 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Optimization of Traffic Signal Control and Vehicle Routing in Signalized Road Networks using Multi-Agent Deep Reinforcement Learning
Oct 16, 2023



Urban traffic congestion is a critical predicament that plagues modern road networks. To alleviate this issue and enhance traffic efficiency, traffic signal control and vehicle routing have proven to be effective measures. In this paper, we propose a joint optimization approach for traffic signal control and vehicle routing in signalized road networks. The objective is to enhance network performance by simultaneously controlling signal timings and route choices using Multi-Agent Deep Reinforcement Learning (MADRL). Signal control agents (SAs) are employed to establish signal timings at intersections, whereas vehicle routing agents (RAs) are responsible for selecting vehicle routes. By establishing relevance between agents and enabling them to share observations and rewards, interaction and cooperation among agents are fostered, which enhances individual training. The Multi-Agent Advantage Actor-Critic algorithm is used to handle multi-agent environments, and Deep Neural Network (DNN) structures are designed to facilitate the algorithm's convergence. Notably, our work is the first to utilize MADRL in determining the optimal joint policy for signal control and vehicle routing. Numerical experiments conducted on the modified Sioux network demonstrate that our integration of signal control and vehicle routing outperforms controlling signal timings or vehicles' routes alone in enhancing traffic efficiency.
EVKG: An Interlinked and Interoperable Electric Vehicle Knowledge Graph for Smart Transportation System
Apr 10, 2023Over the past decade, the electric vehicle industry has experienced unprecedented growth and diversification, resulting in a complex ecosystem. To effectively manage this multifaceted field, we present an EV-centric knowledge graph (EVKG) as a comprehensive, cross-domain, extensible, and open geospatial knowledge management system. The EVKG encapsulates essential EV-related knowledge, including EV adoption, electric vehicle supply equipment, and electricity transmission network, to support decision-making related to EV technology development, infrastructure planning, and policy-making by providing timely and accurate information and analysis. To enrich and contextualize the EVKG, we integrate the developed EV-relevant ontology modules from existing well-known knowledge graphs and ontologies. This integration enables interoperability with other knowledge graphs in the Linked Data Open Cloud, enhancing the EVKG's value as a knowledge hub for EV decision-making. Using six competency questions, we demonstrate how the EVKG can be used to answer various types of EV-related questions, providing critical insights into the EV ecosystem. Our EVKG provides an efficient and effective approach for managing the complex and diverse EV industry. By consolidating critical EV-related knowledge into a single, easily accessible resource, the EVKG supports decision-makers in making informed choices about EV technology development, infrastructure planning, and policy-making. As a flexible and extensible platform, the EVKG is capable of accommodating a wide range of data sources, enabling it to evolve alongside the rapidly changing EV landscape.
Effectively Modeling Time Series with Simple Discrete State Spaces
Mar 16, 2023



Time series modeling is a well-established problem, which often requires that methods (1) expressively represent complicated dependencies, (2) forecast long horizons, and (3) efficiently train over long sequences. State-space models (SSMs) are classical models for time series, and prior works combine SSMs with deep learning layers for efficient sequence modeling. However, we find fundamental limitations with these prior approaches, proving their SSM representations cannot express autoregressive time series processes. We thus introduce SpaceTime, a new state-space time series architecture that improves all three criteria. For expressivity, we propose a new SSM parameterization based on the companion matrix -- a canonical representation for discrete-time processes -- which enables SpaceTime's SSM layers to learn desirable autoregressive processes. For long horizon forecasting, we introduce a "closed-loop" variation of the companion SSM, which enables SpaceTime to predict many future time-steps by generating its own layer-wise inputs. For efficient training and inference, we introduce an algorithm that reduces the memory and compute of a forward pass with the companion matrix. With sequence length $\ell$ and state-space size $d$, we go from $\tilde{O}(d \ell)$ na\"ively to $\tilde{O}(d + \ell)$. In experiments, our contributions lead to state-of-the-art results on extensive and diverse benchmarks, with best or second-best AUROC on 6 / 7 ECG and speech time series classification, and best MSE on 14 / 16 Informer forecasting tasks. Furthermore, we find SpaceTime (1) fits AR($p$) processes that prior deep SSMs fail on, (2) forecasts notably more accurately on longer horizons than prior state-of-the-art, and (3) speeds up training on real-world ETTh1 data by 73% and 80% relative wall-clock time over Transformers and LSTMs.
