 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Matters for Simulation to Online Reinforcement Learning on Real Robots
Feb 23, 2026We investigate what specific design choices enable successful online reinforcement learning (RL) on physical robots. Across 100 real-world training runs on three distinct robotic platforms, we systematically ablate algorithmic, systems, and experimental decisions that are typically left implicit in prior work. We find that some widely used defaults can be harmful, while a set of robust, readily adopted design choices within standard RL practice yield stable learning across tasks and hardware. These results provide the first large-sample empirical study of such design choices, enabling practitioners to deploy online RL with lower engineering effort.
A KL-regularization framework for learning to plan with adaptive priors
Oct 05, 2025Effective exploration remains a central challenge in model-based reinforcement learning (MBRL), particularly in high-dimensional continuous control tasks where sample efficiency is crucial. A prominent line of recent work leverages learned policies as proposal distributions for Model-Predictive Path Integral (MPPI) planning. Initial approaches update the sampling policy independently of the planner distribution, typically maximizing a learned value function with deterministic policy gradient and entropy regularization. However, because the states encountered during training depend on the MPPI planner, aligning the sampling policy with the planner improves the accuracy of value estimation and long-term performance. To this end, recent methods update the sampling policy by minimizing KL divergence to the planner distribution or by introducing planner-guided regularization into the policy update. In this work, we unify these MPPI-based reinforcement learning methods under a single framework by introducing Policy Optimization-Model Predictive Control (PO-MPC), a family of KL-regularized MBRL methods that integrate the planner's action distribution as a prior in policy optimization. By aligning the learned policy with the planner's behavior, PO-MPC allows more flexibility in the policy updates to trade off Return maximization and KL divergence minimization. We clarify how prior approaches emerge as special cases of this family, and we explore previously unstudied variations. Our experiments show that these extended configurations yield significant performance improvements, advancing the state of the art in MPPI-based RL.
Learning Robot Soccer from Egocentric Vision with Deep Reinforcement Learning
May 03, 2024



We apply multi-agent deep reinforcement learning (RL) to train end-to-end robot soccer policies with fully onboard computation and sensing via egocentric RGB vision. This setting reflects many challenges of real-world robotics, including active perception, agile full-body control, and long-horizon planning in a dynamic, partially-observable, multi-agent domain. We rely on large-scale, simulation-based data generation to obtain complex behaviors from egocentric vision which can be successfully transferred to physical robots using low-cost sensors. To achieve adequate visual realism, our simulation combines rigid-body physics with learned, realistic rendering via multiple Neural Radiance Fields (NeRFs). We combine teacher-based multi-agent RL and cross-experiment data reuse to enable the discovery of sophisticated soccer strategies. We analyze active-perception behaviors including object tracking and ball seeking that emerge when simply optimizing perception-agnostic soccer play. The agents display equivalent levels of performance and agility as policies with access to privileged, ground-truth state. To our knowledge, this paper constitutes a first demonstration of end-to-end training for multi-agent robot soccer, mapping raw pixel observations to joint-level actions, that can be deployed in the real world. Videos of the game-play and analyses can be seen on our website https://sites.google.com/view/vision-soccer .
Replay across Experiments: A Natural Extension of Off-Policy RL
Nov 28, 2023



Replaying data is a principal mechanism underlying the stability and data efficiency of off-policy reinforcement learning (RL). We present an effective yet simple framework to extend the use of replays across multiple experiments, minimally adapting the RL workflow for sizeable improvements in controller performance and research iteration times. At its core, Replay Across Experiments (RaE) involves reusing experience from previous experiments to improve exploration and bootstrap learning while reducing required changes to a minimum in comparison to prior work. We empirically show benefits across a number of RL algorithms and challenging control domains spanning both locomotion and manipulation, including hard exploration tasks from egocentric vision. Through comprehensive ablations, we demonstrate robustness to the quality and amount of data available and various hyperparameter choices. Finally, we discuss how our approach can be applied more broadly across research life cycles and can increase resilience by reloading data across random seeds or hyperparameter variations.
Learning Agile Soccer Skills for a Bipedal Robot with Deep Reinforcement Learning
Apr 26, 2023We investigate whether Deep Reinforcement Learning (Deep RL) is able to synthesize sophisticated and safe movement skills for a low-cost, miniature humanoid robot that can be composed into complex behavioral strategies in dynamic environments. We used Deep RL to train a humanoid robot with 20 actuated joints to play a simplified one-versus-one (1v1) soccer game. We first trained individual skills in isolation and then composed those skills end-to-end in a self-play setting. The resulting policy exhibits robust and dynamic movement skills such as rapid fall recovery, walking, turning, kicking and more; and transitions between them in a smooth, stable, and efficient manner - well beyond what is intuitively expected from the robot. The agents also developed a basic strategic understanding of the game, and learned, for instance, to anticipate ball movements and to block opponent shots. The full range of behaviors emerged from a small set of simple rewards. Our agents were trained in simulation and transferred to real robots zero-shot. We found that a combination of sufficiently high-frequency control, targeted dynamics randomization, and perturbations during training in simulation enabled good-quality transfer, despite significant unmodeled effects and variations across robot instances. Although the robots are inherently fragile, minor hardware modifications together with basic regularization of the behavior during training led the robots to learn safe and effective movements while still performing in a dynamic and agile way. Indeed, even though the agents were optimized for scoring, in experiments they walked 156% faster, took 63% less time to get up, and kicked 24% faster than a scripted baseline, while efficiently combining the skills to achieve the longer term objectives. Examples of the emergent behaviors and full 1v1 matches are available on the supplementary website.
SkillS: Adaptive Skill Sequencing for Efficient Temporally-Extended Exploration
Dec 03, 2022



