 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemma 3 Technical Report
Mar 25, 2025We introduce Gemma 3, a multimodal addition to the Gemma family of lightweight open models, ranging in scale from 1 to 27 billion parameters. This version introduces vision understanding abilities, a wider coverage of languages and longer context - at least 128K tokens. We also change the architecture of the model to reduce the KV-cache memory that tends to explode with long context. This is achieved by increasing the ratio of local to global attention layers, and keeping the span on local attention short. The Gemma 3 models are trained with distillation and achieve superior performance to Gemma 2 for both pre-trained and instruction finetuned versions. In particular, our novel post-training recipe significantly improves the math, chat, instruction-following and multilingual abilities, making Gemma3-4B-IT competitive with Gemma2-27B-IT and Gemma3-27B-IT comparable to Gemini-1.5-Pro across benchmarks. We release all our models to the community.
Capturing Individual Human Preferences with Reward Features
Mar 21, 2025



Reinforcement learning from human feedback usually models preferences using a reward model that does not distinguish between people. We argue that this is unlikely to be a good design choice in contexts with high potential for disagreement, like in the training of large language models. We propose a method to specialise a reward model to a person or group of people. Our approach builds on the observation that individual preferences can be captured as a linear combination of a set of general reward features. We show how to learn such features and subsequently use them to quickly adapt the reward model to a specific individual, even if their preferences are not reflected in the training data. We present experiments with large language models comparing the proposed architecture with a non-adaptive reward model and also adaptive counterparts, including models that do in-context personalisation. Depending on how much disagreement there is in the training data, our model either significantly outperforms the baselines or matches their performance with a simpler architecture and more stable training.
Preference Optimization as Probabilistic Inference
Oct 05, 2024



Existing preference optimization methods are mainly designed for directly learning from human feedback with the assumption that paired examples (preferred vs. dis-preferred) are available. In contrast, we propose a method that can leverage unpaired preferred or dis-preferred examples, and works even when only one type of feedback (positive or negative) is available. This flexibility allows us to apply it in scenarios with varying forms of feedback and models, including training generative language models based on human feedback as well as training policies for sequential decision-making problems, where learned (value) functions are available. Our approach builds upon the probabilistic framework introduced in (Dayan and Hinton, 1997), which proposes to use expectation-maximization (EM) to directly optimize the probability of preferred outcomes (as opposed to classic expected reward maximization). To obtain a practical algorithm, we identify and address a key limitation in current EM-based methods: when applied to preference optimization, they solely maximize the likelihood of preferred examples, while neglecting dis-preferred samples. We show how one can extend EM algorithms to explicitly incorporate dis-preferred outcomes, leading to a novel, theoretically grounded, preference optimization algorithm that offers an intuitive and versatile way to learn from both positive and negative feedback.
Gemma 2: Improving Open Language Models at a Practical Size
Aug 02, 2024



In this work, we introduce Gemma 2, a new addition to the Gemma family of lightweight, state-of-the-art open models, ranging in scale from 2 billion to 27 billion parameters. In this new version, we apply several known technical modifications to the Transformer architecture, such as interleaving local-global attentions (Beltagy et al., 2020a) and group-query attention (Ainslie et al., 2023). We also train the 2B and 9B models with knowledge distillation (Hinton et al., 2015) instead of next token prediction. The resulting models deliver the best performance for their size, and even offer competitive alternatives to models that are 2-3 times bigger. We release all our models to the community.
Gemma: Open Models Based on Gemini Research and Technology
Mar 13, 2024



This work introduces Gemma, a family of lightweight, state-of-the art open models built from the research and technology used to create Gemini models. Gemma models demonstrate strong performance across academic benchmarks for language understanding, reasoning, and safety. We release two sizes of models (2 billion and 7 billion parameters), and provide both pretrained and fine-tuned checkpoints. Gemma outperforms similarly sized open models on 11 out of 18 text-based tasks, and we present comprehensive evaluations of safety and responsibility aspects of the models, alongside a detailed description of model development. We believe the responsible release of LLMs is critical for improving the safety of frontier models, and for enabling the next wave of LLM innovations.
