 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExoStart: Efficient learning for dexterous manipulation with sensorized exoskeleton demonstrations
Jun 13, 2025



Recent advancements in teleoperation systems have enabled high-quality data collection for robotic manipulators, showing impressive results in learning manipulation at scale. This progress suggests that extending these capabilities to robotic hands could unlock an even broader range of manipulation skills, especially if we could achieve the same level of dexterity that human hands exhibit. However, teleoperating robotic hands is far from a solved problem, as it presents a significant challenge due to the high degrees of freedom of robotic hands and the complex dynamics occurring during contact-rich settings. In this work, we present ExoStart, a general and scalable learning framework that leverages human dexterity to improve robotic hand control. In particular, we obtain high-quality data by collecting direct demonstrations without a robot in the loop using a sensorized low-cost wearable exoskeleton, capturing the rich behaviors that humans can demonstrate with their own hands. We also propose a simulation-based dynamics filter that generates dynamically feasible trajectories from the collected demonstrations and use the generated trajectories to bootstrap an auto-curriculum reinforcement learning method that relies only on simple sparse rewards. The ExoStart pipeline is generalizable and yields robust policies that transfer zero-shot to the real robot. Our results demonstrate that ExoStart can generate dexterous real-world hand skills, achieving a success rate above 50% on a wide range of complex tasks such as opening an AirPods case or inserting and turning a key in a lock. More details and videos can be found in https://sites.google.com/view/exostart.
Gemini Robotics: Bringing AI into the Physical World
Mar 25, 2025Recent advancements in large multimodal models have led to the emergence of remarkable generalist capabilities in digital domains, yet their translation to physical agents such as robots remains a significant challenge. This report introduces a new family of AI models purposefully designed for robotics and built upon the foundation of Gemini 2.0. We present Gemini Robotics, an advanced Vision-Language-Action (VLA) generalist model capable of directly controlling robots. Gemini Robotics executes smooth and reactive movements to tackle a wide range of complex manipulation tasks while also being robust to variations in object types and positions, handling unseen environments as well as following diverse, open vocabulary instructions. We show that with additional fine-tuning, Gemini Robotics can be specialized to new capabilities including solving long-horizon, highly dexterous tasks, learning new short-horizon tasks from as few as 100 demonstrations and adapting to completely novel robot embodiments. This is made possible because Gemini Robotics builds on top of the Gemini Robotics-ER model, the second model we introduce in this work. Gemini Robotics-ER (Embodied Reasoning) extends Gemini's multimodal reasoning capabilities into the physical world, with enhanced spatial and temporal understanding. This enables capabilities relevant to robotics including object detection, pointing, trajectory and grasp prediction, as well as multi-view correspondence and 3D bounding box predictions. We show how this novel combination can support a variety of robotics applications. We also discuss and address important safety considerations related to this new class of robotics foundation models. The Gemini Robotics family marks a substantial step towards developing general-purpose robots that realizes AI's potential in the physical world.
DemoStart: Demonstration-led auto-curriculum applied to sim-to-real with multi-fingered robots
Sep 10, 2024



We present DemoStart, a novel auto-curriculum reinforcement learning method capable of learning complex manipulation behaviors on an arm equipped with a three-fingered robotic hand, from only a sparse reward and a handful of demonstrations in simulation. Learning from simulation drastically reduces the development cycle of behavior generation, and domain randomization techniques are leveraged to achieve successful zero-shot sim-to-real transfer. Transferred policies are learned directly from raw pixels from multiple cameras and robot proprioception. Our approach outperforms policies learned from demonstrations on the real robot and requires 100 times fewer demonstrations, collected in simulation. More details and videos in https://sites.google.com/view/demostart.
RoboCat: A Self-Improving Foundation Agent for Robotic Manipulation
Jun 20, 2023



The ability to leverage heterogeneous robotic experience from different robots and tasks to quickly master novel skills and embodiments has the potential to transform robot learning. Inspired by recent advances in foundation models for vision and language, we propose a foundation agent for robotic manipulation. This agent, named RoboCat, is a visual goal-conditioned decision transformer capable of consuming multi-embodiment action-labelled visual experience. This data spans a large repertoire of motor control skills from simulated and real robotic arms with varying sets of observations and actions. With RoboCat, we demonstrate the ability to generalise to new tasks and robots, both zero-shot as well as through adaptation using only 100--1000 examples for the target task. We also show how a trained model itself can be used to generate data for subsequent training iterations, thus providing a basic building block for an autonomous improvement loop. We investigate the agent's capabilities, with large-scale evaluations both in simulation and on three different real robot embodiments. We find that as we grow and diversify its training data, RoboCat not only shows signs of cross-task transfer, but also becomes more efficient at adapting to new tasks.
