 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoubly Robust Proxy Causal Learning with Neural Mean Embeddings
May 10, 2026Unobserved confounding prevents standard covariate adjustment from identifying causal response functions in observational studies. Proxy causal learning addresses this problem through bridge equations involving treatment- and outcome-inducing proxies, avoiding direct recovery of the latent confounder. Existing doubly robust proxy estimators combine outcome and treatment bridges, but typically rely on fixed kernels, sieves, or low-dimensional semiparametric models; existing neural proxy methods are more flexible, but are largely single-bridge estimators. We develop a neural doubly robust framework for proxy causal learning with continuous and structured treatments. Our method introduces a neural mean-embedding estimator for the treatment bridge, combines it with a neural outcome bridge, and estimates the doubly robust correction through a final regression stage. The framework covers population, heterogeneous, and conditional dose-response functions, yielding full response-curve estimators rather than binary-treatment effects. The algorithms use two stages for each bridge and history-aware updates of the final linear layers to stabilize stochastic multi-stage training. We prove consistency of the algorithms showing that the doubly robust error is controlled by the final averaging and regression errors together with the smaller of the outcome- and treatment-side weak-norm bridge errors. Across synthetic and image-valued benchmarks, the proposed estimators outperform existing baselines and single-bridge neural estimators, showing the benefit of combining learned outcome and treatment bridges in a doubly robust construction. Our implementation is available at https://github.com/BariscanBozkurt/DRPCL-Neural-Mean-Embedding.
On the Wasserstein Gradient Flow Interpretation of Drifting Models
May 06, 2026Recently, Deng et al. (2026) proposed Generative Modeling via Drifting (GMD), a novel framework for generative tasks. This note presents an analysis of GMD through the lens of Wasserstein Gradient Flows (WGF), i.e., the path of steepest descent for a functional in the space of probability measures, equipped with the geometry of optimal transport. Unlike previous WGF-based contributions, GMD can be thought of as directly targeting a fixed point of a specific WGF flow. We demonstrate three main results: first, that one algorithm proposed by Deng et al. (2026) corresponds to finding the limiting point of a WGF on the KL divergence, with Parzen smoothing on the densities. Second, that the algorithm actually implemented by Deng et al. (2026) corresponds to a different procedure, which bears some resemblance to the fixed point of a WGF on the Sinkhorn divergence, but lacks certain desirable properties of the latter. Third, the same same idea can be extended to the limiting point of other WGFs, including the Maximum Mean Discrepancy (MMD), the sliced Wasserstein distance, and GAN critic functions.
Closed-Form Last Layer Optimization
Oct 06, 2025Neural networks are typically optimized with variants of stochastic gradient descent. Under a squared loss, however, the optimal solution to the linear last layer weights is known in closed-form. We propose to leverage this during optimization, treating the last layer as a function of the backbone parameters, and optimizing solely for these parameters. We show this is equivalent to alternating between gradient descent steps on the backbone and closed-form updates on the last layer. We adapt the method for the setting of stochastic gradient descent, by trading off the loss on the current batch against the accumulated information from previous batches. Further, we prove that, in the Neural Tangent Kernel regime, convergence of this method to an optimal solution is guaranteed. Finally, we demonstrate the effectiveness of our approach compared with standard SGD on a squared loss in several supervised tasks -- both regression and classification -- including Fourier Neural Operators and Instrumental Variable Regression.
Learn to Guide Your Diffusion Model
Oct 01, 2025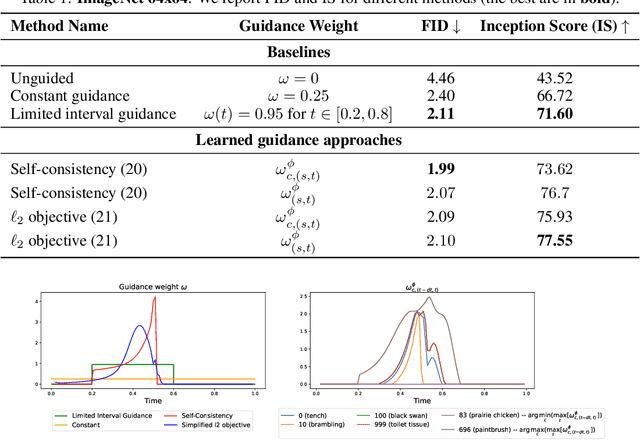
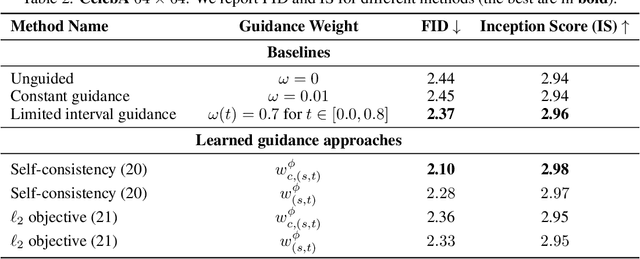
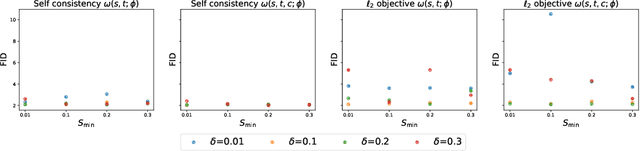