Simple Hardware-Efficient Long Convolutions for Sequence Modeling
Feb 13, 2023State space models (SSMs) have high performance on long sequence modeling but require sophisticated initialization techniques and specialized implementations for high quality and runtime performance. We study whether a simple alternative can match SSMs in performance and efficiency: directly learning long convolutions over the sequence. We find that a key requirement to achieving high performance is keeping the convolution kernels smooth. We find that simple interventions--such as squashing the kernel weights--result in smooth kernels and recover SSM performance on a range of tasks including the long range arena, image classification, language modeling, and brain data modeling. Next, we develop FlashButterfly, an IO-aware algorithm to improve the runtime performance of long convolutions. FlashButterfly appeals to classic Butterfly decompositions of the convolution to reduce GPU memory IO and increase FLOP utilization. FlashButterfly speeds up convolutions by 2.2$\times$, and allows us to train on Path256, a challenging task with sequence length 64K, where we set state-of-the-art by 29.1 points while training 7.2$\times$ faster than prior work. Lastly, we introduce an extension to FlashButterfly that learns the coefficients of the Butterfly decomposition, increasing expressivity without increasing runtime. Using this extension, we outperform a Transformer on WikiText103 by 0.2 PPL with 30% fewer parameters.
Contrastive Adapters for Foundation Model Group Robustness
Jul 14, 2022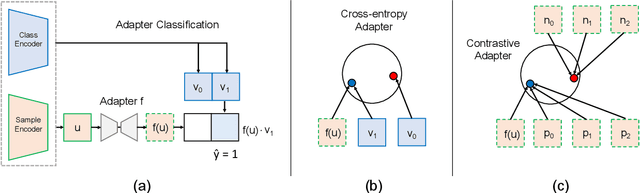


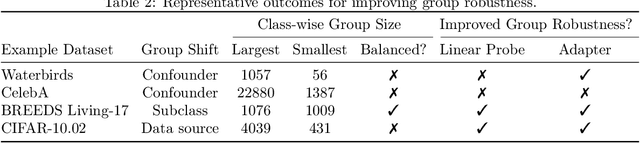
While large pretrained foundation models (FMs) have shown remarkable zero-shot classification robustness to dataset-level distribution shifts, their robustness to subpopulation or group shifts is relatively underexplored. We study this problem, and find that FMs such as CLIP may not be robust to various group shifts. Across 9 robustness benchmarks, zero-shot classification with their embeddings results in gaps of up to 80.7 percentage points (pp) between average and worst-group accuracy. Unfortunately, existing methods to improve robustness require retraining, which can be prohibitively expensive on large foundation models. We also find that efficient ways to improve model inference (e.g., via adapters, lightweight networks with FM embeddings as inputs) do not consistently improve and can sometimes hurt group robustness compared to zero-shot (e.g., increasing the accuracy gap by 50.1 pp on CelebA). We thus develop an adapter training strategy to effectively and efficiently improve FM group robustness. Our motivating observation is that while poor robustness results from groups in the same class being embedded far apart in the foundation model "embedding space," standard adapter training may not bring these points closer together. We thus propose contrastive adapting, which trains adapters with contrastive learning to bring sample embeddings close to both their ground-truth class embeddings and other sample embeddings in the same class. Across the 9 benchmarks, our approach consistently improves group robustness, raising worst-group accuracy by 8.5 to 56.0 pp over zero-shot. Our approach is also efficient, doing so without any FM finetuning and only a fixed set of frozen FM embeddings. On benchmarks such as Waterbirds and CelebA, this leads to worst-group accuracy comparable to state-of-the-art methods that retrain entire models, while only training $\leq$1% of the model parameters.
