 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving cosmological reach of a gravitational wave observatory using Deep Loop Shaping
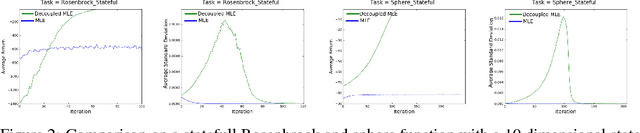
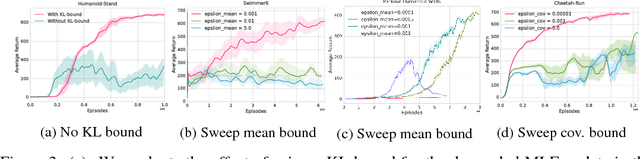
Sep 17, 2025Improved low-frequency sensitivity of gravitational wave observatories would unlock study of intermediate-mass black hole mergers, binary black hole eccentricity, and provide early warnings for multi-messenger observations of binary neutron star mergers. Today's mirror stabilization control injects harmful noise, constituting a major obstacle to sensitivity improvements. We eliminated this noise through Deep Loop Shaping, a reinforcement learning method using frequency domain rewards. We proved our methodology on the LIGO Livingston Observatory (LLO). Our controller reduced control noise in the 10--30Hz band by over 30x, and up to 100x in sub-bands surpassing the design goal motivated by the quantum limit. These results highlight the potential of Deep Loop Shaping to improve current and future GW observatories, and more broadly instrumentation and control systems.
Shaking the foundations: delusions in sequence models for interaction and control
Oct 20, 2021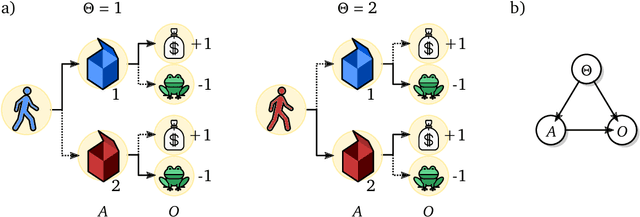
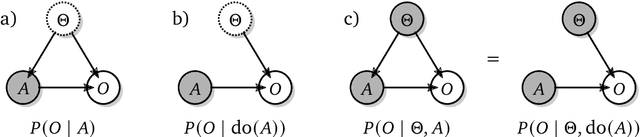
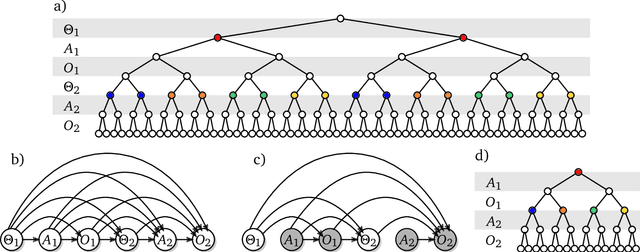
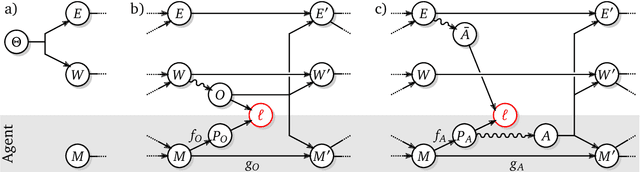
The recent phenomenal success of language models has reinvigorated machine learning research, and large sequence models such as transformers are being applied to a variety of domains. One important problem class that has remained relatively elusive however is purposeful adaptive behavior. Currently there is a common perception that sequence models "lack the understanding of the cause and effect of their actions" leading them to draw incorrect inferences due to auto-suggestive delusions. In this report we explain where this mismatch originates, and show that it can be resolved by treating actions as causal interventions. Finally, we show that in supervised learning, one can teach a system to condition or intervene on data by training with factual and counterfactual error signals respectively.
