 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDi3PO -- Diptych Diffusion DPO for Targeted Improvements in Image
Feb 06, 2026Existing methods for preference tuning of text-to-image (T2I) diffusion models often rely on computationally expensive generation steps to create positive and negative pairs of images. These approaches frequently yield training pairs that either lack meaningful differences, are expensive to sample and filter, or exhibit significant variance in irrelevant pixel regions, thereby degrading training efficiency. To address these limitations, we introduce "Di3PO", a novel method for constructing positive and negative pairs that isolates specific regions targeted for improvement during preference tuning, while keeping the surrounding context in the image stable. We demonstrate the efficacy of our approach by applying it to the challenging task of text rendering in diffusion models, showcasing improvements over baseline methods of SFT and DPO.
Preserving Product Fidelity in Large Scale Image Recontextualization with Diffusion Models
Mar 11, 2025



We present a framework for high-fidelity product image recontextualization using text-to-image diffusion models and a novel data augmentation pipeline. This pipeline leverages image-to-video diffusion, in/outpainting & negatives to create synthetic training data, addressing limitations of real-world data collection for this task. Our method improves the quality and diversity of generated images by disentangling product representations and enhancing the model's understanding of product characteristics. Evaluation on the ABO dataset and a private product dataset, using automated metrics and human assessment, demonstrates the effectiveness of our framework in generating realistic and compelling product visualizations, with implications for applications such as e-commerce and virtual product showcasing.
Operational Wind Speed Forecasts for Chile's Electric Power Sector Using a Hybrid ML Model
Sep 17, 2024



As Chile's electric power sector advances toward a future powered by renewable energy, accurate forecasting of renewable generation is essential for managing grid operations. The integration of renewable energy sources is particularly challenging due to the operational difficulties of managing their power generation, which is highly variable compared to fossil fuel sources, delaying the availability of clean energy. To mitigate this, we quantify the impact of increasing intermittent generation from wind and solar on thermal power plants in Chile and introduce a hybrid wind speed forecasting methodology which combines two custom ML models for Chile. The first model is based on TiDE, an MLP-based ML model for short-term forecasts, and the second is based on a graph neural network, GraphCast, for medium-term forecasts up to 10 days. Our hybrid approach outperforms the most accurate operational deterministic systems by 4-21% for short-term forecasts and 5-23% for medium-term forecasts and can directly lower the impact of wind generation on thermal ramping, curtailment, and system-level emissions in Chile.
Imagen 3
Aug 13, 2024We introduce Imagen 3, a latent diffusion model that generates high quality images from text prompts. We describe our quality and responsibility evaluations. Imagen 3 is preferred over other state-of-the-art (SOTA) models at the time of evaluation. In addition, we discuss issues around safety and representation, as well as methods we used to minimize the potential harm of our models.
Controlling Commercial Cooling Systems Using Reinforcement Learning
Nov 11, 2022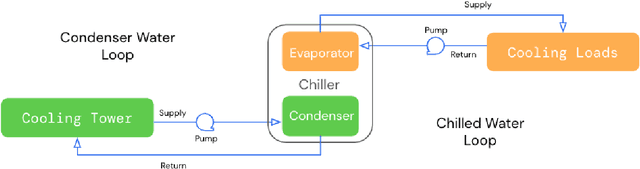

This paper is a technical overview of DeepMind and Google's recent work on reinforcement learning for controlling commercial cooling systems. Building on expertise that began with cooling Google's data centers more efficiently, we recently conducted live experiments on two real-world facilities in partnership with Trane Technologies, a building management system provider. These live experiments had a variety of challenges in areas such as evaluation, learning from offline data, and constraint satisfaction. Our paper describes these challenges in the hope that awareness of them will benefit future applied RL work. We also describe the way we adapted our RL system to deal with these challenges, resulting in energy savings of approximately 9% and 13% respectively at the two live experiment sites.
