 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Motor Control to Team Play in Simulated Humanoid Football
May 25, 2021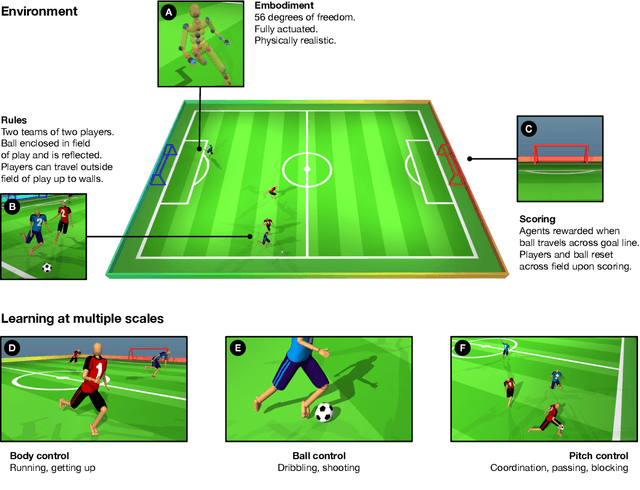

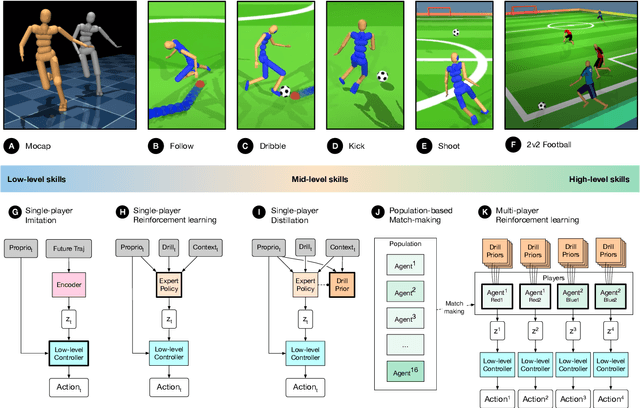

Intelligent behaviour in the physical world exhibits structure at multiple spatial and temporal scales. Although movements are ultimately executed at the level of instantaneous muscle tensions or joint torques, they must be selected to serve goals defined on much longer timescales, and in terms of relations that extend far beyond the body itself, ultimately involving coordination with other agents. Recent research in artificial intelligence has shown the promise of learning-based approaches to the respective problems of complex movement, longer-term planning and multi-agent coordination. However, there is limited research aimed at their integration. We study this problem by training teams of physically simulated humanoid avatars to play football in a realistic virtual environment. We develop a method that combines imitation learning, single- and multi-agent reinforcement learning and population-based training, and makes use of transferable representations of behaviour for decision making at different levels of abstraction. In a sequence of stages, players first learn to control a fully articulated body to perform realistic, human-like movements such as running and turning; they then acquire mid-level football skills such as dribbling and shooting; finally, they develop awareness of others and play as a team, bridging the gap between low-level motor control at a timescale of milliseconds, and coordinated goal-directed behaviour as a team at the timescale of tens of seconds. We investigate the emergence of behaviours at different levels of abstraction, as well as the representations that underlie these behaviours using several analysis techniques, including statistics from real-world sports analytics. Our work constitutes a complete demonstration of integrated decision-making at multiple scales in a physically embodied multi-agent setting. See project video at https://youtu.be/KHMwq9pv7mg.