How to Spend Your Robot Time: Bridging Kickstarting and Offline Reinforcement Learning for Vision-based Robotic Manipulation
May 06, 2022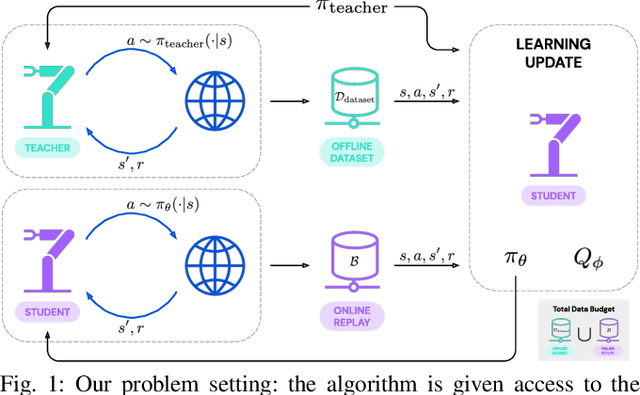

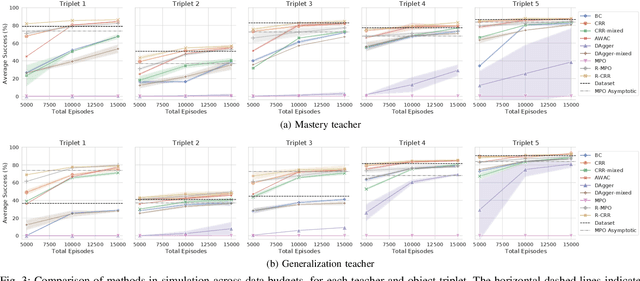
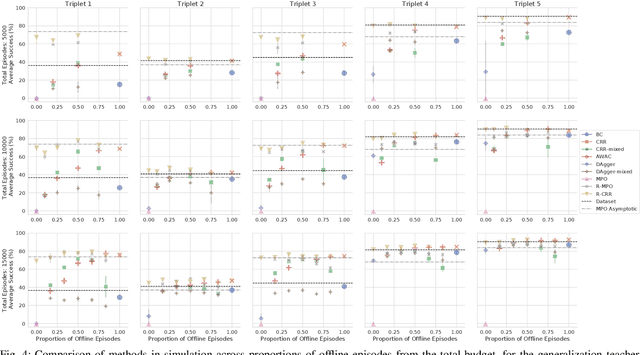
Reinforcement learning (RL) has been shown to be effective at learning control from experience. However, RL typically requires a large amount of online interaction with the environment. This limits its applicability to real-world settings, such as in robotics, where such interaction is expensive. In this work we investigate ways to minimize online interactions in a target task, by reusing a suboptimal policy we might have access to, for example from training on related prior tasks, or in simulation. To this end, we develop two RL algorithms that can speed up training by using not only the action distributions of teacher policies, but also data collected by such policies on the task at hand. We conduct a thorough experimental study of how to use suboptimal teachers on a challenging robotic manipulation benchmark on vision-based stacking with diverse objects. We compare our methods to offline, online, offline-to-online, and kickstarting RL algorithms. By doing so, we find that training on data from both the teacher and student, enables the best performance for limited data budgets. We examine how to best allocate a limited data budget -- on the target task -- between the teacher and the student policy, and report experiments using varying budgets, two teachers with different degrees of suboptimality, and five stacking tasks that require a diverse set of behaviors. Our analysis, both in simulation and in the real world, shows that our approach is the best across data budgets, while standard offline RL from teacher rollouts is surprisingly effective when enough data is given.