Deep Learning and Symbolic Regression for Discovering Parametric Equations
Jul 01, 2022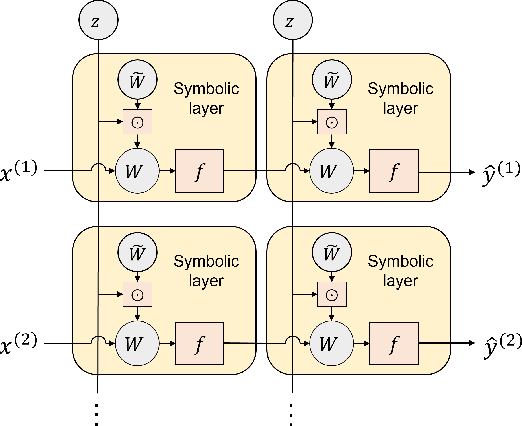
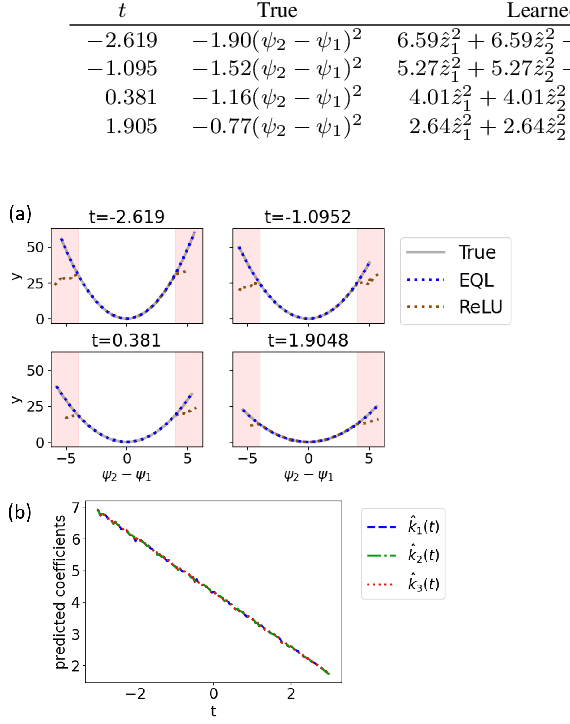
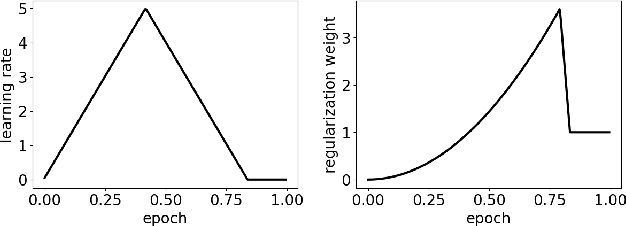
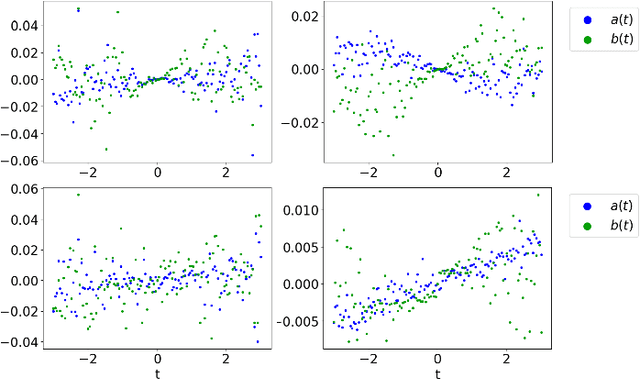
Symbolic regression is a machine learning technique that can learn the governing formulas of data and thus has the potential to transform scientific discovery. However, symbolic regression is still limited in the complexity and dimensionality of the systems that it can analyze. Deep learning on the other hand has transformed machine learning in its ability to analyze extremely complex and high-dimensional datasets. We propose a neural network architecture to extend symbolic regression to parametric systems where some coefficient may vary but the structure of the underlying governing equation remains constant. We demonstrate our method on various analytic expressions, ODEs, and PDEs with varying coefficients and show that it extrapolates well outside of the training domain. The neural network-based architecture can also integrate with other deep learning architectures so that it can analyze high-dimensional data while being trained end-to-end. To this end we integrate our architecture with convolutional neural networks to analyze 1D images of varying spring systems.