Negotiating Team Formation Using Deep Reinforcement Learning
Oct 20, 2020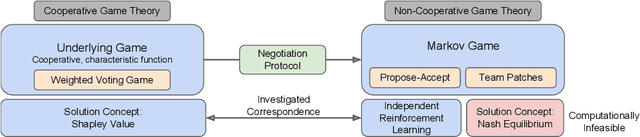
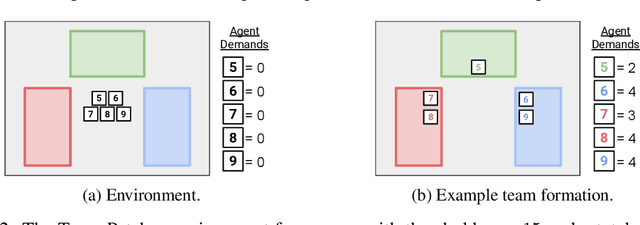
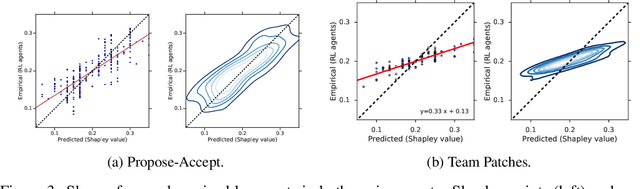
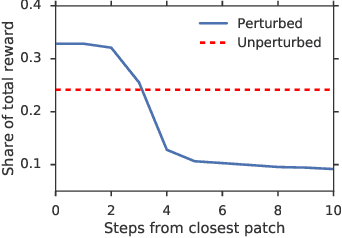
When autonomous agents interact in the same environment, they must often cooperate to achieve their goals. One way for agents to cooperate effectively is to form a team, make a binding agreement on a joint plan, and execute it. However, when agents are self-interested, the gains from team formation must be allocated appropriately to incentivize agreement. Various approaches for multi-agent negotiation have been proposed, but typically only work for particular negotiation protocols. More general methods usually require human input or domain-specific data, and so do not scale. To address this, we propose a framework for training agents to negotiate and form teams using deep reinforcement learning. Importantly, our method makes no assumptions about the specific negotiation protocol, and is instead completely experience driven. We evaluate our approach on both non-spatial and spatially extended team-formation negotiation environments, demonstrating that our agents beat hand-crafted bots and reach negotiation outcomes consistent with fair solutions predicted by cooperative game theory. Additionally, we investigate how the physical location of agents influences negotiation outcomes.
Discovering Reinforcement Learning Algorithms
Jul 17, 2020
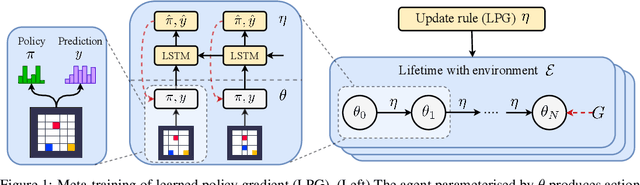
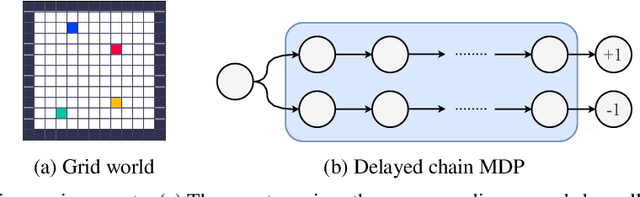
Reinforcement learning (RL) algorithms update an agent's parameters according to one of several possible rules, discovered manually through years of research. Automating the discovery of update rules from data could lead to more efficient algorithms, or algorithms that are better adapted to specific environments. Although there have been prior attempts at addressing this significant scientific challenge, it remains an open question whether it is feasible to discover alternatives to fundamental concepts of RL such as value functions and temporal-difference learning. This paper introduces a new meta-learning approach that discovers an entire update rule which includes both 'what to predict' (e.g. value functions) and 'how to learn from it' (e.g. bootstrapping) by interacting with a set of environments. The output of this method is an RL algorithm that we call Learned Policy Gradient (LPG). Empirical results show that our method discovers its own alternative to the concept of value functions. Furthermore it discovers a bootstrapping mechanism to maintain and use its predictions. Surprisingly, when trained solely on toy environments, LPG generalises effectively to complex Atari games and achieves non-trivial performance. This shows the potential to discover general RL algorithms from data.
