 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Dexterous Manipulation from Suboptimal Experts
Paper and Code
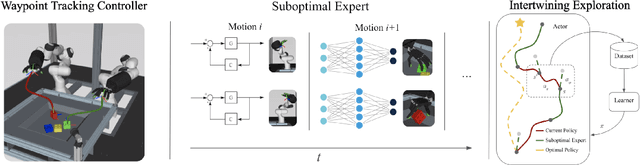
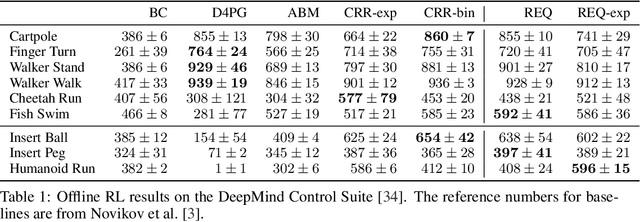

Learning dexterous manipulation in high-dimensional state-action spaces is an important open challenge with exploration presenting a major bottleneck. Although in many cases the learning process could be guided by demonstrations or other suboptimal experts, current RL algorithms for continuous action spaces often fail to effectively utilize combinations of highly off-policy expert data and on-policy exploration data. As a solution, we introduce Relative Entropy Q-Learning (REQ), a simple policy iteration algorithm that combines ideas from successful offline and conventional RL algorithms. It represents the optimal policy via importance sampling from a learned prior and is well-suited to take advantage of mixed data distributions. We demonstrate experimentally that REQ outperforms several strong baselines on robotic manipulation tasks for which suboptimal experts are available. We show how suboptimal experts can be constructed effectively by composing simple waypoint tracking controllers, and we also show how learned primitives can be combined with waypoint controllers to obtain reference behaviors to bootstrap a complex manipulation task on a simulated bimanual robot with human-like hands. Finally, we show that REQ is also effective for general off-policy RL, offline RL, and RL from demonstrations. Videos and further materials are available at sites.google.com/view/rlfse.