Knowledge Transfer from Teachers to Learners in Growing-Batch Reinforcement Learning
May 09, 2023



Standard approaches to sequential decision-making exploit an agent's ability to continually interact with its environment and improve its control policy. However, due to safety, ethical, and practicality constraints, this type of trial-and-error experimentation is often infeasible in many real-world domains such as healthcare and robotics. Instead, control policies in these domains are typically trained offline from previously logged data or in a growing-batch manner. In this setting a fixed policy is deployed to the environment and used to gather an entire batch of new data before being aggregated with past batches and used to update the policy. This improvement cycle can then be repeated multiple times. While a limited number of such cycles is feasible in real-world domains, the quality and diversity of the resulting data are much lower than in the standard continually-interacting approach. However, data collection in these domains is often performed in conjunction with human experts, who are able to label or annotate the collected data. In this paper, we first explore the trade-offs present in this growing-batch setting, and then investigate how information provided by a teacher (i.e., demonstrations, expert actions, and gradient information) can be leveraged at training time to mitigate the sample complexity and coverage requirements for actor-critic methods. We validate our contributions on tasks from the DeepMind Control Suite.
Revisiting Gaussian mixture critics in off-policy reinforcement learning: a sample-based approach
Apr 22, 2022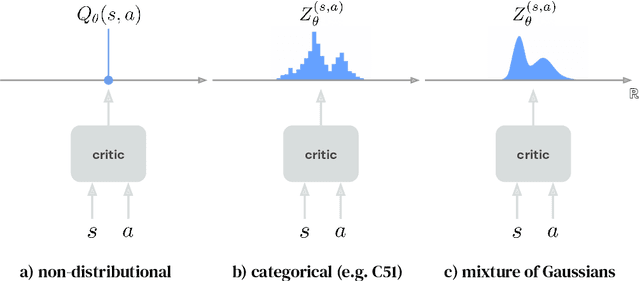
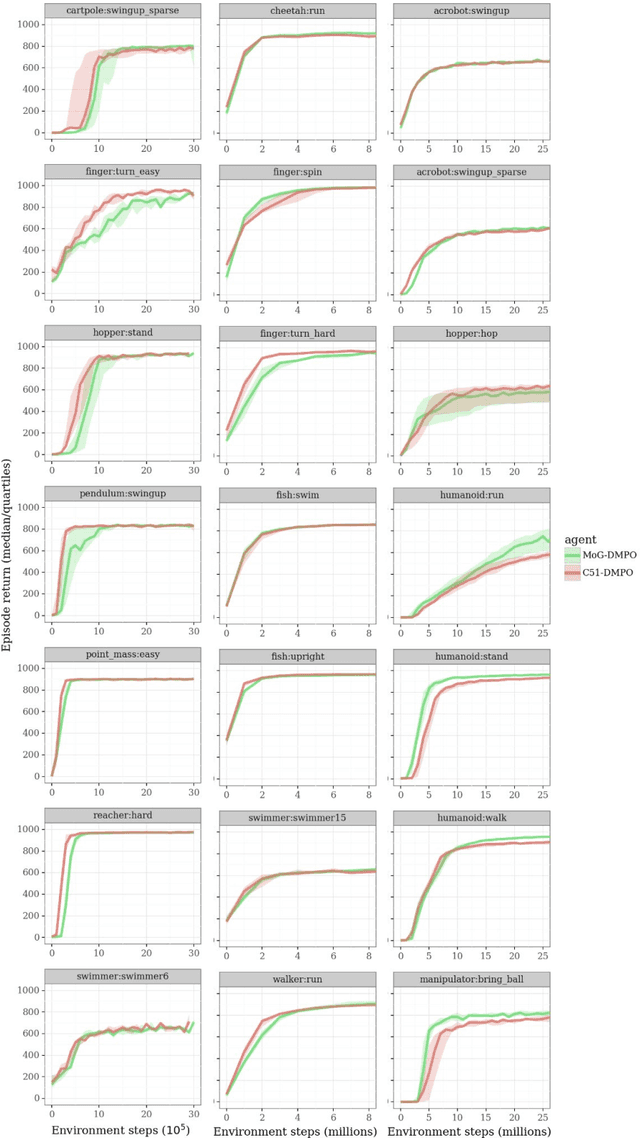
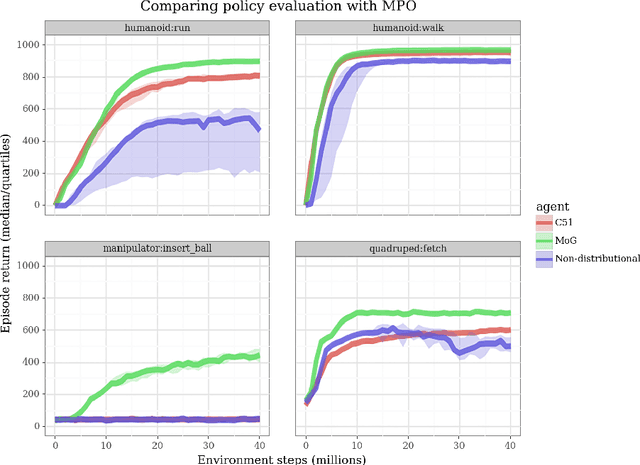
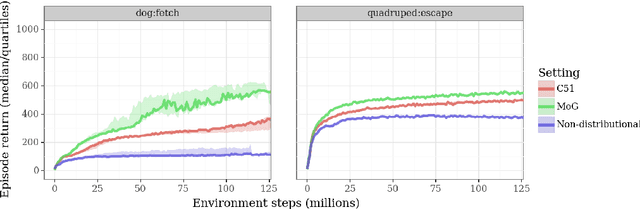
Actor-critic algorithms that make use of distributional policy evaluation have frequently been shown to outperform their non-distributional counterparts on many challenging control tasks. Examples of this behavior include the D4PG and DMPO algorithms as compared to DDPG and MPO, respectively [Barth-Maron et al., 2018; Hoffman et al., 2020]. However, both agents rely on the C51 critic for value estimation.One major drawback of the C51 approach is its requirement of prior knowledge about the minimum andmaximum values a policy can attain as well as the number of bins used, which fixes the resolution ofthe distributional estimate. While the DeepMind control suite of tasks utilizes standardized rewards and episode lengths, thus enabling the entire suite to be solved with a single setting of these hyperparameters, this is often not the case. This paper revisits a natural alternative that removes this requirement, namelya mixture of Gaussians, and a simple sample-based loss function to train it in an off-policy regime. We empirically evaluate its performance on a broad range of continuous control tasks and demonstrate that it eliminates the need for these distributional hyperparameters and achieves state-of-the-art performance on a variety of challenging tasks (e.g. the humanoid, dog, quadruped, and manipulator domains). Finallywe provide an implementation in the Acme agent repository.