Perception-Prediction-Reaction Agents for Deep Reinforcement Learning
Jun 26, 2020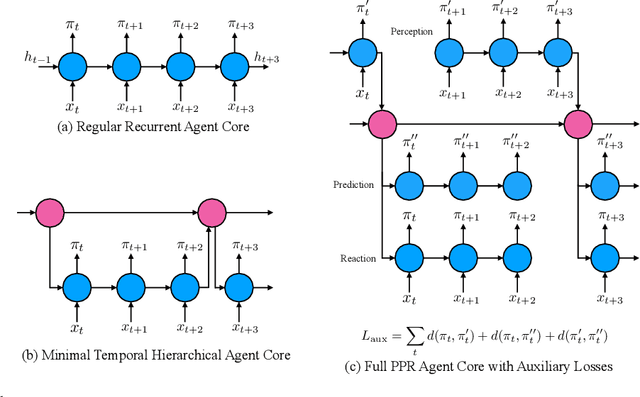

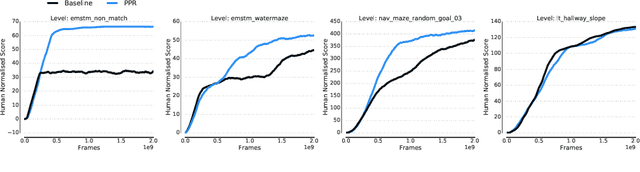
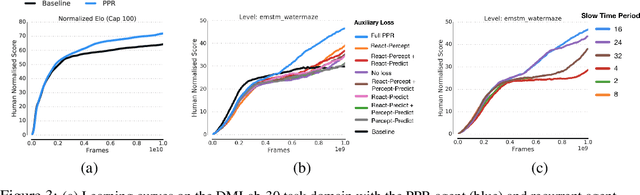
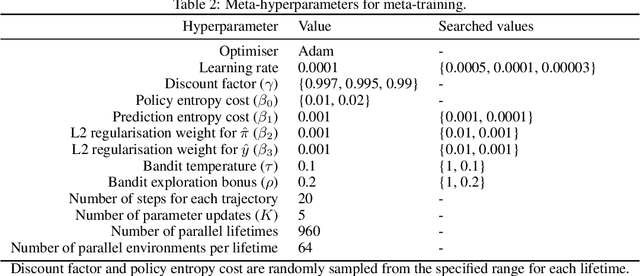
We introduce a new recurrent agent architecture and associated auxiliary losses which improve reinforcement learning in partially observable tasks requiring long-term memory. We employ a temporal hierarchy, using a slow-ticking recurrent core to allow information to flow more easily over long time spans, and three fast-ticking recurrent cores with connections designed to create an information asymmetry. The \emph{reaction} core incorporates new observations with input from the slow core to produce the agent's policy; the \emph{perception} core accesses only short-term observations and informs the slow core; lastly, the \emph{prediction} core accesses only long-term memory. An auxiliary loss regularizes policies drawn from all three cores against each other, enacting the prior that the policy should be expressible from either recent or long-term memory. We present the resulting \emph{Perception-Prediction-Reaction} (PPR) agent and demonstrate its improved performance over a strong LSTM-agent baseline in DMLab-30, particularly in tasks requiring long-term memory. We further show significant improvements in Capture the Flag, an environment requiring agents to acquire a complicated mixture of skills over long time scales. In a series of ablation experiments, we probe the importance of each component of the PPR agent, establishing that the entire, novel combination is necessary for this intriguing result.