Perfectly Balanced: Improving Transfer and Robustness of Supervised Contrastive Learning
Apr 15, 2022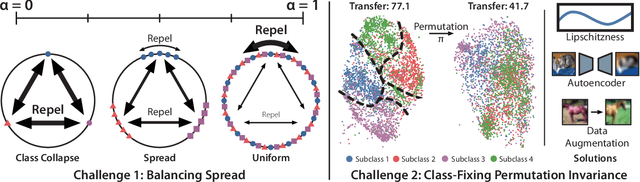

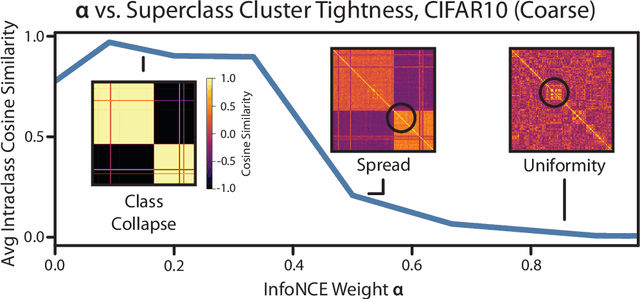
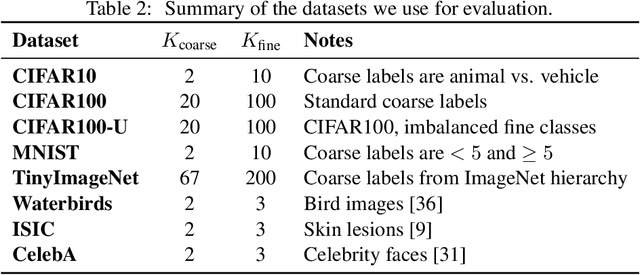
An ideal learned representation should display transferability and robustness. Supervised contrastive learning (SupCon) is a promising method for training accurate models, but produces representations that do not capture these properties due to class collapse -- when all points in a class map to the same representation. Recent work suggests that "spreading out" these representations improves them, but the precise mechanism is poorly understood. We argue that creating spread alone is insufficient for better representations, since spread is invariant to permutations within classes. Instead, both the correct degree of spread and a mechanism for breaking this invariance are necessary. We first prove that adding a weighted class-conditional InfoNCE loss to SupCon controls the degree of spread. Next, we study three mechanisms to break permutation invariance: using a constrained encoder, adding a class-conditional autoencoder, and using data augmentation. We show that the latter two encourage clustering of latent subclasses under more realistic conditions than the former. Using these insights, we show that adding a properly-weighted class-conditional InfoNCE loss and a class-conditional autoencoder to SupCon achieves 11.1 points of lift on coarse-to-fine transfer across 5 standard datasets and 4.7 points on worst-group robustness on 3 datasets, setting state-of-the-art on CelebA by 11.5 points.
