 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA perspective on fluid mechanical environments for challenges in reinforcement learning
May 24, 2026We consider the challenge of developing agents that efficiently interact with high-dimensional, evolving environments, towards a view of practical reinforcement learning (RL) agents interacting with open worlds, of which they witness and affect only a small part. We argue that canonical fluid mechanics problems, and their simulations, present a compelling testbed for the development of such methods. These problems arise in nonlinear instabilities, where small disturbances can grow to transform the dynamics of a system. Nonlinear instabilities represent several open scientific challenges with industrial applications -- the droplet breakup of a liquid jet, mixing at an interface between two fluids, and the appearance of unusually tall rogue waves in the ocean. In these settings, agents may leverage preserved representations across the changing dynamics to learn efficiently. We present two problem descriptions of agents interacting with a fluid mechanical environment, and describe the state and action spaces, and reward functions, for these agents. For these examples, we specify the aspects of the environment which are nonstationary and the preserved invariances. We note Dedalus and JAX-CFD as open-source simulators that can be used for the development of reinforcement learning methods (Burns et al., 2016; Kochkov et al., 2021)) We demonstrate the use of Dedalus for environment generation by creating RL agents that learn to navigate in a stationary environment that is simulated using Dedalus. This sets the stage for future development of RL agents that learn to meaningfully interact with simulated environments that represent scientific challenges in natural and industrial flows.
Policy composition in reinforcement learning via multi-objective policy optimization
Aug 30, 2023



We enable reinforcement learning agents to learn successful behavior policies by utilizing relevant pre-existing teacher policies. The teacher policies are introduced as objectives, in addition to the task objective, in a multi-objective policy optimization setting. Using the Multi-Objective Maximum a Posteriori Policy Optimization algorithm (Abdolmaleki et al. 2020), we show that teacher policies can help speed up learning, particularly in the absence of shaping rewards. In two domains with continuous observation and action spaces, our agents successfully compose teacher policies in sequence and in parallel, and are also able to further extend the policies of the teachers in order to solve the task. Depending on the specified combination of task and teacher(s), teacher(s) may naturally act to limit the final performance of an agent. The extent to which agents are required to adhere to teacher policies are determined by hyperparameters which determine both the effect of teachers on learning speed and the eventual performance of the agent on the task. In the humanoid domain (Tassa et al. 2018), we also equip agents with the ability to control the selection of teachers. With this ability, agents are able to meaningfully compose from the teacher policies to achieve a superior task reward on the walk task than in cases without access to the teacher policies. We show the resemblance of composed task policies with the corresponding teacher policies through videos.