Navigating the Landscape of Games
May 04, 2020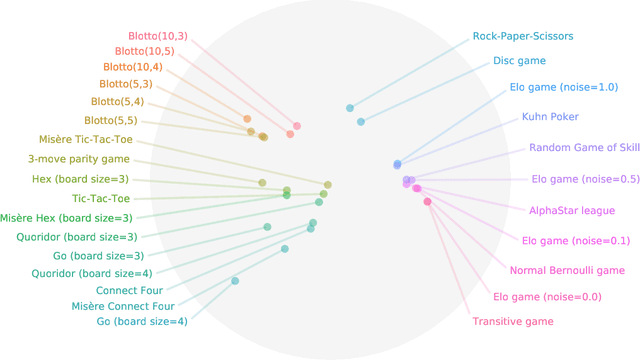
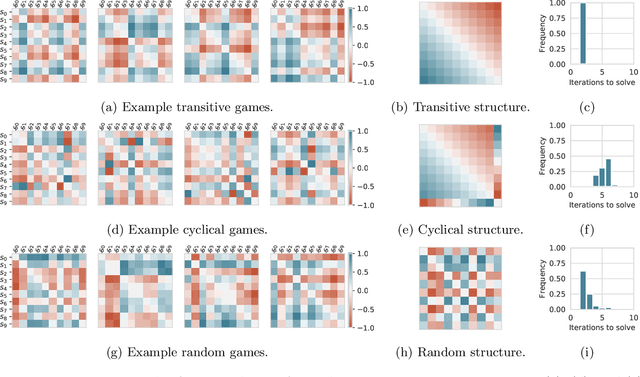
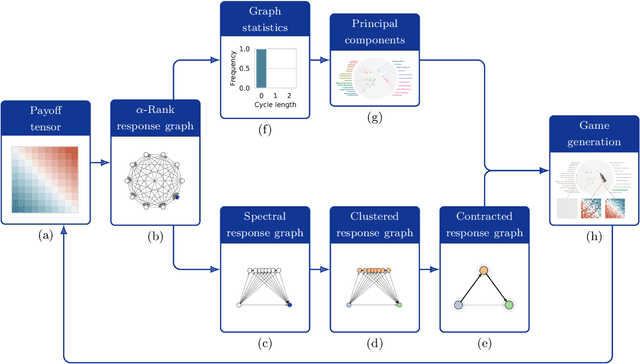

Games are traditionally recognized as one of the key testbeds underlying progress in artificial intelligence (AI), aptly referred to as the "Drosophila of AI". Traditionally, researchers have focused on using games to build strong AI agents that, e.g., achieve human-level performance. This progress, however, also requires a classification of how 'interesting' a game is for an artificial agent. Tackling this latter question not only facilitates an understanding of the characteristics of learnt AI agents in games, but also helps to determine what game an AI should address next as part of its training. Here, we show how network measures applied to so-called response graphs of large-scale games enable the creation of a useful landscape of games, quantifying the relationships between games of widely varying sizes, characteristics, and complexities. We illustrate our findings in various domains, ranging from well-studied canonical games to significantly more complex empirical games capturing the performance of trained AI agents pitted against one another. Our results culminate in a demonstration of how one can leverage this information to automatically generate new and interesting games, including mixtures of empirical games synthesized from real world games.
Information asymmetry in KL-regularized RL
May 03, 2019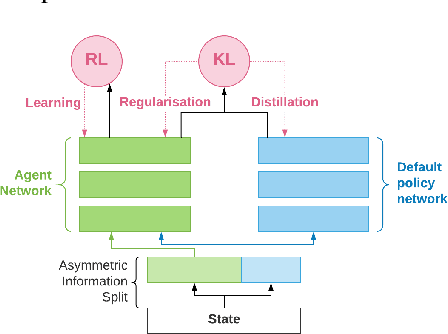

Many real world tasks exhibit rich structure that is repeated across different parts of the state space or in time. In this work we study the possibility of leveraging such repeated structure to speed up and regularize learning. We start from the KL regularized expected reward objective which introduces an additional component, a default policy. Instead of relying on a fixed default policy, we learn it from data. But crucially, we restrict the amount of information the default policy receives, forcing it to learn reusable behaviors that help the policy learn faster. We formalize this strategy and discuss connections to information bottleneck approaches and to the variational EM algorithm. We present empirical results in both discrete and continuous action domains and demonstrate that, for certain tasks, learning a default policy alongside the policy can significantly speed up and improve learning.