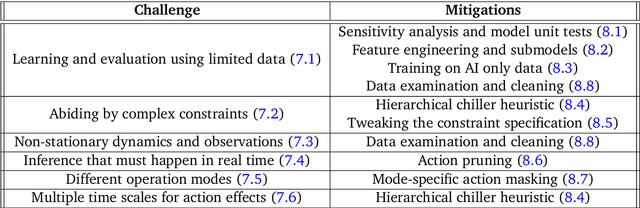
Optimizing Industrial HVAC Systems with Hierarchical Reinforcement Learning
Sep 16, 2022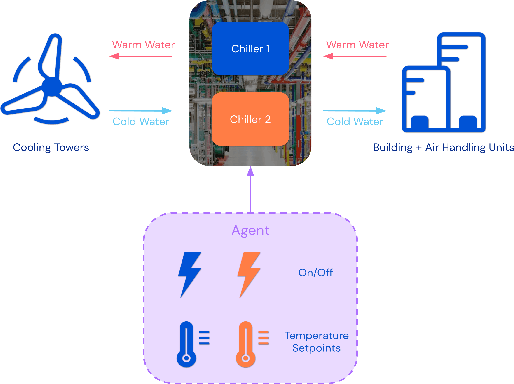
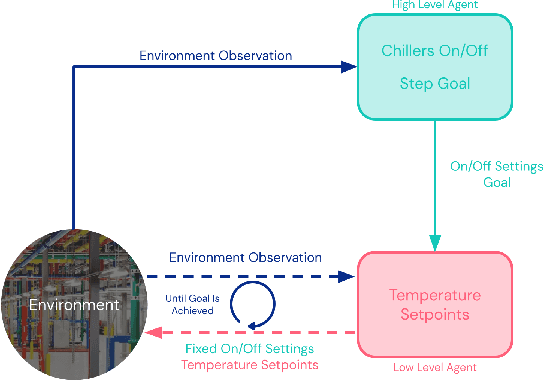
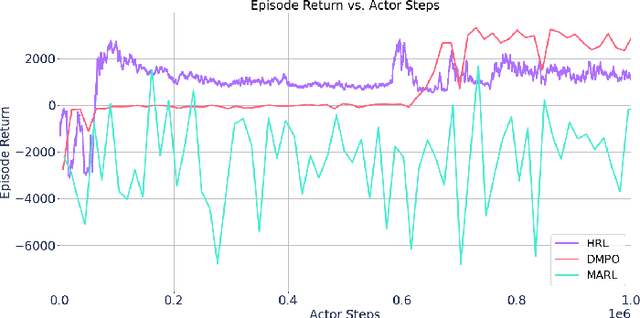
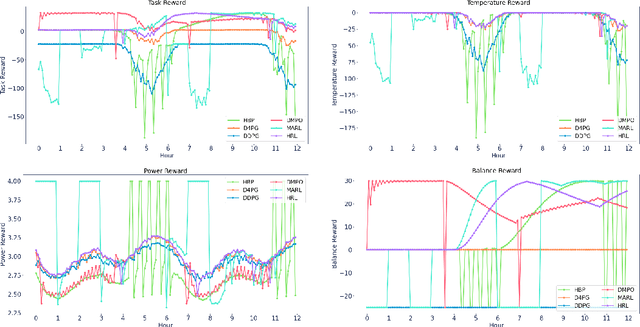
Reinforcement learning (RL) techniques have been developed to optimize industrial cooling systems, offering substantial energy savings compared to traditional heuristic policies. A major challenge in industrial control involves learning behaviors that are feasible in the real world due to machinery constraints. For example, certain actions can only be executed every few hours while other actions can be taken more frequently. Without extensive reward engineering and experimentation, an RL agent may not learn realistic operation of machinery. To address this, we use hierarchical reinforcement learning with multiple agents that control subsets of actions according to their operation time scales. Our hierarchical approach achieves energy savings over existing baselines while maintaining constraints such as operating chillers within safe bounds in a simulated HVAC control environment.