On Multi-objective Policy Optimization as a Tool for Reinforcement Learning
Jun 15, 2021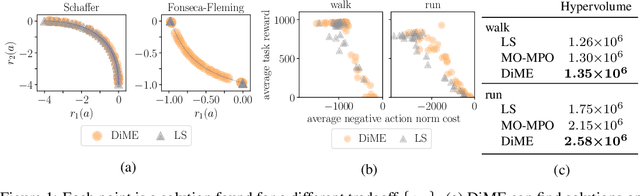
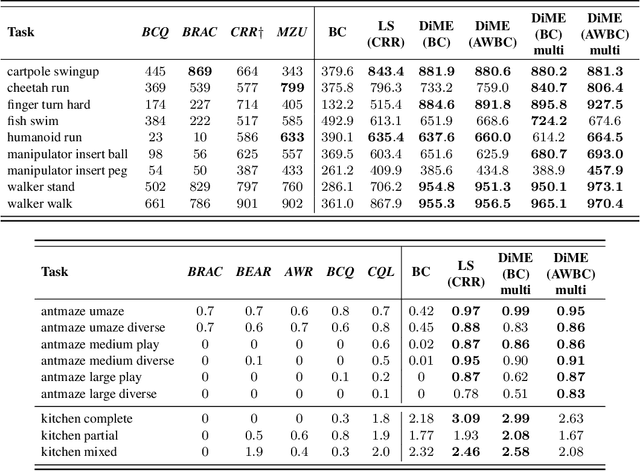
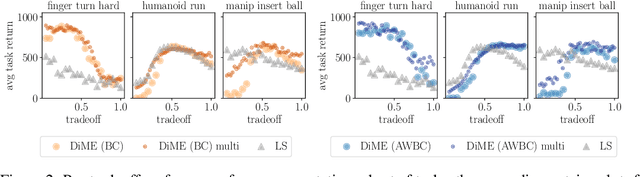

Many advances that have improved the robustness and efficiency of deep reinforcement learning (RL) algorithms can, in one way or another, be understood as introducing additional objectives, or constraints, in the policy optimization step. This includes ideas as far ranging as exploration bonuses, entropy regularization, and regularization toward teachers or data priors when learning from experts or in offline RL. Often, task reward and auxiliary objectives are in conflict with each other and it is therefore natural to treat these examples as instances of multi-objective (MO) optimization problems. We study the principles underlying MORL and introduce a new algorithm, Distillation of a Mixture of Experts (DiME), that is intuitive and scale-invariant under some conditions. We highlight its strengths on standard MO benchmark problems and consider case studies in which we recast offline RL and learning from experts as MO problems. This leads to a natural algorithmic formulation that sheds light on the connection between existing approaches. For offline RL, we use the MO perspective to derive a simple algorithm, that optimizes for the standard RL objective plus a behavioral cloning term. This outperforms state-of-the-art on two established offline RL benchmarks.
Augmenting learning using symmetry in a biologically-inspired domain
Oct 01, 2019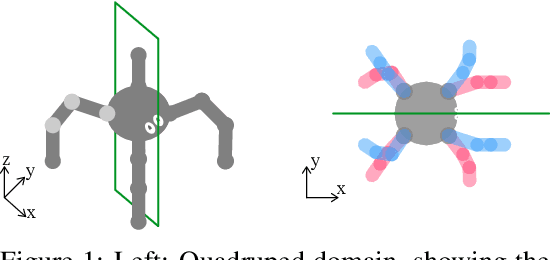
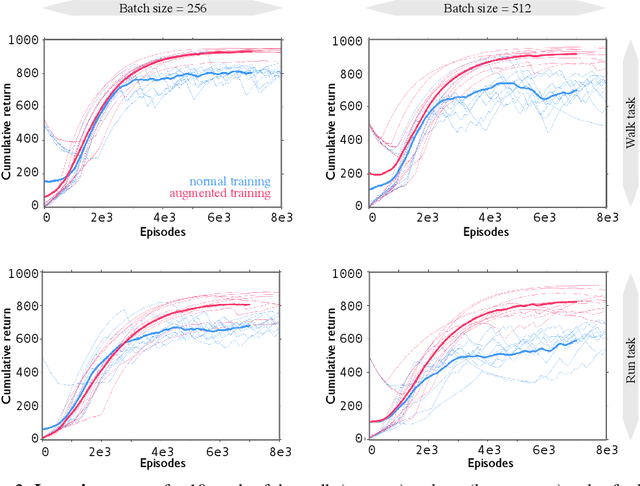
Invariances to translation, rotation and other spatial transformations are a hallmark of the laws of motion, and have widespread use in the natural sciences to reduce the dimensionality of systems of equations. In supervised learning, such as in image classification tasks, rotation, translation and scale invariances are used to augment training datasets. In this work, we use data augmentation in a similar way, exploiting symmetry in the quadruped domain of the DeepMind control suite (Tassa et al. 2018) to add to the trajectories experienced by the actor in the actor-critic algorithm of Abdolmaleki et al. (2018). In a data-limited regime, the agent using a set of experiences augmented through symmetry is able to learn faster. Our approach can be used to inject knowledge of invariances in the domain and task to augment learning in robots, and more generally, to speed up learning in realistic robotics applications.