Beyond Pick-and-Place: Tackling Robotic Stacking of Diverse Shapes
Nov 03, 2021
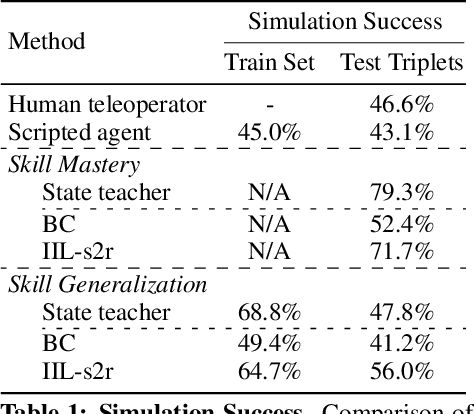
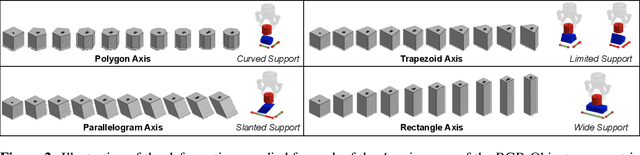
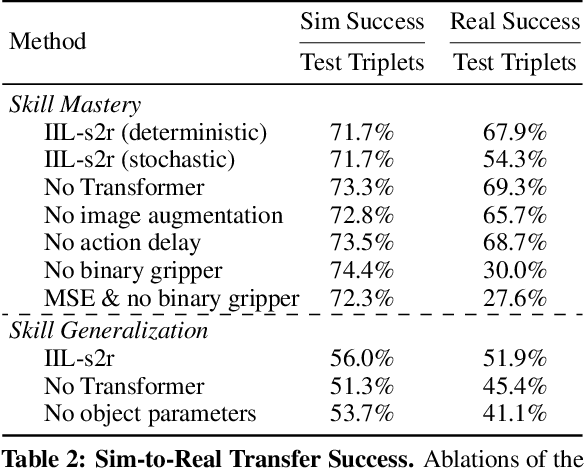
We study the problem of robotic stacking with objects of complex geometry. We propose a challenging and diverse set of such objects that was carefully designed to require strategies beyond a simple "pick-and-place" solution. Our method is a reinforcement learning (RL) approach combined with vision-based interactive policy distillation and simulation-to-reality transfer. Our learned policies can efficiently handle multiple object combinations in the real world and exhibit a large variety of stacking skills. In a large experimental study, we investigate what choices matter for learning such general vision-based agents in simulation, and what affects optimal transfer to the real robot. We then leverage data collected by such policies and improve upon them with offline RL. A video and a blog post of our work are provided as supplementary material.
Learning Coordinated Terrain-Adaptive Locomotion by Imitating a Centroidal Dynamics Planner
Oct 30, 2021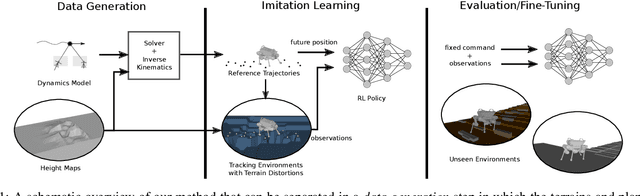
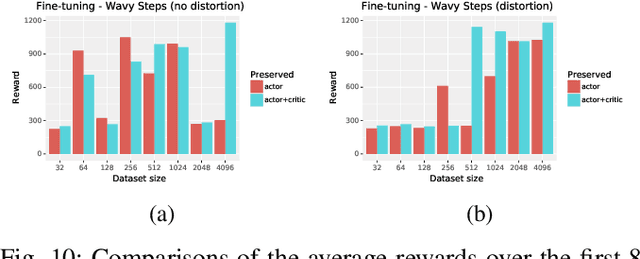

Dynamic quadruped locomotion over challenging terrains with precise foot placements is a hard problem for both optimal control methods and Reinforcement Learning (RL). Non-linear solvers can produce coordinated constraint satisfying motions, but often take too long to converge for online application. RL methods can learn dynamic reactive controllers but require carefully tuned shaping rewards to produce good gaits and can have trouble discovering precise coordinated movements. Imitation learning circumvents this problem and has been used with motion capture data to extract quadruped gaits for flat terrains. However, it would be costly to acquire motion capture data for a very large variety of terrains with height differences. In this work, we combine the advantages of trajectory optimization and learning methods and show that terrain adaptive controllers can be obtained by training policies to imitate trajectories that have been planned over procedural terrains by a non-linear solver. We show that the learned policies transfer to unseen terrains and can be fine-tuned to dynamically traverse challenging terrains that require precise foot placements and are very hard to solve with standard RL.
