 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimistic Actor-Critic with Parametric Policies for Linear Markov Decision Processes
Apr 01, 2026Although actor-critic methods have been successful in practice, their theoretical analyses have several limitations. Specifically, existing theoretical work either sidesteps the exploration problem by making strong assumptions or analyzes impractical methods with complicated algorithmic modifications. Moreover, the actor-critic methods analyzed for linear MDPs often employ natural policy gradient and construct "implicit" policies without explicit parameterization. Such policies are computationally expensive to sample from, making the environment interactions inefficient. To that end, we focus on the finite-horizon linear MDPs and propose an optimistic actor-critic framework that uses parametric log-linear policies. In particular, we introduce a tractable $\textit{logit-matching}$ regression objective for the actor. For the critic, we use approximate Thompson sampling via Langevin Monte Carlo to obtain optimistic value estimates. We prove that the resulting algorithm achieves $\widetilde{\mathcal{O}}(ε^{-4})$ and $\widetilde{\mathcal{O}}(ε^{-2})$ sample complexity in the on-policy and off-policy setting, respectively. Our results match prior theoretical work in achieving the state-of-the-art sample complexity, while our algorithm is more aligned with practice.
Rethinking the Global Convergence of Softmax Policy Gradient with Linear Function Approximation
May 06, 2025Policy gradient (PG) methods have played an essential role in the empirical successes of reinforcement learning. In order to handle large state-action spaces, PG methods are typically used with function approximation. In this setting, the approximation error in modeling problem-dependent quantities is a key notion for characterizing the global convergence of PG methods. We focus on Softmax PG with linear function approximation (referred to as $\texttt{Lin-SPG}$) and demonstrate that the approximation error is irrelevant to the algorithm's global convergence even for the stochastic bandit setting. Consequently, we first identify the necessary and sufficient conditions on the feature representation that can guarantee the asymptotic global convergence of $\texttt{Lin-SPG}$. Under these feature conditions, we prove that $T$ iterations of $\texttt{Lin-SPG}$ with a problem-specific learning rate result in an $O(1/T)$ convergence to the optimal policy. Furthermore, we prove that $\texttt{Lin-SPG}$ with any arbitrary constant learning rate can ensure asymptotic global convergence to the optimal policy.
Ordering-based Conditions for Global Convergence of Policy Gradient Methods
Apr 02, 2025


We prove that, for finite-arm bandits with linear function approximation, the global convergence of policy gradient (PG) methods depends on inter-related properties between the policy update and the representation. textcolor{blue}{First}, we establish a few key observations that frame the study: \textbf{(i)} Global convergence can be achieved under linear function approximation without policy or reward realizability, both for the standard Softmax PG and natural policy gradient (NPG). \textbf{(ii)} Approximation error is not a key quantity for characterizing global convergence in either algorithm. \textbf{(iii)} The conditions on the representation that imply global convergence are different between these two algorithms. Overall, these observations call into question approximation error as an appropriate quantity for characterizing the global convergence of PG methods under linear function approximation. \textcolor{blue}{Second}, motivated by these observations, we establish new general results: \textbf{(i)} NPG with linear function approximation achieves global convergence \emph{if and only if} the projection of the reward onto the representable space preserves the optimal action's rank, a quantity that is not strongly related to approximation error. \textbf{(ii)} The global convergence of Softmax PG occurs if the representation satisfies a non-domination condition and can preserve the ranking of rewards, which goes well beyond policy or reward realizability. We provide experimental results to support these theoretical findings.
Small steps no more: Global convergence of stochastic gradient bandits for arbitrary learning rates
Feb 11, 2025

We provide a new understanding of the stochastic gradient bandit algorithm by showing that it converges to a globally optimal policy almost surely using \emph{any} constant learning rate. This result demonstrates that the stochastic gradient algorithm continues to balance exploration and exploitation appropriately even in scenarios where standard smoothness and noise control assumptions break down. The proofs are based on novel findings about action sampling rates and the relationship between cumulative progress and noise, and extend the current understanding of how simple stochastic gradient methods behave in bandit settings.
Stochastic Gradient Succeeds for Bandits
Feb 27, 2024



We show that the \emph{stochastic gradient} bandit algorithm converges to a \emph{globally optimal} policy at an $O(1/t)$ rate, even with a \emph{constant} step size. Remarkably, global convergence of the stochastic gradient bandit algorithm has not been previously established, even though it is an old algorithm known to be applicable to bandits. The new result is achieved by establishing two novel technical findings: first, the noise of the stochastic updates in the gradient bandit algorithm satisfies a strong ``growth condition'' property, where the variance diminishes whenever progress becomes small, implying that additional noise control via diminishing step sizes is unnecessary; second, a form of ``weak exploration'' is automatically achieved through the stochastic gradient updates, since they prevent the action probabilities from decaying faster than $O(1/t)$, thus ensuring that every action is sampled infinitely often with probability $1$. These two findings can be used to show that the stochastic gradient update is already ``sufficient'' for bandits in the sense that exploration versus exploitation is automatically balanced in a manner that ensures almost sure convergence to a global optimum. These novel theoretical findings are further verified by experimental results.
Sample Efficient Deep Reinforcement Learning via Local Planning
Jan 29, 2023