Shoring Up the Foundations: Fusing Model Embeddings and Weak Supervision
Mar 24, 2022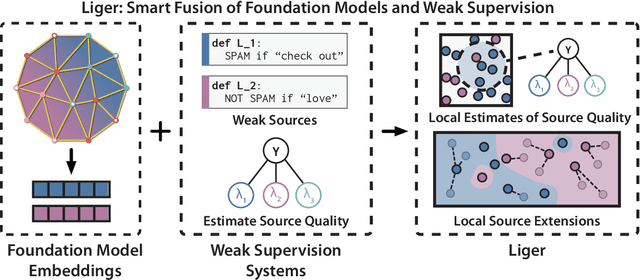
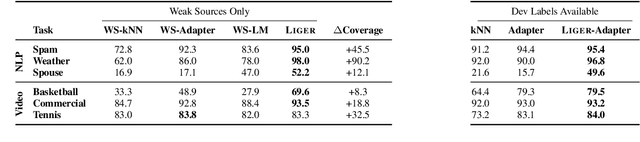
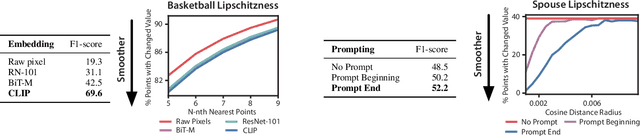
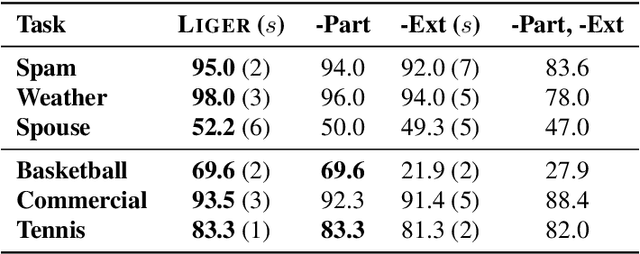
Foundation models offer an exciting new paradigm for constructing models with out-of-the-box embeddings and a few labeled examples. However, it is not clear how to best apply foundation models without labeled data. A potential approach is to fuse foundation models with weak supervision frameworks, which use weak label sources -- pre-trained models, heuristics, crowd-workers -- to construct pseudolabels. The challenge is building a combination that best exploits the signal available in both foundation models and weak sources. We propose Liger, a combination that uses foundation model embeddings to improve two crucial elements of existing weak supervision techniques. First, we produce finer estimates of weak source quality by partitioning the embedding space and learning per-part source accuracies. Second, we improve source coverage by extending source votes in embedding space. Despite the black-box nature of foundation models, we prove results characterizing how our approach improves performance and show that lift scales with the smoothness of label distributions in embedding space. On six benchmark NLP and video tasks, Liger outperforms vanilla weak supervision by 14.1 points, weakly-supervised kNN and adapters by 11.8 points, and kNN and adapters supervised by traditional hand labels by 7.2 points.
Triangle and Four Cycle Counting with Predictions in Graph Streams
Mar 17, 2022
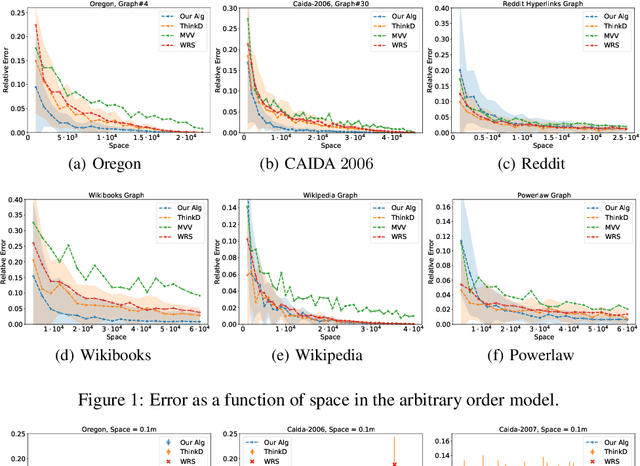
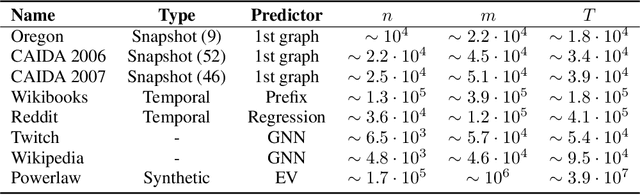
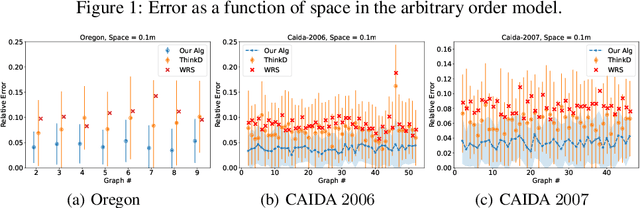
We propose data-driven one-pass streaming algorithms for estimating the number of triangles and four cycles, two fundamental problems in graph analytics that are widely studied in the graph data stream literature. Recently, (Hsu 2018) and (Jiang 2020) applied machine learning techniques in other data stream problems, using a trained oracle that can predict certain properties of the stream elements to improve on prior "classical" algorithms that did not use oracles. In this paper, we explore the power of a "heavy edge" oracle in multiple graph edge streaming models. In the adjacency list model, we present a one-pass triangle counting algorithm