On Multi-objective Policy Optimization as a Tool for Reinforcement Learning
Jun 15, 2021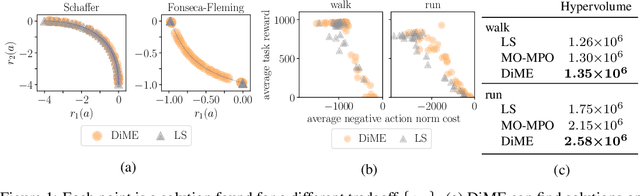
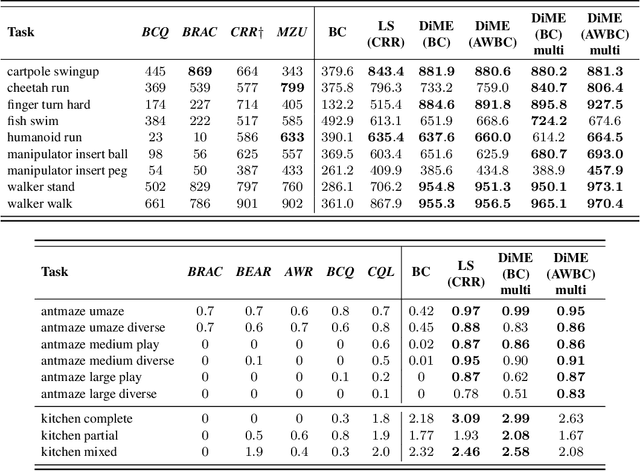
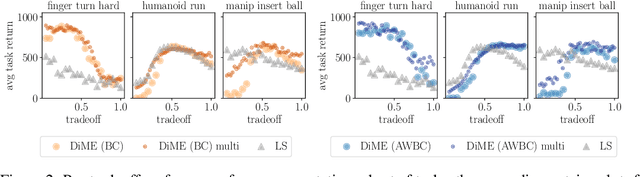

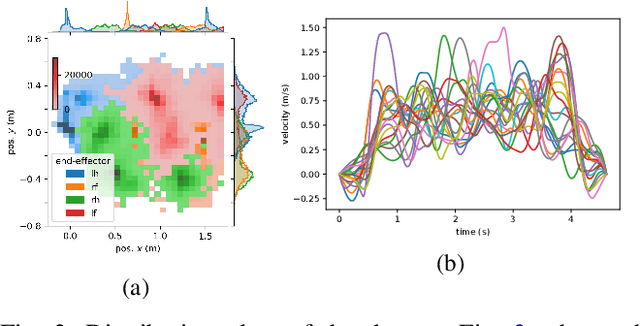
Many advances that have improved the robustness and efficiency of deep reinforcement learning (RL) algorithms can, in one way or another, be understood as introducing additional objectives, or constraints, in the policy optimization step. This includes ideas as far ranging as exploration bonuses, entropy regularization, and regularization toward teachers or data priors when learning from experts or in offline RL. Often, task reward and auxiliary objectives are in conflict with each other and it is therefore natural to treat these examples as instances of multi-objective (MO) optimization problems. We study the principles underlying MORL and introduce a new algorithm, Distillation of a Mixture of Experts (DiME), that is intuitive and scale-invariant under some conditions. We highlight its strengths on standard MO benchmark problems and consider case studies in which we recast offline RL and learning from experts as MO problems. This leads to a natural algorithmic formulation that sheds light on the connection between existing approaches. For offline RL, we use the MO perspective to derive a simple algorithm, that optimizes for the standard RL objective plus a behavioral cloning term. This outperforms state-of-the-art on two established offline RL benchmarks.