The focus of this work is sample-efficient deep reinforcement learning (RL) with a simulator. One useful property of simulators is that it is typically easy to reset the environment to a previously observed state. We propose an algorithmic framework, named uncertainty-first local planning (UFLP), that takes advantage of this property. Concretely, in each data collection iteration, with some probability, our meta-algorithm resets the environment to an observed state which has high uncertainty, instead of sampling according to the initial-state distribution. The agent-environment interaction then proceeds as in the standard online RL setting. We demonstrate that this simple procedure can dramatically improve the sample cost of several baseline RL algorithms on difficult exploration tasks. Notably, with our framework, we can achieve super-human performance on the notoriously hard Atari game, Montezuma's Revenge, with a simple (distributional) double DQN. Our work can be seen as an efficient approximate implementation of an existing algorithm with theoretical guarantees, which offers an interpretation of the positive empirical results.
The Role of Baselines in Policy Gradient Optimization
Jan 16, 2023We study the effect of baselines in on-policy stochastic policy gradient optimization, and close the gap between the theory and practice of policy optimization methods. Our first contribution is to show that the \emph{state value} baseline allows on-policy stochastic \emph{natural} policy gradient (NPG) to converge to a globally optimal policy at an $O(1/t)$ rate, which was not previously known. The analysis relies on two novel findings: the expected progress of the NPG update satisfies a stochastic version of the non-uniform \L{}ojasiewicz (N\L{}) inequality, and with probability 1 the state value baseline prevents the optimal action's probability from vanishing, thus ensuring sufficient exploration. Importantly, these results provide a new understanding of the role of baselines in stochastic policy gradient: by showing that the variance of natural policy gradient estimates remains unbounded with or without a baseline, we find that variance reduction \emph{cannot} explain their utility in this setting. Instead, the analysis reveals that the primary effect of the value baseline is to \textbf{reduce the aggressiveness of the updates} rather than their variance. That is, we demonstrate that a finite variance is \emph{not necessary} for almost sure convergence of stochastic NPG, while controlling update aggressiveness is both necessary and sufficient. Additional experimental results verify these theoretical findings.
Optimistic MLE -- A Generic Model-based Algorithm for Partially Observable Sequential Decision Making
Sep 29, 2022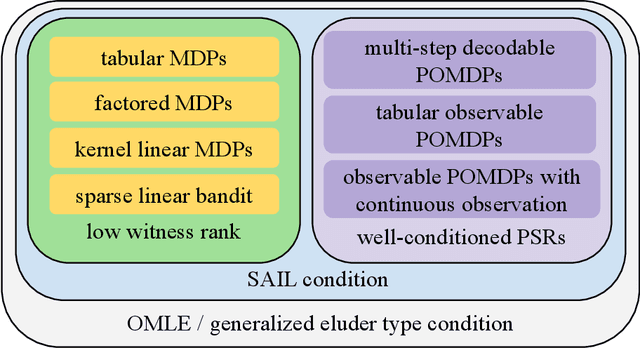
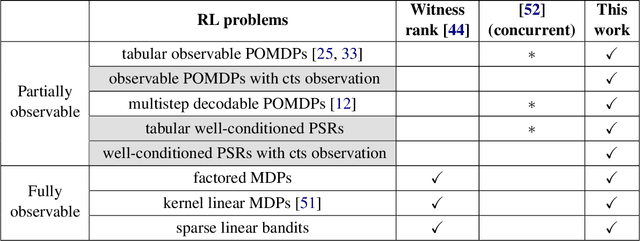
This paper introduces a simple efficient learning algorithms for general sequential decision making. The algorithm combines Optimism for exploration with Maximum Likelihood Estimation for model estimation, which is thus named OMLE. We prove that OMLE learns the near-optimal policies of an enormously rich class of sequential decision making problems in a polynomial number of samples. This rich class includes not only a majority of known tractable model-based Reinforcement Learning (RL) problems (such as tabular MDPs, factored MDPs, low witness rank problems, tabular weakly-revealing/observable POMDPs and multi-step decodable POMDPs), but also many new challenging RL problems especially in the partially observable setting that were not previously known to be tractable. Notably, the new problems addressed by this paper include (1) observable POMDPs with continuous observation and function approximation, where we achieve the first sample complexity that is completely independent of the size of observation space; (2) well-conditioned low-rank sequential decision making problems (also known as Predictive State Representations (PSRs)), which include and generalize all known tractable POMDP examples under a more intrinsic representation; (3) general sequential decision making problems under SAIL condition, which unifies our existing understandings of model-based RL in both fully observable and partially observable settings. SAIL condition is identified by this paper, which can be viewed as a natural generalization of Bellman/witness rank to address partial observability.
Towards Painless Policy Optimization for Constrained MDPs
Apr 11, 2022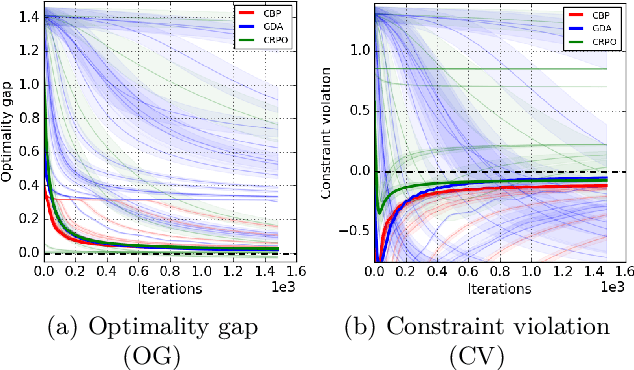