On Multi-objective Policy Optimization as a Tool for Reinforcement Learning
Jun 15, 2021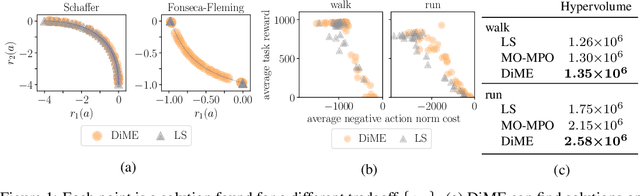
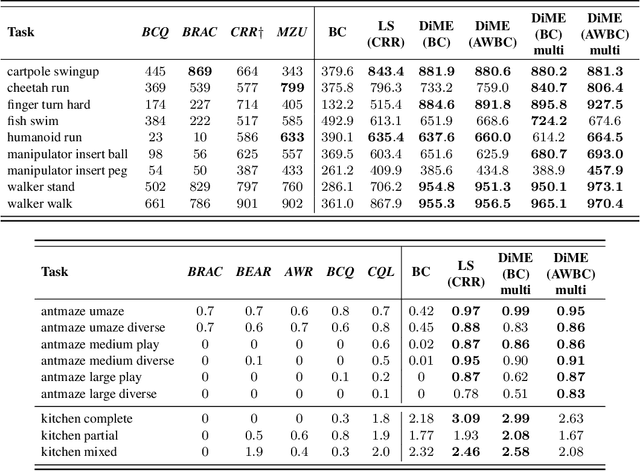
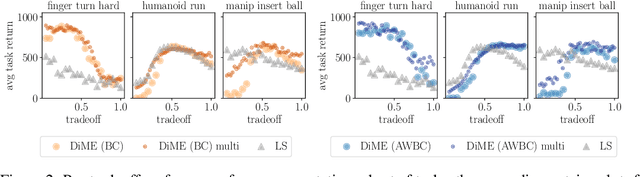

Many advances that have improved the robustness and efficiency of deep reinforcement learning (RL) algorithms can, in one way or another, be understood as introducing additional objectives, or constraints, in the policy optimization step. This includes ideas as far ranging as exploration bonuses, entropy regularization, and regularization toward teachers or data priors when learning from experts or in offline RL. Often, task reward and auxiliary objectives are in conflict with each other and it is therefore natural to treat these examples as instances of multi-objective (MO) optimization problems. We study the principles underlying MORL and introduce a new algorithm, Distillation of a Mixture of Experts (DiME), that is intuitive and scale-invariant under some conditions. We highlight its strengths on standard MO benchmark problems and consider case studies in which we recast offline RL and learning from experts as MO problems. This leads to a natural algorithmic formulation that sheds light on the connection between existing approaches. For offline RL, we use the MO perspective to derive a simple algorithm, that optimizes for the standard RL objective plus a behavioral cloning term. This outperforms state-of-the-art on two established offline RL benchmarks.
Critic Regularized Regression
Jun 26, 2020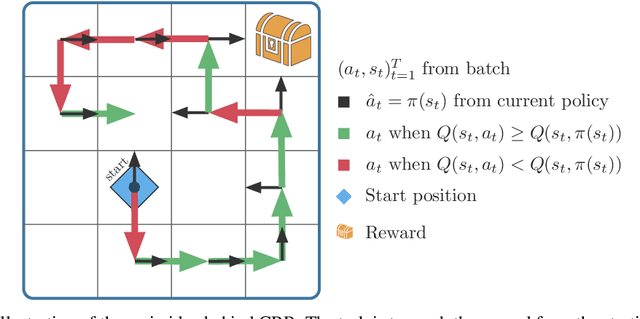


Offline reinforcement learning (RL), also known as batch RL, offers the prospect of policy optimization from large pre-recorded datasets without online environment interaction. It addresses challenges with regard to the cost of data collection and safety, both of which are particularly pertinent to real-world applications of RL. Unfortunately, most off-policy algorithms perform poorly when learning from a fixed dataset. In this paper, we propose a novel offline RL algorithm to learn policies from data using a form of critic-regularized regression (CRR). We find that CRR performs surprisingly well and scales to tasks with high-dimensional state and action spaces -- outperforming several state-of-the-art offline RL algorithms by a significant margin on a wide range of benchmark tasks.