The ability to effectively reuse prior knowledge is a key requirement when building general and flexible Reinforcement Learning (RL) agents. Skill reuse is one of the most common approaches, but current methods have considerable limitations.For example, fine-tuning an existing policy frequently fails, as the policy can degrade rapidly early in training. In a similar vein, distillation of expert behavior can lead to poor results when given sub-optimal experts. We compare several common approaches for skill transfer on multiple domains including changes in task and system dynamics. We identify how existing methods can fail and introduce an alternative approach to mitigate these problems. Our approach learns to sequence existing temporally-extended skills for exploration but learns the final policy directly from the raw experience. This conceptual split enables rapid adaptation and thus efficient data collection but without constraining the final solution.It significantly outperforms many classical methods across a suite of evaluation tasks and we use a broad set of ablations to highlight the importance of differentc omponents of our method.
MO2: Model-Based Offline Options
Sep 05, 2022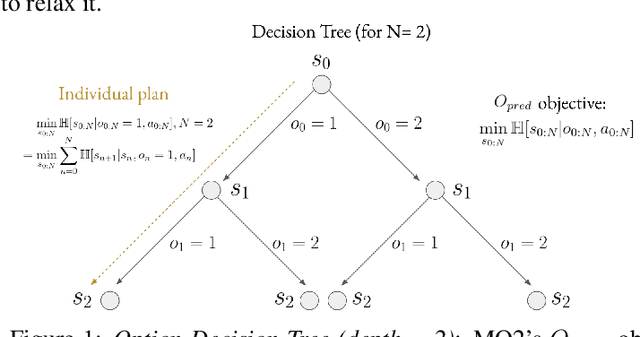