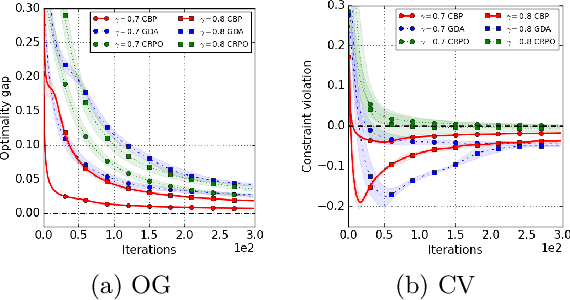
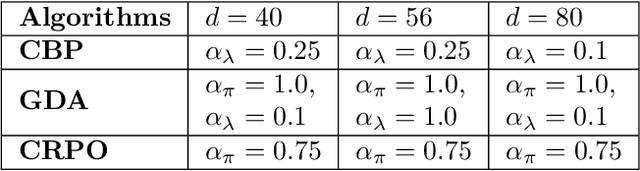
We study policy optimization in an infinite horizon, $\gamma$-discounted constrained Markov decision process (CMDP). Our objective is to return a policy that achieves large expected reward with a small constraint violation. We consider the online setting with linear function approximation and assume global access to the corresponding features. We propose a generic primal-dual framework that allows us to bound the reward sub-optimality and constraint violation for arbitrary algorithms in terms of their primal and dual regret on online linear optimization problems. We instantiate this framework to use coin-betting algorithms and propose the Coin Betting Politex (CBP) algorithm. Assuming that the action-value functions are $\varepsilon_b$-close to the span of the $d$-dimensional state-action features and no sampling errors, we prove that $T$ iterations of CBP result in an $O\left(\frac{1}{(1 - \gamma)^3 \sqrt{T}} + \frac{\varepsilon_b\sqrt{d}}{(1 - \gamma)^2} \right)$ reward sub-optimality and an $O\left(\frac{1}{(1 - \gamma)^2 \sqrt{T}} + \frac{\varepsilon_b \sqrt{d}}{1 - \gamma} \right)$ constraint violation. Importantly, unlike gradient descent-ascent and other recent methods, CBP does not require extensive hyperparameter tuning. Via experiments on synthetic and Cartpole environments, we demonstrate the effectiveness and robustness of CBP.
Understanding the Effect of Stochasticity in Policy Optimization
Oct 29, 2021

We study the effect of stochasticity in on-policy policy optimization, and make the following four contributions. First, we show that the preferability of optimization methods depends critically on whether stochastic versus exact gradients are used. In particular, unlike the true gradient setting, geometric information cannot be easily exploited in the stochastic case for accelerating policy optimization without detrimental consequences or impractical assumptions. Second, to explain these findings we introduce the concept of committal rate for stochastic policy optimization, and show that this can serve as a criterion for determining almost sure convergence to global optimality. Third, we show that in the absence of external oracle information, which allows an algorithm to determine the difference between optimal and sub-optimal actions given only on-policy samples, there is an inherent trade-off between exploiting geometry to accelerate convergence versus achieving optimality almost surely. That is, an uninformed algorithm either converges to a globally optimal policy with probability $1$ but at a rate no better than $O(1/t)$, or it achieves faster than $O(1/t)$ convergence but then must fail to converge to the globally optimal policy with some positive probability. Finally, we use the committal rate theory to explain why practical policy optimization methods are sensitive to random initialization, then develop an ensemble method that can be guaranteed to achieve near-optimal solutions with high probability.