Semi-analytical Industrial Cooling System Model for Reinforcement Learning
Jul 26, 2022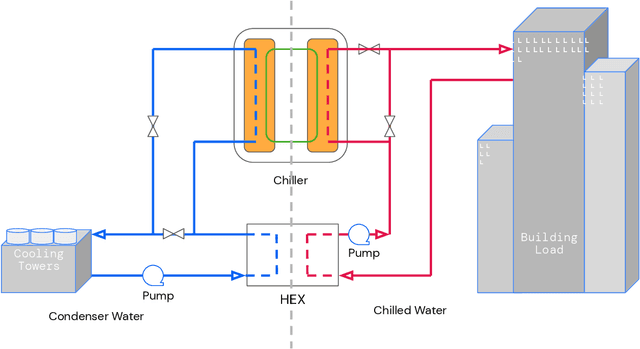
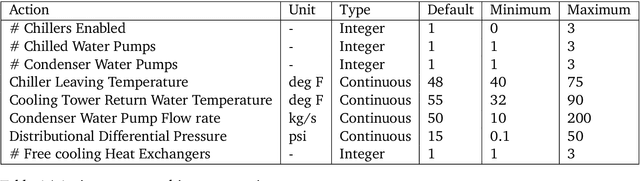
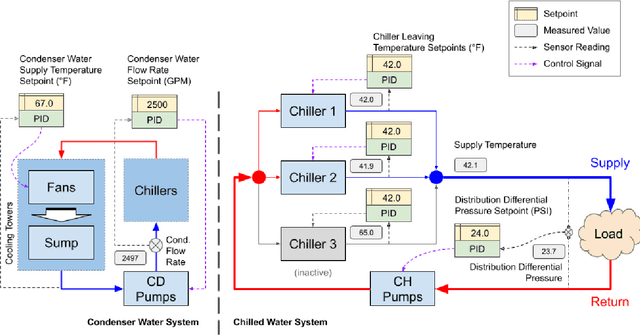
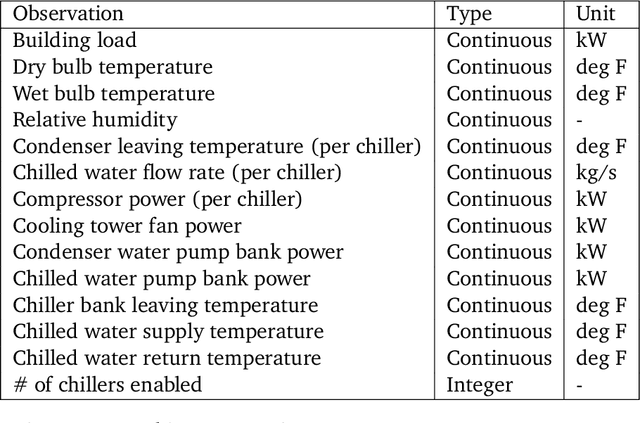
We present a hybrid industrial cooling system model that embeds analytical solutions within a multi-physics simulation. This model is designed for reinforcement learning (RL) applications and balances simplicity with simulation fidelity and interpretability. The model's fidelity is evaluated against real world data from a large scale cooling system. This is followed by a case study illustrating how the model can be used for RL research. For this, we develop an industrial task suite that allows specifying different problem settings and levels of complexity, and use it to evaluate the performance of different RL algorithms.