Acme: A Research Framework for Distributed Reinforcement Learning
Jun 01, 2020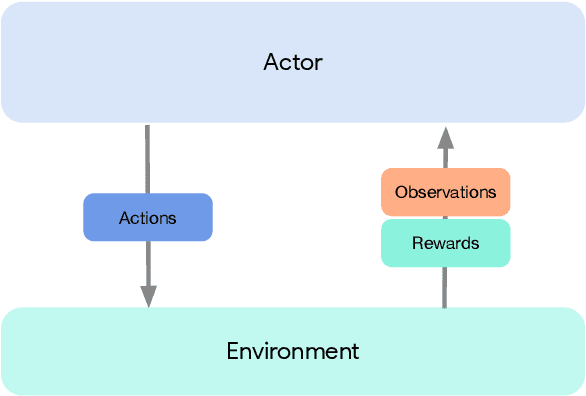
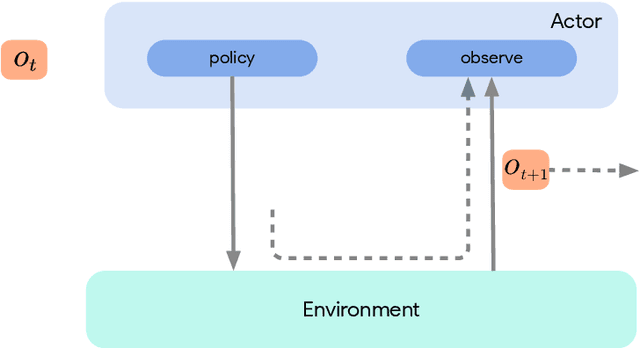
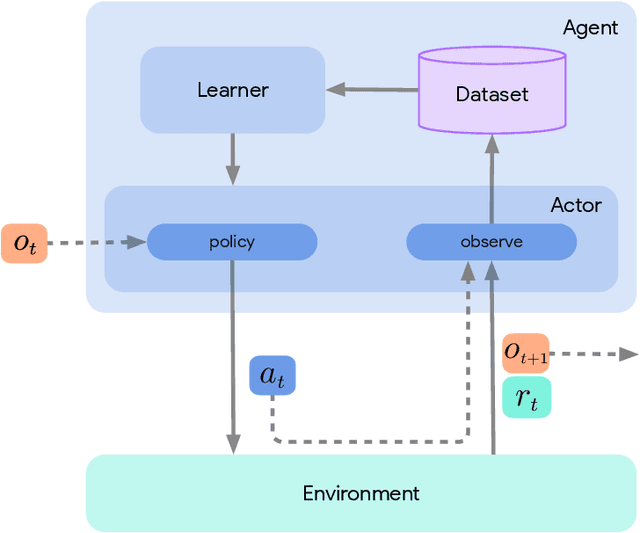
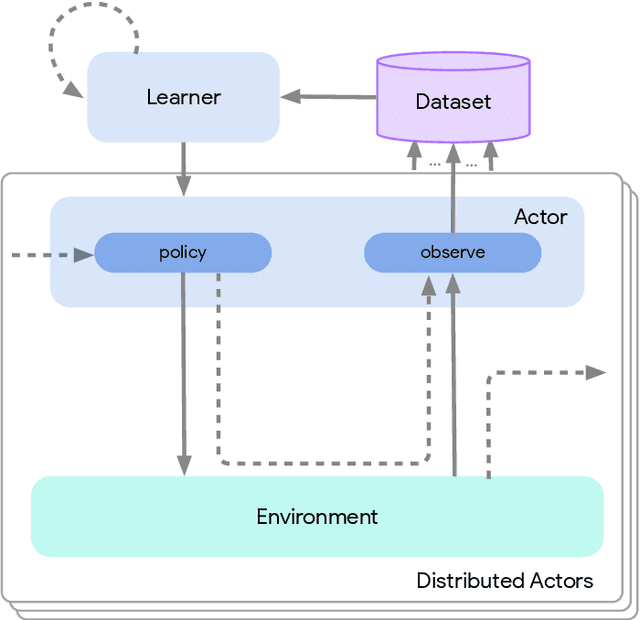
Deep reinforcement learning has led to many recent-and groundbreaking-advancements. However, these advances have often come at the cost of both the scale and complexity of the underlying RL algorithms. Increases in complexity have in turn made it more difficult for researchers to reproduce published RL algorithms or rapidly prototype ideas. To address this, we introduce Acme, a tool to simplify the development of novel RL algorithms that is specifically designed to enable simple agent implementations that can be run at various scales of execution. Our aim is also to make the results of various RL algorithms developed in academia and industrial labs easier to reproduce and extend. To this end we are releasing baseline implementations of various algorithms, created using our framework. In this work we introduce the major design decisions behind Acme and show how these are used to construct these baselines. We also experiment with these agents at different scales of both complexity and computation-including distributed versions. Ultimately, we show that the design decisions behind Acme lead to agents that can be scaled both up and down and that, for the most part, greater levels of parallelization result in agents with equivalent performance, just faster.