Manipulator-Independent Representations for Visual Imitation
Mar 18, 2021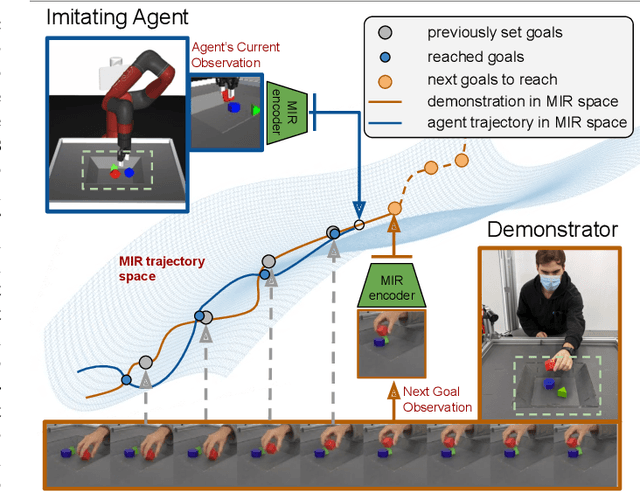
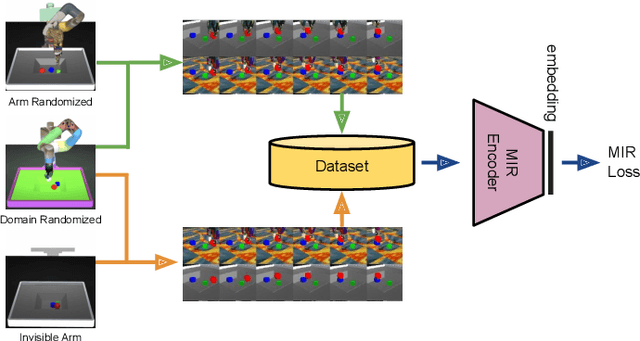
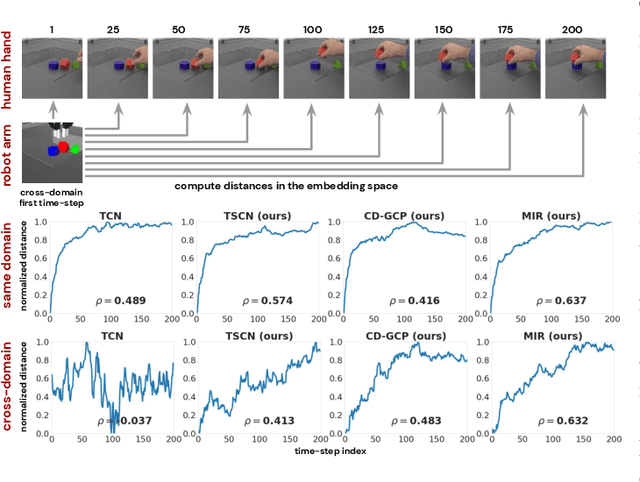
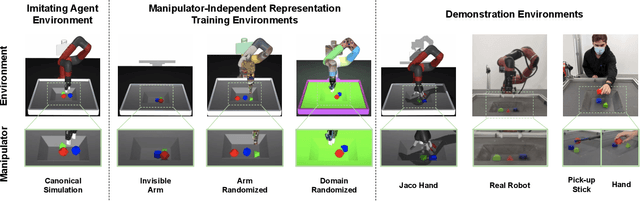
Imitation learning is an effective tool for robotic learning tasks where specifying a reinforcement learning (RL) reward is not feasible or where the exploration problem is particularly difficult. Imitation, typically behavior cloning or inverse RL, derive a policy from a collection of first-person action-state trajectories. This is contrary to how humans and other animals imitate: we observe a behavior, even from other species, understand its perceived effect on the state of the environment, and figure out what actions our body can perform to reach a similar outcome. In this work, we explore the possibility of third-person visual imitation of manipulation trajectories, only from vision and without access to actions, demonstrated by embodiments different to the ones of our imitating agent. Specifically, we investigate what would be an appropriate representation method with which an RL agent can visually track trajectories of complex manipulation behavior -- non-planar with multiple-object interactions -- demonstrated by experts with different embodiments. We present a way to train manipulator-independent representations (MIR) that primarily focus on the change in the environment and have all the characteristics that make them suitable for cross-embodiment visual imitation with RL: cross-domain alignment, temporal smoothness, and being actionable. We show that with our proposed method our agents are able to imitate, with complex robot control, trajectories from a variety of embodiments and with significant visual and dynamics differences, e.g. simulation-to-reality gap.