Biologically Inspired Oscillating Activation Functions Can Bridge the Performance Gap between Biological and Artificial Neurons
Nov 07, 2021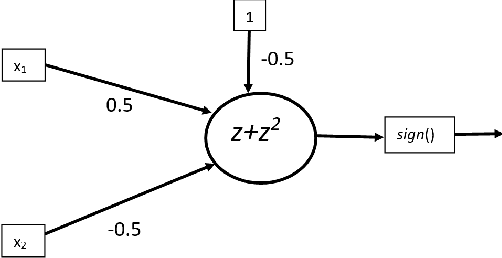
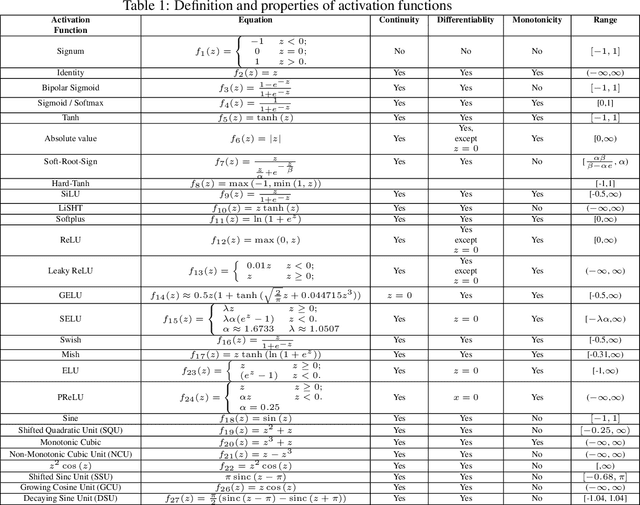
Nonlinear activation functions endow neural networks with the ability to learn complex high-dimensional functions. The choice of activation function is a crucial hyperparameter that determines the performance of deep neural networks. It significantly affects the gradient flow, speed of training and ultimately the representation power of the neural network. Saturating activation functions like sigmoids suffer from the vanishing gradient problem and cannot be used in deep neural networks. Universal approximation theorems guarantee that multilayer networks of sigmoids and ReLU can learn arbitrarily complex continuous functions to any accuracy. Despite the ability of multilayer neural networks to learn arbitrarily complex activation functions, each neuron in a conventional neural network (networks using sigmoids and ReLU like activations) has a single hyperplane as its decision boundary and hence makes a linear classification. Thus single neurons with sigmoidal, ReLU, Swish, and Mish activation functions cannot learn the XOR function. Recent research has discovered biological neurons in layers two and three of the human cortex having oscillating activation functions and capable of individually learning the XOR function. The presence of oscillating activation functions in biological neural neurons might partially explain the performance gap between biological and artificial neural networks. This paper proposes 4 new oscillating activation functions which enable individual neurons to learn the XOR function without manual feature engineering. The paper explores the possibility of using oscillating activation functions to solve classification problems with fewer neurons and reduce training time.
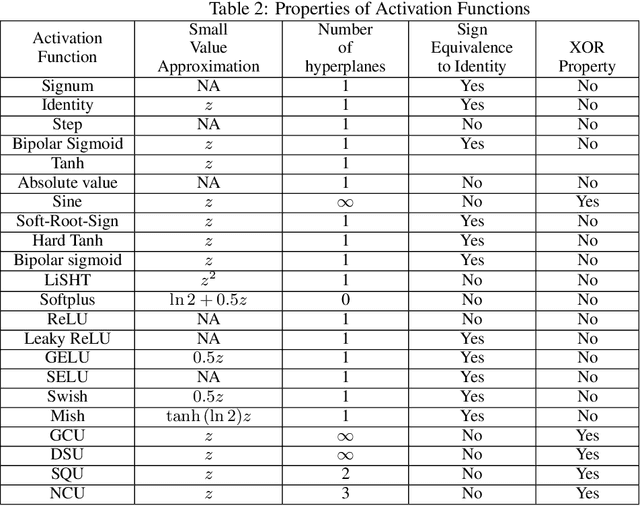
Growing Cosine Unit: A Novel Oscillatory Activation Function That Can Speedup Training and Reduce Parameters in Convolutional Neural Networks
Sep 04, 2021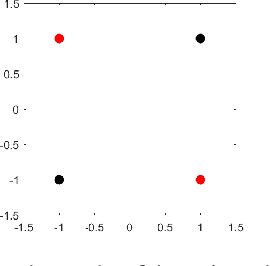

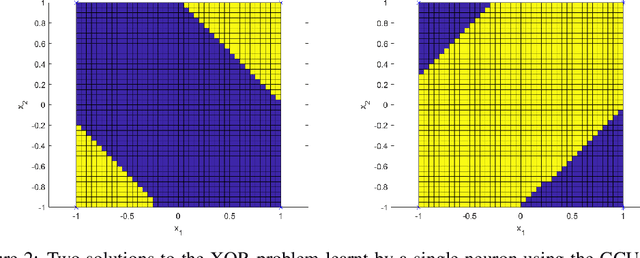
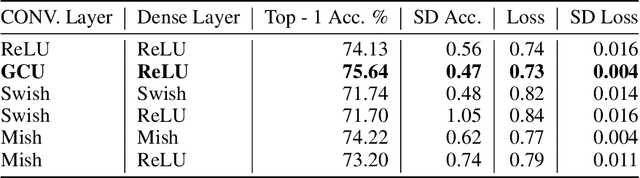
Convolution neural networks have been successful in solving many socially important and economically significant problems. Their ability to learn complex high-dimensional functions hierarchically can be attributed to the use of nonlinear activation functions. A key discovery that made training deep networks feasible was the adoption of the Rectified Linear Unit (ReLU) activation function to alleviate the vanishing gradient problem caused by using saturating activation functions. Since then many improved variants of the ReLU activation have been