Local Search for Policy Iteration in Continuous Control
Oct 12, 2020
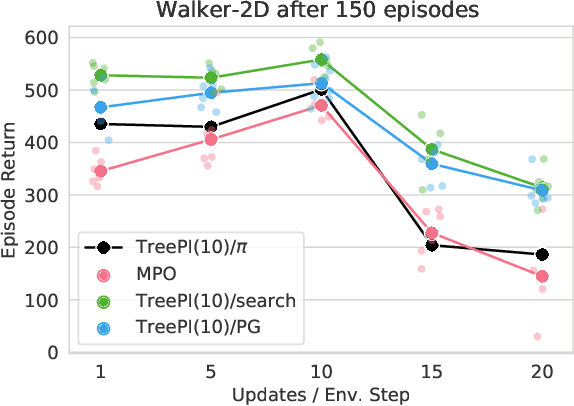

We present an algorithm for local, regularized, policy improvement in reinforcement learning (RL) that allows us to formulate model-based and model-free variants in a single framework. Our algorithm can be interpreted as a natural extension of work on KL-regularized RL and introduces a form of tree search for continuous action spaces. We demonstrate that additional computation spent on model-based policy improvement during learning can improve data efficiency, and confirm that model-based policy improvement during action selection can also be beneficial. Quantitatively, our algorithm improves data efficiency on several continuous control benchmarks (when a model is learned in parallel), and it provides significant improvements in wall-clock time in high-dimensional domains (when a ground truth model is available). The unified framework also helps us to better understand the space of model-based and model-free algorithms. In particular, we demonstrate that some benefits attributed to model-based RL can be obtained without a model, simply by utilizing more computation.
Quinoa: a Q-function You Infer Normalized Over Actions
Nov 05, 2019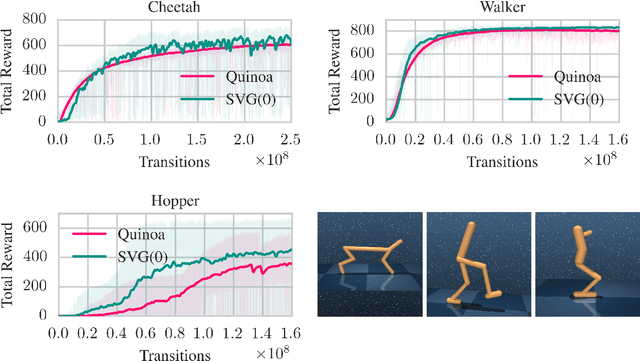
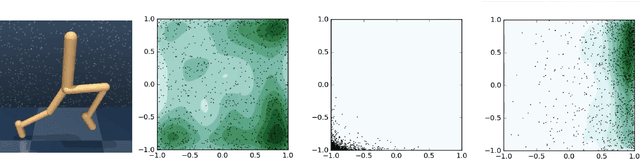
We present an algorithm for learning an approximate action-value soft Q-function in the relative entropy regularised reinforcement learning setting, for which an optimal improved policy can be recovered in closed form. We use recent advances in normalising flows for parametrising the policy together with a learned value-function; and show how this combination can be used to implicitly represent Q-values of an arbitrary policy in continuous action space. Using simple temporal difference learning on the Q-values then leads to a unified objective for policy and value learning. We show how this approach considerably simplifies standard Actor-Critic off-policy algorithms, removing the need for a policy optimisation step. We perform experiments on a range of established reinforcement learning benchmarks, demonstrating that our approach allows for complex, multimodal policy distributions in continuous action spaces, while keeping the process of sampling from the policy both fast and exact.