Open-ended Learning in Symmetric Zero-sum Games
Jan 23, 2019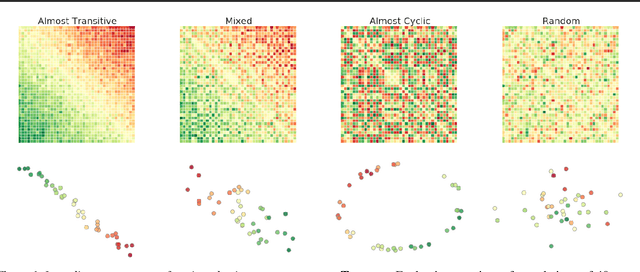
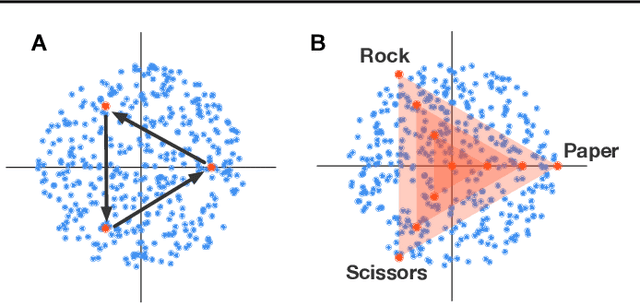
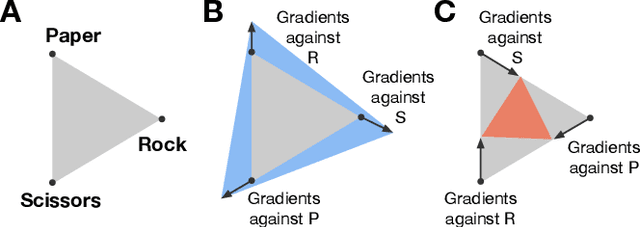
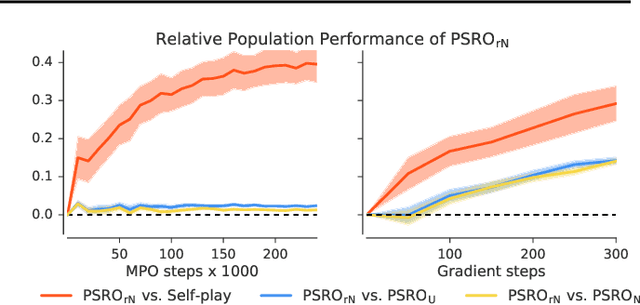
Zero-sum games such as chess and poker are, abstractly, functions that evaluate pairs of agents, for example labeling them `winner' and `loser'. If the game is approximately transitive, then self-play generates sequences of agents of increasing strength. However, nontransitive games, such as rock-paper-scissors, can exhibit strategic cycles, and there is no longer a clear objective -- we want agents to increase in strength, but against whom is unclear. In this paper, we introduce a geometric framework for formulating agent objectives in zero-sum games, in order to construct adaptive sequences of objectives that yield open-ended learning. The framework allows us to reason about population performance in nontransitive games, and enables the development of a new algorithm (rectified Nash response, PSRO_rN) that uses game-theoretic niching to construct diverse populations of effective agents, producing a stronger set of agents than existing algorithms. We apply PSRO_rN to two highly nontransitive resource allocation games and find that PSRO_rN consistently outperforms the existing alternatives.
