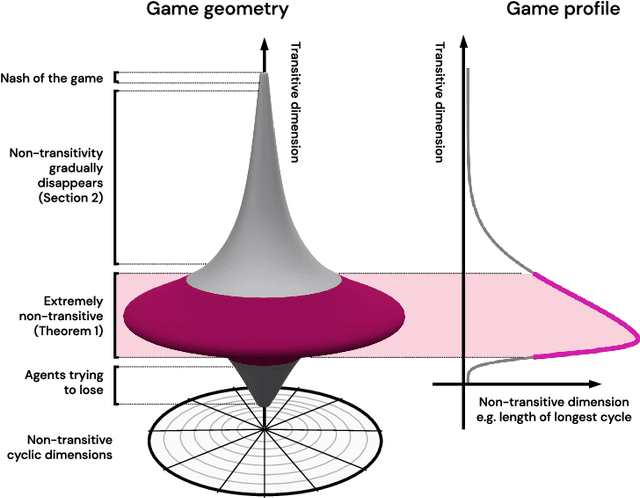
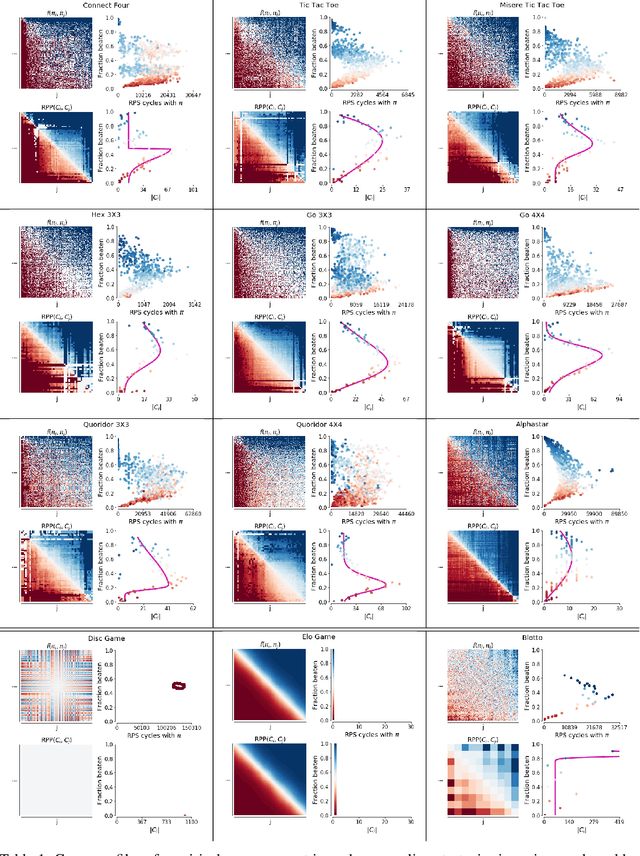
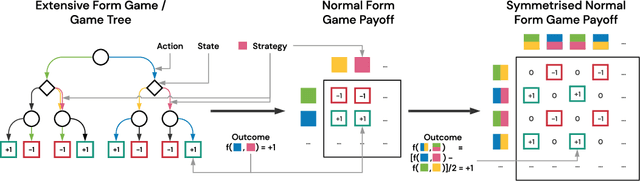
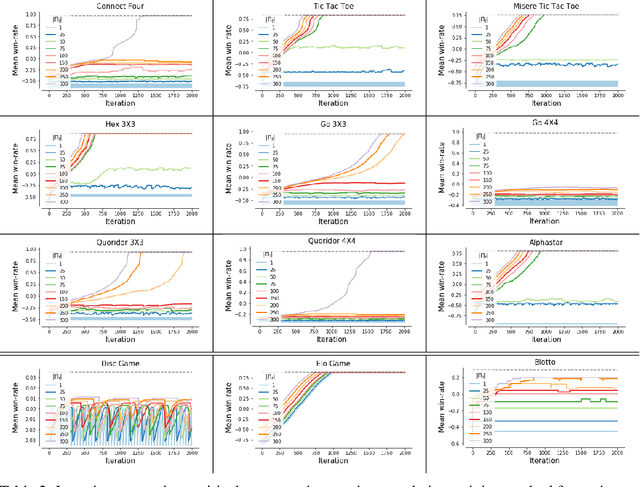
This paper investigates the geometrical properties of real world games (e.g. Tic-Tac-Toe, Go, StarCraft II). We hypothesise that their geometrical structure resemble a spinning top, with the upright axis representing transitive strength, and the radial axis, which corresponds to the number of cycles that exist at a particular transitive strength, representing the non-transitive dimension. We prove the existence of this geometry for a wide class of real world games, exposing their temporal nature. Additionally, we show that this unique structure also has consequences for learning - it clarifies why populations of strategies are necessary for training of agents, and how population size relates to the structure of the game. Finally, we empirically validate these claims by using a selection of nine real world two-player zero-sum symmetric games, showing 1) the spinning top structure is revealed and can be easily re-constructed by using a new method of Nash clustering to measure the interaction between transitive and cyclical strategy behaviour, and 2) the effect that population size has on the convergence in these games.
