 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacterizing Policy Divergence for Personalized Meta-Reinforcement Learning
Paper and Code
Oct 09, 2020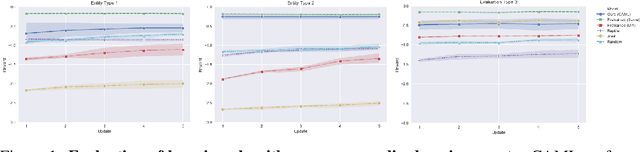
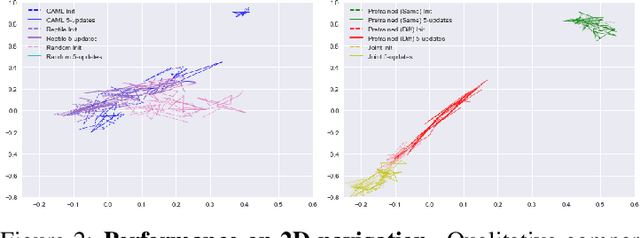
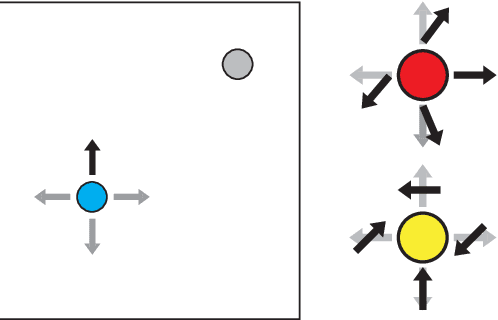
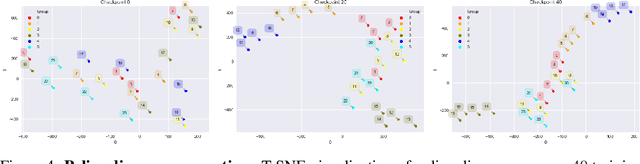
Despite ample motivation from costly exploration and limited trajectory data, rapidly adapting to new environments with few-shot reinforcement learning (RL) can remain a challenging task, especially with respect to personalized settings. Here, we consider the problem of recommending optimal policies to a set of multiple entities each with potentially different characteristics, such that individual entities may parameterize distinct environments with unique transition dynamics. Inspired by existing literature in meta-learning, we extend previous work by focusing on the notion that certain environments are more similar to each other than others in personalized settings, and propose a model-free meta-learning algorithm that prioritizes past experiences by relevance during gradient-based adaptation. Our algorithm involves characterizing past policy divergence through methods in inverse reinforcement learning, and we illustrate how such metrics are able to effectively distinguish past policy parameters by the environment they were deployed in, leading to more effective fast adaptation during test time. To study personalization more effectively we introduce a navigation testbed to specifically incorporate environment diversity across training episodes, and demonstrate that our approach outperforms meta-learning alternatives with respect to few-shot reinforcement learning in personalized settings.