Adapting Auxiliary Losses Using Gradient Similarity
Dec 05, 2018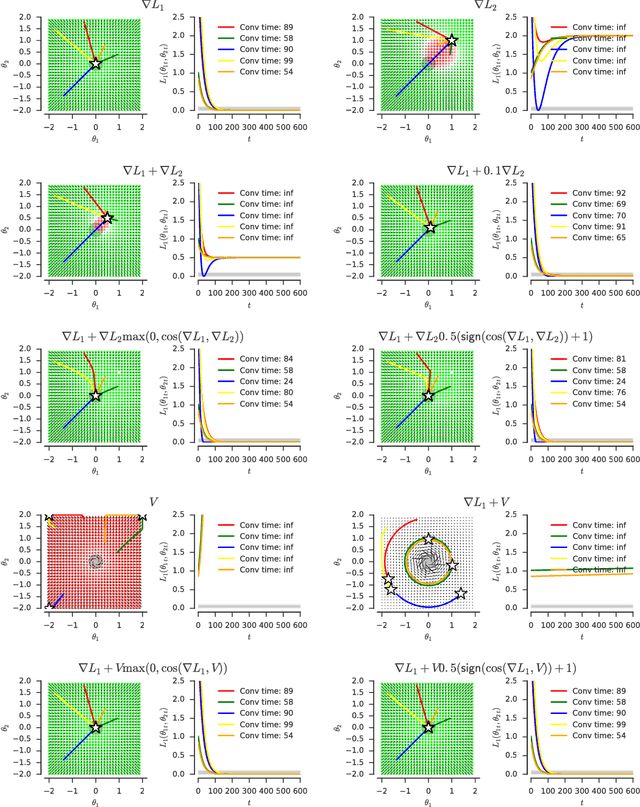
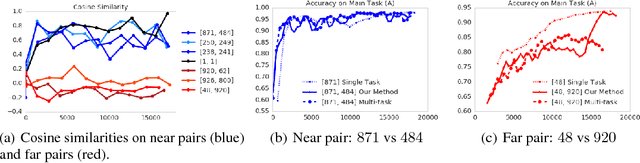
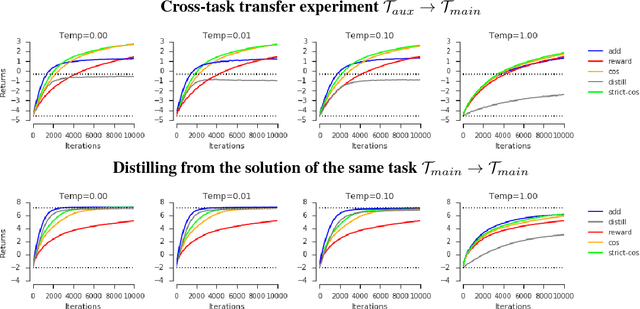
One approach to deal with the statistical inefficiency of neural networks is to rely on auxiliary losses that help to build useful representations. However, it is not always trivial to know if an auxiliary task will be helpful for the main task and when it could start hurting. We propose to use the cosine similarity between gradients of tasks as an adaptive weight to detect when an auxiliary loss is helpful to the main loss. We show that our approach is guaranteed to converge to critical points of the main task and demonstrate the practical usefulness of the proposed algorithm in a few domains: multi-task supervised learning on subsets of ImageNet, reinforcement learning on gridworld, and reinforcement learning on Atari games.
Human-level performance in first-person multiplayer games with population-based deep reinforcement learning
Jul 03, 2018Recent progress in artificial intelligence through reinforcement learning (RL) has shown great success on increasingly complex single-agent environments and two-player turn-based games. However, the real-world contains multiple agents, each learning and acting independently to cooperate and compete with other agents, and environments reflecting this degree of complexity remain an open challenge. In this work, we demonstrate for the first time that an agent can achieve human-level in a popular 3D multiplayer first-person video game, Quake III Arena Capture the Flag, using only pixels and game points as input. These results were achieved by a novel two-tier optimisation process in which a population of independent RL agents are trained concurrently from thousands of parallel matches with agents playing in teams together and against each other on randomly generated environments. Each agent in the population learns its own internal reward signal to complement the sparse delayed reward from winning, and selects actions using a novel temporally hierarchical representation that enables the agent to reason at multiple timescales. During game-play, these agents display human-like behaviours such as navigating, following, and defending based on a rich learned representation that is shown to encode high-level game knowledge. In an extensive tournament-style evaluation the trained agents exceeded the win-rate of strong human players both as teammates and opponents, and proved far stronger than existing state-of-the-art agents. These results demonstrate a significant jump in the capabilities of artificial agents, bringing us closer to the goal of human-level intelligence.