Classifier-free guidance (CFG) is a widely used technique for improving the perceptual quality of samples from conditional diffusion models. It operates by linearly combining conditional and unconditional score estimates using a guidance weight $\omega$. While a large, static weight can markedly improve visual results, this often comes at the cost of poorer distributional alignment. In order to better approximate the target conditional distribution, we instead learn guidance weights $\omega_{c,(s,t)}$, which are continuous functions of the conditioning $c$, the time $t$ from which we denoise, and the time $s$ towards which we denoise. We achieve this by minimizing the distributional mismatch between noised samples from the true conditional distribution and samples from the guided diffusion process. We extend our framework to reward guided sampling, enabling the model to target distributions tilted by a reward function $R(x_0,c)$, defined on clean data and a conditioning $c$. We demonstrate the effectiveness of our methodology on low-dimensional toy examples and high-dimensional image settings, where we observe improvements in Fr\'echet inception distance (FID) for image generation. In text-to-image applications, we observe that employing a reward function given by the CLIP score leads to guidance weights that improve image-prompt alignment.
Distributional Diffusion Models with Scoring Rules
Feb 04, 2025Diffusion models generate high-quality synthetic data. They operate by defining a continuous-time forward process which gradually adds Gaussian noise to data until fully corrupted. The corresponding reverse process progressively "denoises" a Gaussian sample into a sample from the data distribution. However, generating high-quality outputs requires many discretization steps to obtain a faithful approximation of the reverse process. This is expensive and has motivated the development of many acceleration methods. We propose to accomplish sample generation by learning the posterior {\em distribution} of clean data samples given their noisy versions, instead of only the mean of this distribution. This allows us to sample from the probability transitions of the reverse process on a coarse time scale, significantly accelerating inference with minimal degradation of the quality of the output. This is accomplished by replacing the standard regression loss used to estimate conditional means with a scoring rule. We validate our method on image and robot trajectory generation, where we consistently outperform standard diffusion models at few discretization steps.
Accelerated Diffusion Models via Speculative Sampling
Jan 09, 2025
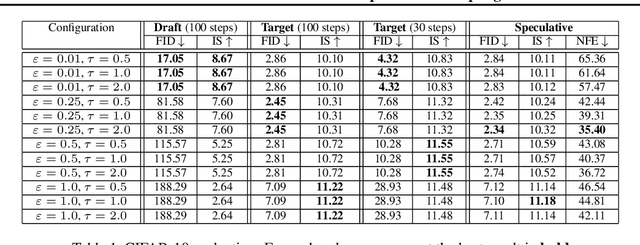