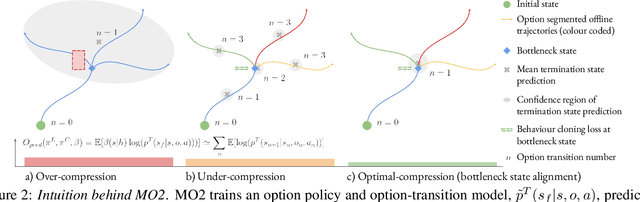
The ability to discover useful behaviours from past experience and transfer them to new tasks is considered a core component of natural embodied intelligence. Inspired by neuroscience, discovering behaviours that switch at bottleneck states have been long sought after for inducing plans of minimum description length across tasks. Prior approaches have either only supported online, on-policy, bottleneck state discovery, limiting sample-efficiency, or discrete state-action domains, restricting applicability. To address this, we introduce Model-Based Offline Options (MO2), an offline hindsight framework supporting sample-efficient bottleneck option discovery over continuous state-action spaces. Once bottleneck options are learnt offline over source domains, they are transferred online to improve exploration and value estimation on the transfer domain. Our experiments show that on complex long-horizon continuous control tasks with sparse, delayed rewards, MO2's properties are essential and lead to performance exceeding recent option learning methods. Additional ablations further demonstrate the impact on option predictability and credit assignment.
Learning Transferable Motor Skills with Hierarchical Latent Mixture Policies
Dec 09, 2021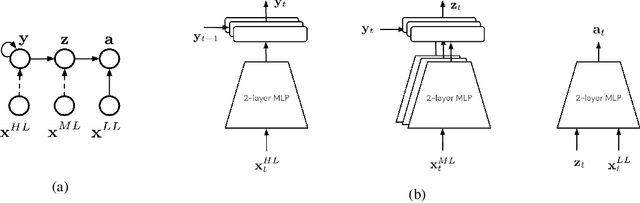
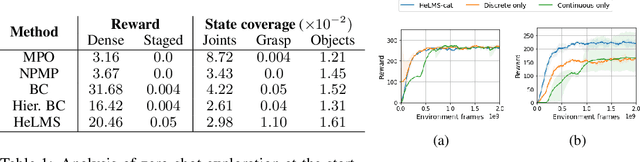
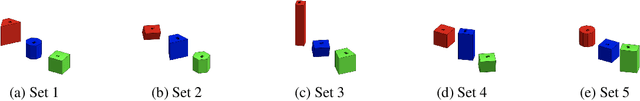
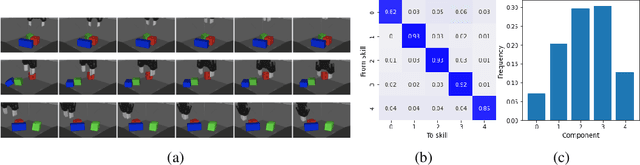
For robots operating in the real world, it is desirable to learn reusable behaviours that can effectively be transferred and adapted to numerous tasks and scenarios. We propose an approach to learn abstract motor skills from data using a hierarchical mixture latent variable model. In contrast to existing work, our method exploits a three-level hierarchy of both discrete and continuous latent variables, to capture a set of high-level behaviours while allowing for variance in how they are executed. We demonstrate in manipulation domains that the method can effectively cluster offline data into distinct, executable behaviours, while retaining the flexibility of a continuous latent variable model. The resulting skills can be transferred and fine-tuned on new tasks, unseen objects, and from state to vision-based policies, yielding better sample efficiency and asymptotic performance compared to existing skill- and imitation-based methods. We further analyse how and when the skills are most beneficial: they encourage directed exploration to cover large regions of the state space relevant to the task, making them most effective in challenging sparse-reward settings.
Pick Your Battles: Interaction Graphs as Population-Level Objectives for Strategic Diversity
Oct 08, 2021Strategic diversity is often essential in games: in multi-player games, for example, evaluating a player against a diverse set of strategies will yield a more accurate estimate of its performance. Furthermore, in games with non-transitivities diversity allows a player to cover several winning strategies. However, despite the significance of strategic diversity, training agents that exhibit diverse behaviour remains a challenge. In this paper we study how to construct diverse populations of agents by carefully structuring how individuals within a population interact. Our approach is based on interaction graphs, which control the flow of information between agents during training and can encourage agents to specialise on different strategies, leading to improved overall performance. We provide evidence for the importance of diversity in multi-agent training and analyse the effect of applying different interaction graphs on the training trajectories, diversity and performance of populations in a range of games. This is an extended version of the long abstract published at AAMAS.
Behavior Priors for Efficient Reinforcement Learning
Oct 27, 2020
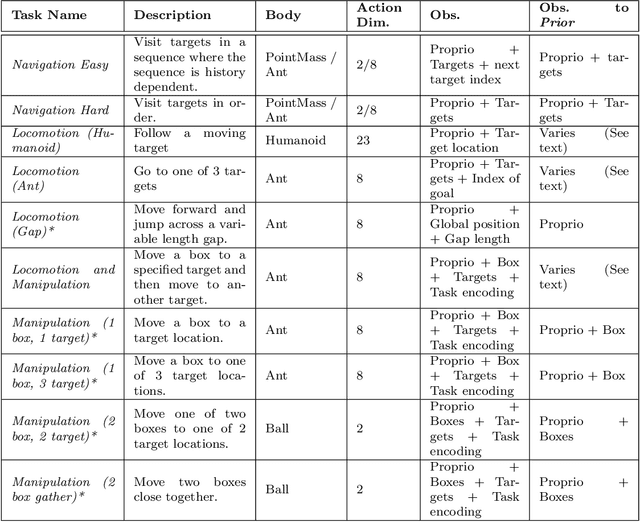
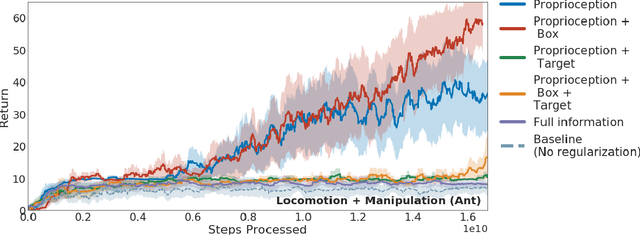

As we deploy reinforcement learning agents to solve increasingly challenging problems, methods that allow us to inject prior knowledge about the structure of the world and effective solution strategies becomes increasingly important. In this work we consider how information and architectural constraints can be combined with ideas from the probabilistic modeling literature to learn behavior priors that capture the common movement and interaction patterns that are shared across a set of related tasks or contexts. For example the day-to day behavior of humans comprises distinctive locomotion and manipulation patterns that recur across many different situations and goals. We discuss how such behavior patterns can be captured using probabilistic trajectory models and how these can be integrated effectively into reinforcement learning schemes, e.g.\ to facilitate multi-task and transfer learning. We then extend these ideas to latent variable models and consider a formulation to learn hierarchical priors that capture different aspects of the behavior in reusable modules. We discuss how such latent variable formulations connect to related work on hierarchical reinforcement learning (HRL) and mutual information and curiosity based objectives, thereby offering an alternative perspective on existing ideas. We demonstrate the effectiveness of our framework by applying it to a range of simulated continuous control domains.