improving upon the previous space upper bounds without such an oracle. In the arbitrary order model, we present algorithms for both triangle and four cycle estimation with fewer passes and the same space complexity as in previous algorithms, and we show several of these bounds are optimal. We analyze our algorithms under several noise models, showing that the algorithms perform well even when the oracle errs. Our methodology expands upon prior work on "classical" streaming algorithms, as previous multi-pass and random order streaming algorithms can be seen as special cases of our algorithms, where the first pass or random order was used to implement the heavy edge oracle. Lastly, our experiments demonstrate advantages of the proposed method compared to state-of-the-art streaming algorithms.
Correct-N-Contrast: A Contrastive Approach for Improving Robustness to Spurious Correlations
Mar 03, 2022
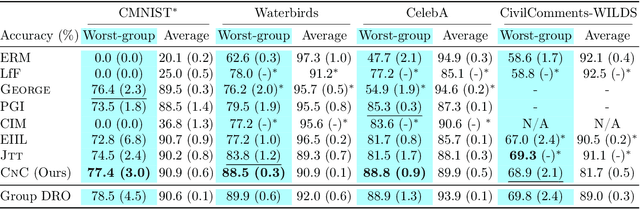

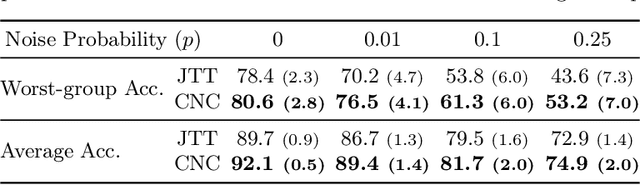
Spurious correlations pose a major challenge for robust machine learning. Models trained with empirical risk minimization (ERM) may learn to rely on correlations between class labels and spurious attributes, leading to poor performance on data groups without these correlations. This is particularly challenging to address when spurious attribute labels are unavailable. To improve worst-group performance on spuriously correlated data without training attribute labels, we propose Correct-N-Contrast (CNC), a contrastive approach to directly learn representations robust to spurious correlations. As ERM models can be good spurious attribute predictors, CNC works by (1) using a trained ERM model's outputs to identify samples with the same class but dissimilar spurious features, and (2) training a robust model with contrastive learning to learn similar representations for same-class samples. To support CNC, we introduce new connections between worst-group error and a representation alignment loss that CNC aims to minimize. We empirically observe that worst-group error closely tracks with alignment loss, and prove that the alignment loss over a class helps upper-bound the class's worst-group vs. average error gap. On popular benchmarks, CNC reduces alignment loss drastically, and achieves state-of-the-art worst-group accuracy by 3.6% average absolute lift. CNC is also competitive with oracle methods that require group labels.