Self-Supervised Sim-to-Real Adaptation for Visual Robotic Manipulation
Oct 21, 2019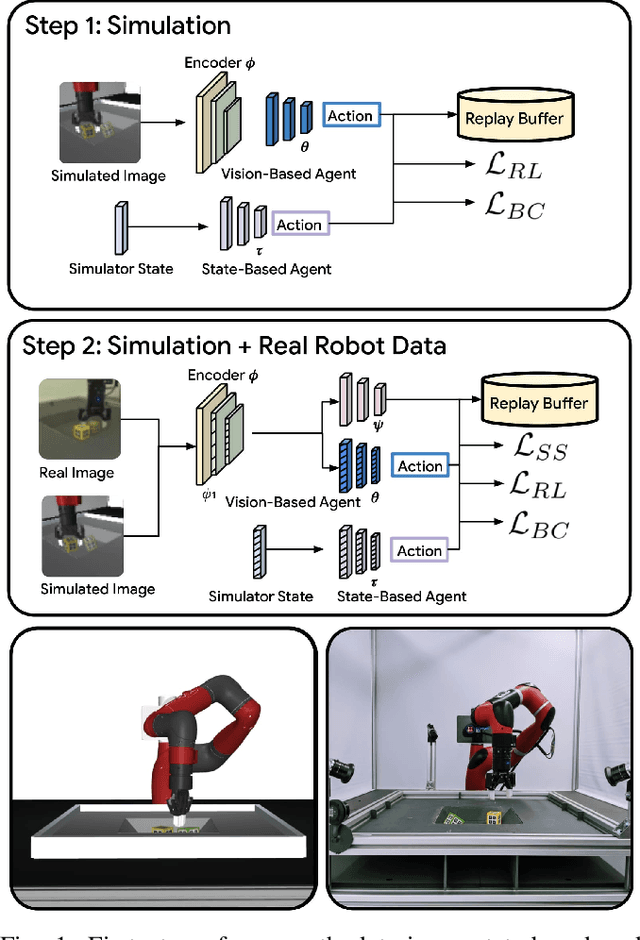

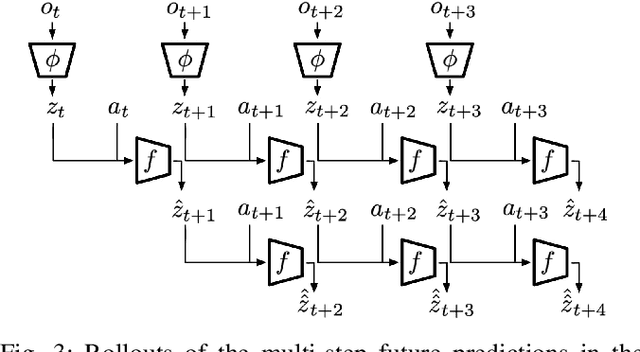
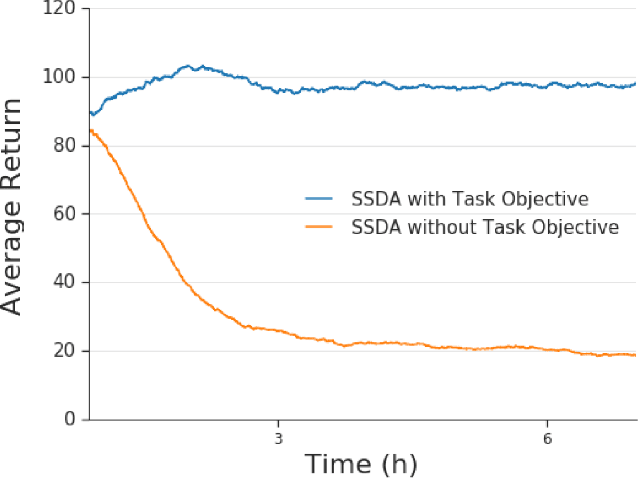
Collecting and automatically obtaining reward signals from real robotic visual data for the purposes of training reinforcement learning algorithms can be quite challenging and time-consuming. Methods for utilizing unlabeled data can have a huge potential to further accelerate robotic learning. We consider here the problem of performing manipulation tasks from pixels. In such tasks, choosing an appropriate state representation is crucial for planning and control. This is even more relevant with real images where noise, occlusions and resolution affect the accuracy and reliability of state estimation. In this work, we learn a latent state representation implicitly with deep reinforcement learning in simulation, and then adapt it to the real domain using unlabeled real robot data. We propose to do so by optimizing sequence-based self supervised objectives. These exploit the temporal nature of robot experience, and can be common in both the simulated and real domains, without assuming any alignment of underlying states in simulated and unlabeled real images. We propose Contrastive Forward Dynamics loss, which combines dynamics model learning with time-contrastive techniques. The learned state representation that results from our methods can be used to robustly solve a manipulation task in simulation and to successfully transfer the learned skill on a real system. We demonstrate the effectiveness of our approaches by training a vision-based reinforcement learning agent for cube stacking. Agents trained with our method, using only 5 hours of unlabeled real robot data for adaptation, shows a clear improvement over domain randomization, and standard visual domain adaptation techniques for sim-to-real transfer.