Progress & Compress: A scalable framework for continual learning
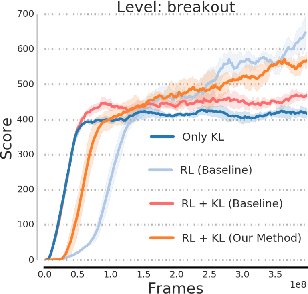
Jul 02, 2018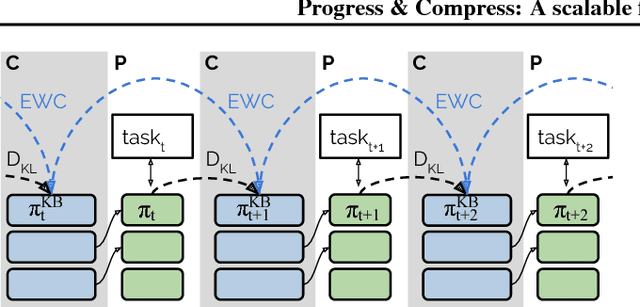
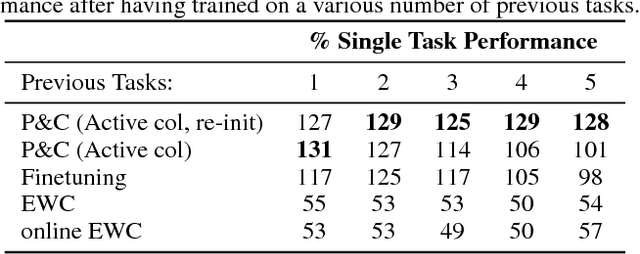
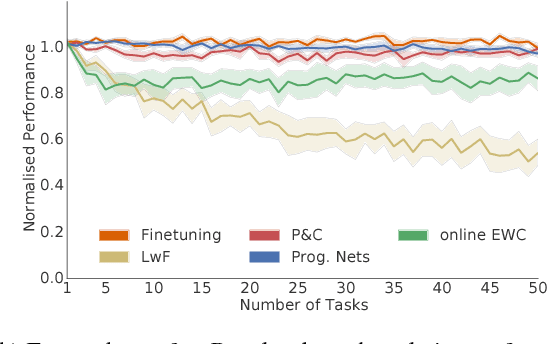
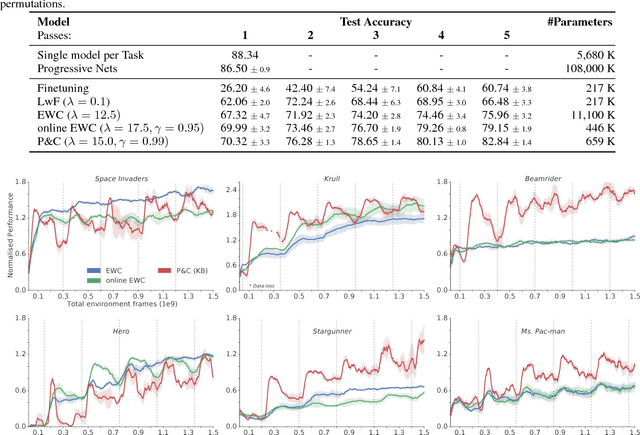
We introduce a conceptually simple and scalable framework for continual learning domains where tasks are learned sequentially. Our method is constant in the number of parameters and is designed to preserve performance on previously encountered tasks while accelerating learning progress on subsequent problems. This is achieved by training a network with two components: A knowledge base, capable of solving previously encountered problems, which is connected to an active column that is employed to efficiently learn the current task. After learning a new task, the active column is distilled into the knowledge base, taking care to protect any previously acquired skills. This cycle of active learning (progression) followed by consolidation (compression) requires no architecture growth, no access to or storing of previous data or tasks, and no task-specific parameters. We demonstrate the progress & compress approach on sequential classification of handwritten alphabets as well as two reinforcement learning domains: Atari games and 3D maze navigation.