Self-supervised Learning of Image Embedding for Continuous Control
Jan 03, 2019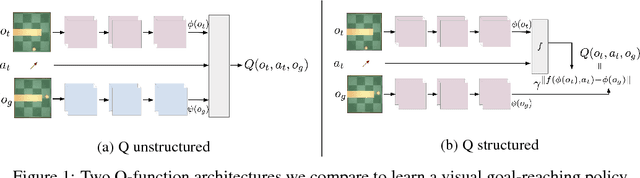
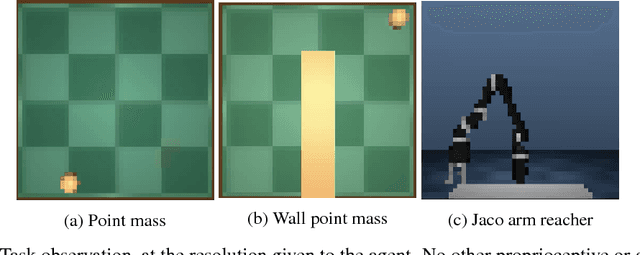
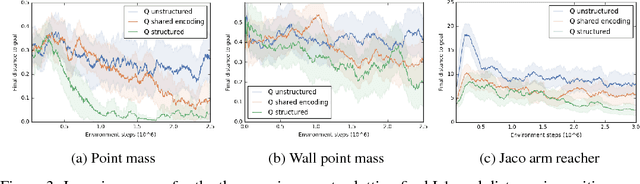
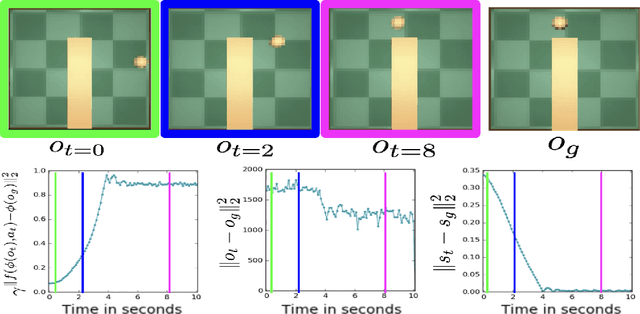
Operating directly from raw high dimensional sensory inputs like images is still a challenge for robotic control. Recently, Reinforcement Learning methods have been proposed to solve specific tasks end-to-end, from pixels to torques. However, these approaches assume the access to a specified reward which may require specialized instrumentation of the environment. Furthermore, the obtained policy and representations tend to be task specific and may not transfer well. In this work we investigate completely self-supervised learning of a general image embedding and control primitives, based on finding the shortest time to reach any state. We also introduce a new structure for the state-action value function that builds a connection between model-free and model-based methods, and improves the performance of the learning algorithm. We experimentally demonstrate these findings in three simulated robotic tasks.
Relative Entropy Regularized Policy Iteration
Dec 05, 2018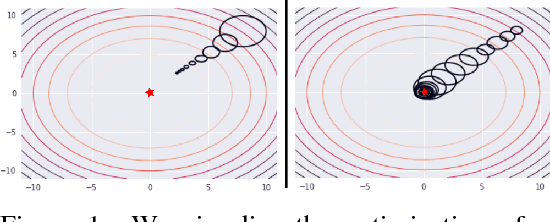

We present an off-policy actor-critic algorithm for Reinforcement Learning (RL) that combines ideas from gradient-free optimization via stochastic search with learned action-value function. The result is a simple procedure consisting of three steps: i) policy evaluation by estimating a parametric action-value function; ii) policy improvement via the estimation of a local non-parametric policy; and iii) generalization by fitting a parametric policy. Each step can be implemented in different ways, giving rise to several algorithm variants. Our algorithm draws on connections to existing literature on black-box optimization and 'RL as an inference' and it can be seen either as an extension of the Maximum a Posteriori Policy Optimisation algorithm (MPO) [Abdolmaleki et al., 2018a], or as an extension of Trust Region Covariance Matrix Adaptation Evolutionary Strategy (CMA-ES) [Abdolmaleki et al., 2017b; Hansen et al., 1997] to a policy iteration scheme. Our comparison on 31 continuous control tasks from parkour suite [Heess et al., 2017], DeepMind control suite [Tassa et al., 2018] and OpenAI Gym [Brockman et al., 2016] with diverse properties, limited amount of compute and a single set of hyperparameters, demonstrate the effectiveness of our method and the state of art results. Videos, summarizing results, can be found at goo.gl/HtvJKR .
A Differentiable Physics Engine for Deep Learning in Robotics
Nov 24, 2018
An important field in robotics is the optimization of controllers. Currently, robots are often treated as a black box in this optimization process, which is the reason why derivative-free optimization methods such as evolutionary algorithms or reinforcement learning are omnipresent. When gradient-based methods are used, models are kept small or rely on finite difference approximations for the Jacobian. This method quickly grows expensive with increasing numbers of parameters, such as found in deep learning. We propose the implementation of a modern physics engine, which can differentiate control parameters. This engine is implemented for both CPU and GPU. Firstly, this paper shows how such an engine speeds up the optimization process, even for small problems. Furthermore, it explains why this is an alternative approach to deep Q-learning, for using deep learning in robotics. Finally, we argue that this is a big step for deep learning in robotics, as it opens up new possibilities to optimize robots, both in hardware and software.