proposed. However a majority of activation functions used today are non-oscillatory and monotonically increasing due to their biological plausibility. This paper demonstrates that oscillatory activation functions can improve gradient flow and reduce network size. It is shown that oscillatory activation functions allow neurons to switch classification (sign of output) within the interior of neuronal hyperplane positive and negative half-spaces allowing complex decisions with fewer neurons. A new oscillatory activation function C(z) = z cos z that outperforms Sigmoids, Swish, Mish and ReLU on a variety of architectures and benchmarks is presented. This new activation function allows even single neurons to exhibit nonlinear decision boundaries. This paper presents a single neuron solution to the famous XOR problem. Experimental results indicate that replacing the activation function in the convolutional layers with C(z) significantly improves performance on CIFAR-10, CIFAR-100 and Imagenette.
Game Plan: What AI can do for Football, and What Football can do for AI
Nov 18, 2020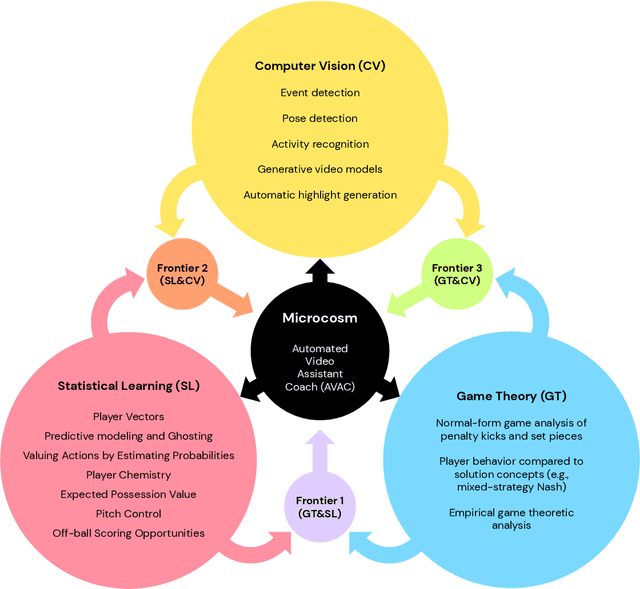



The rapid progress in artificial intelligence (AI) and machine learning has opened unprecedented analytics possibilities in various team and individual sports, including baseball, basketball, and tennis. More recently, AI techniques have been applied to football, due to a huge increase in data collection by professional teams, increased computational power, and advances in machine learning, with the goal of better addressing new scientific challenges involved in the analysis of both individual players' and coordinated teams' behaviors. The research challenges associated with predictive and prescriptive football analytics require new developments and progress at the intersection of statistical learning, game theory, and computer vision. In this paper, we provide an overarching perspective highlighting how the combination of these fields, in particular, forms a unique microcosm for AI research, while offering mutual benefits for professional teams, spectators, and broadcasters in the years to come. We illustrate that this duality makes football analytics a game changer of tremendous value, in terms of not only changing the game of football itself, but also in terms of what this domain can mean for the field of AI. We review the state-of-the-art and exemplify the types of analysis enabled by combining the aforementioned fields, including illustrative examples of counterfactual analysis using predictive models, and the combination of game-theoretic analysis of penalty kicks with statistical learning of player attributes. We conclude by highlighting envisioned downstream impacts, including possibilities for extensions to other sports (real and virtual).