Minimax Theorem for Latent Games or: How I Learned to Stop Worrying about Mixed-Nash and Love Neural Nets
Feb 14, 2020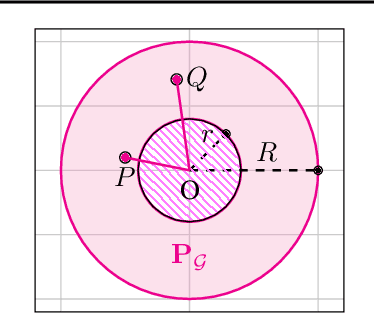
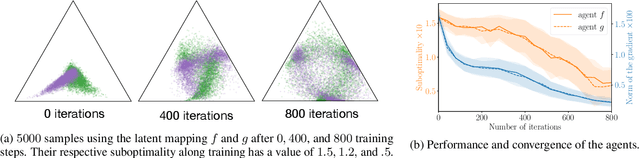
Adversarial training, a special case of multi-objective optimization, is an increasingly useful tool in machine learning. For example, two-player zero-sum games are important for generative modeling (GANs) and for mastering games like Go or Poker via self-play. A classic result in Game Theory states that one must mix strategies, as pure equilibria may not exist. Surprisingly, machine learning practitioners typically train a \emph{single} pair of agents -- instead of a pair of mixtures -- going against Nash's principle. Our main contribution is a notion of limited-capacity-equilibrium for which, as capacity grows, optimal agents -- not mixtures -- can learn increasingly expressive and realistic behaviors. We define \emph{latent games}, a new class of game where agents are mappings that transform latent distributions. Examples include generators in GANs, which transform Gaussian noise into distributions on images, and StarCraft II agents, which transform sampled build orders into policies. We show that minimax equilibria in latent games can be approximated by a \emph{single} pair of dense neural networks. Finally, we apply our latent game approach to solve differentiable Blotto, a game with an infinite strategy space.
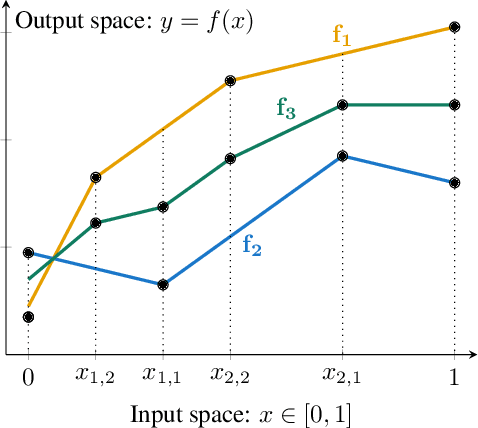
A Deep Neural Network's Loss Surface Contains Every Low-dimensional Pattern
Jan 02, 2020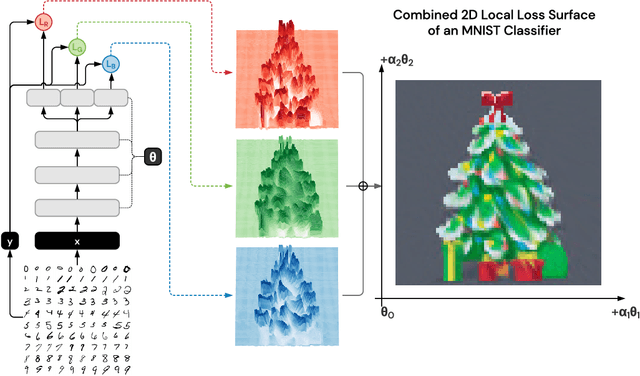
The work "Loss Landscape Sightseeing with Multi-Point Optimization" (Skorokhodov and Burtsev, 2019) demonstrated that one can empirically find arbitrary 2D binary patterns inside loss surfaces of popular neural networks. In this paper we prove that: (i) this is a general property of deep universal approximators; and (ii) this property holds for arbitrary smooth patterns, for other dimensionalities, for every dataset, and any neural network that is sufficiently deep and wide. Our analysis predicts not only the existence of all such low-dimensional patterns, but also two other properties that were observed empirically: (i) that it is easy to find these patterns; and (ii) that they transfer to other data-sets (e.g. a test-set).
Distilling Policy Distillation
Feb 06, 2019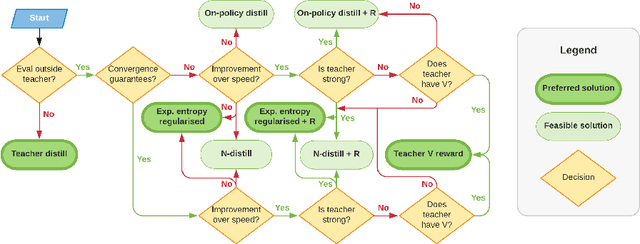



The transfer of knowledge from one policy to another is an important tool in Deep Reinforcement Learning. This process, referred to as distillation, has been used to great success, for example, by enhancing the optimisation of agents, leading to stronger performance faster, on harder domains [26, 32, 5, 8]. Despite the widespread use and conceptual simplicity of distillation, many different formulations are used in practice, and the subtle variations between them can often drastically change the performance and the resulting objective that is being optimised. In this work, we rigorously explore the entire landscape of policy distillation, comparing the motivations and strengths of each variant through theoretical and empirical analysis. Our results point to three distillation techniques, that are preferred depending on specifics of the task. Specifically a newly proposed expected entropy regularised distillation allows for quicker learning in a wide range of situations, while still guaranteeing convergence.