BRUNO: A Deep Recurrent Model for Exchangeable Data
Oct 16, 2018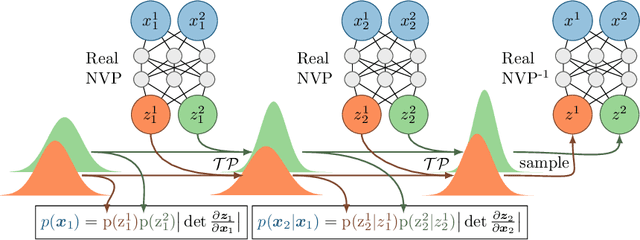
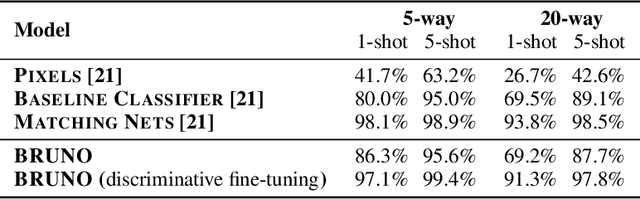

We present a novel model architecture which leverages deep learning tools to perform exact Bayesian inference on sets of high dimensional, complex observations. Our model is provably exchangeable, meaning that the joint distribution over observations is invariant under permutation: this property lies at the heart of Bayesian inference. The model does not require variational approximations to train, and new samples can be generated conditional on previous samples, with cost linear in the size of the conditioning set. The advantages of our architecture are demonstrated on learning tasks that require generalisation from short observed sequences while modelling sequence variability, such as conditional image generation, few-shot learning, and anomaly detection.
Oncilla robot: a versatile open-source quadruped research robot with compliant pantograph legs
Jun 16, 2018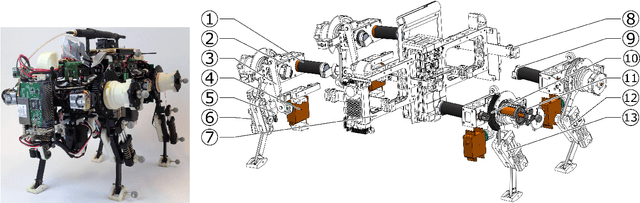
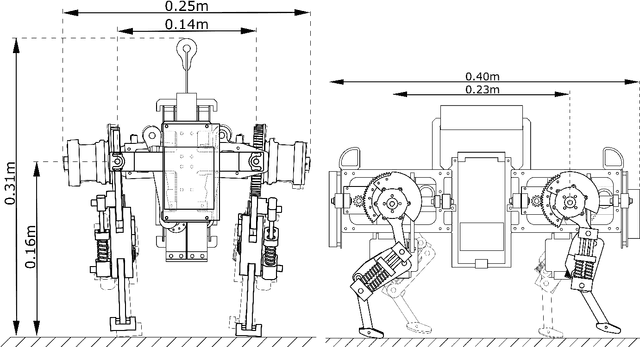

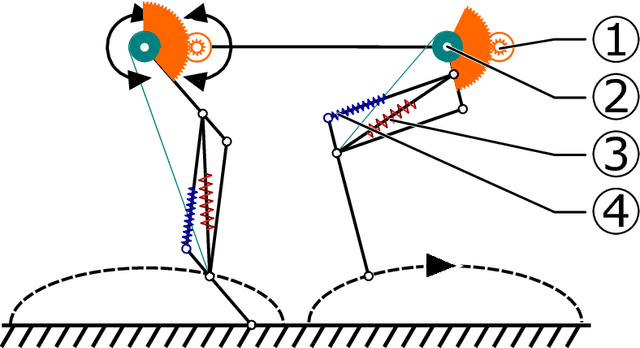
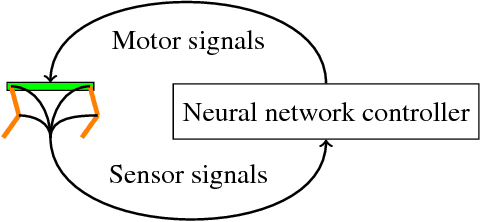
We present Oncilla robot, a novel mobile, quadruped legged locomotion machine. This large-cat sized, 5.1 robot is one of a kind of a recent, bioinspired legged robot class designed with the capability of model-free locomotion control. Animal legged locomotion in rough terrain is clearly shaped by sensor feedback systems. Results with Oncilla robot show that agile and versatile locomotion is possible without sensory signals to some extend, and tracking becomes robust when feedback control is added (Ajaoolleian 2015). By incorporating mechanical and control blueprints inspired from animals, and by observing the resulting robot locomotion characteristics, we aim to understand the contribution of individual components. Legged robots have a wide mechanical and control design parameter space, and a unique potential as research tools to investigate principles of biomechanics and legged locomotion control. But the hardware and controller design can be a steep initial hurdle for academic research. To facilitate the easy start and development of legged robots, Oncilla-robot's blueprints are available through open-source. [...]