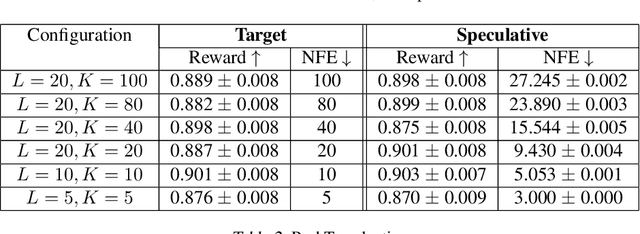
Speculative sampling is a popular technique for accelerating inference in Large Language Models by generating candidate tokens using a fast draft model and accepting or rejecting them based on the target model's distribution. While speculative sampling was previously limited to discrete sequences, we extend it to diffusion models, which generate samples via continuous, vector-valued Markov chains. In this context, the target model is a high-quality but computationally expensive diffusion model. We propose various drafting strategies, including a simple and effective approach that does not require training a draft model and is applicable out of the box to any diffusion model. Our experiments demonstrate significant generation speedup on various diffusion models, halving the number of function evaluations, while generating exact samples from the target model.
Non-Stationary Learning of Neural Networks with Automatic Soft Parameter Reset
Nov 06, 2024



Neural networks are traditionally trained under the assumption that data come from a stationary distribution. However, settings which violate this assumption are becoming more popular; examples include supervised learning under distributional shifts, reinforcement learning, continual learning and non-stationary contextual bandits. In this work we introduce a novel learning approach that automatically models and adapts to non-stationarity, via an Ornstein-Uhlenbeck process with an adaptive drift parameter. The adaptive drift tends to draw the parameters towards the initialisation distribution, so the approach can be understood as a form of soft parameter reset. We show empirically that our approach performs well in non-stationary supervised and off-policy reinforcement learning settings.
Deep MMD Gradient Flow without adversarial training
May 10, 2024We propose a gradient flow procedure for generative modeling by transporting particles from an initial source distribution to a target distribution, where the gradient field on the particles is given by a noise-adaptive Wasserstein Gradient of the Maximum Mean Discrepancy (MMD). The noise-adaptive MMD is trained on data distributions corrupted by increasing levels of noise, obtained via a forward diffusion process, as commonly used in denoising diffusion probabilistic models. The result is a generalization of MMD Gradient Flow, which we call Diffusion-MMD-Gradient Flow or DMMD. The divergence training procedure is related to discriminator training in Generative Adversarial Networks (GAN), but does not require adversarial training. We obtain competitive empirical performance in unconditional image generation on CIFAR10, MNIST, CELEB-A (64 x64) and LSUN Church (64 x 64). Furthermore, we demonstrate the validity of the approach when MMD is replaced by a lower bound on the KL divergence.
Revisiting Dynamic Evaluation: Online Adaptation for Large Language Models
Mar 03, 2024



We consider the problem of online fine tuning the parameters of a language model at test time, also known as dynamic evaluation. While it is generally known that this approach improves the overall predictive performance, especially when considering distributional shift between training and evaluation data, we here emphasize the perspective that online adaptation turns parameters into temporally changing states and provides a form of context-length extension with memory in weights, more in line with the concept of memory in neuroscience. We pay particular attention to the speed of adaptation (in terms of sample efficiency),sensitivity to the overall distributional drift, and the computational overhead for performing gradient computations and parameter updates. Our empirical study provides insights on when online adaptation is particularly interesting. We highlight that with online adaptation the conceptual distinction between in-context learning and fine tuning blurs: both are methods to condition the model on previously observed tokens.
Kalman Filter for Online Classification of Non-Stationary Data
Jun 14, 2023



In Online Continual Learning (OCL) a learning system receives a stream of data and sequentially performs prediction and training steps. Important challenges in OCL are concerned with automatic adaptation to the particular non-stationary structure of the data, and with quantification of predictive uncertainty. Motivated by these challenges we introduce a probabilistic Bayesian online learning model by using a (possibly pretrained) neural representation and a state space model over the linear predictor weights. Non-stationarity over the linear predictor weights is modelled using a parameter drift transition density, parametrized by a coefficient that quantifies forgetting. Inference in the model is implemented with efficient Kalman filter recursions which track the posterior distribution over the linear weights, while online SGD updates over the transition dynamics coefficient allows to adapt to the non-stationarity seen in data. While the framework is developed assuming a linear Gaussian model, we also extend it to deal with classification problems and for fine-tuning the deep learning representation. In a set of experiments in multi-class classification using data sets such as CIFAR-100 and CLOC we demonstrate the predictive ability of the model and its flexibility to capture non-stationarity.