Learning by Playing - Solving Sparse Reward Tasks from Scratch
Feb 28, 2018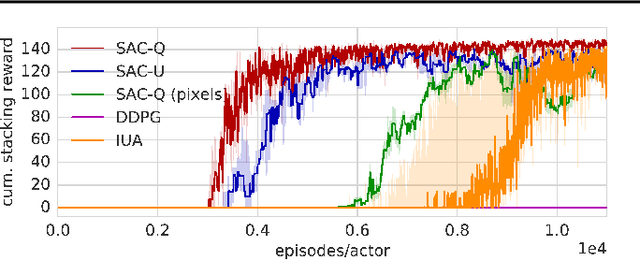
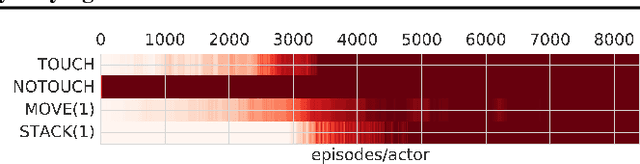
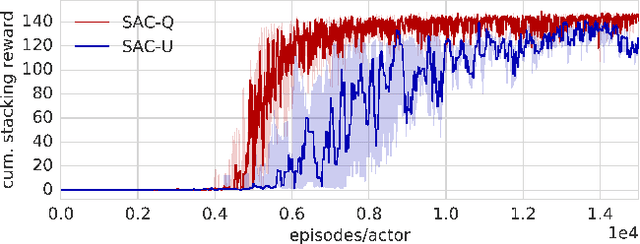
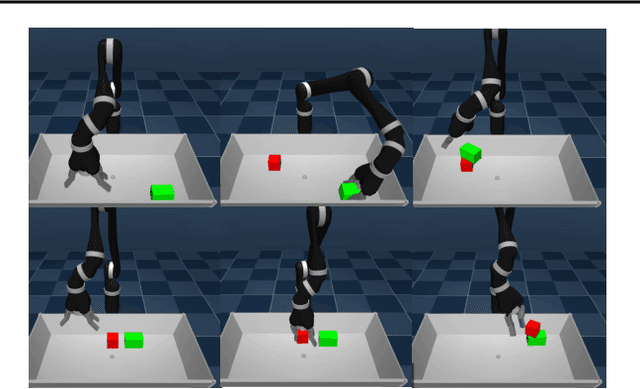
We propose Scheduled Auxiliary Control (SAC-X), a new learning paradigm in the context of Reinforcement Learning (RL). SAC-X enables learning of complex behaviors - from scratch - in the presence of multiple sparse reward signals. To this end, the agent is equipped with a set of general auxiliary tasks, that it attempts to learn simultaneously via off-policy RL. The key idea behind our method is that active (learned) scheduling and execution of auxiliary policies allows the agent to efficiently explore its environment - enabling it to excel at sparse reward RL. Our experiments in several challenging robotic manipulation settings demonstrate the power of our approach.