 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePositional LSH: Binary Block Matrix Approximation for Attention with Linear Biases
May 10, 2026Positional encoding in transformers is commonly implemented through positional embeddings, attention masks, or bias terms, but formal connections between these mechanisms remain limited. We study attention with positional bias through the lens of locality-sensitive hashing (LSH), focusing on Attention with Linear Biases (ALiBi). We show that the ALiBi bias matrix is the expectation of contiguous block-diagonal binary masks induced by a ``positional LSH'' scheme. The empirical mean of masks sampled from this scheme yields spectral norm and max-norm approximation guarantees with bounded block sizes with high probability. This structural theorem implies a uniform approximation theorem for ALiBi-biased attention: with high probability over the sampled masks, the approximate attention output is accurate simultaneously for all query-key-value inputs and can be computed in near-linear time in the context length, reducing long-context ALiBi to a collection of randomized short-context regular (positionally unbiased) attention operations. Conceptually, this connects positional bias, masks, and positional embeddings in a single formal framework and suggests an approach to efficient ALiBi-biased attention. Experiments on large language models validate our theoretical findings.
Graph-based Nearest Neighbors with Dynamic Updates via Random Walks
Dec 19, 2025Approximate nearest neighbor search (ANN) is a common way to retrieve relevant search results, especially now in the context of large language models and retrieval augmented generation. One of the most widely used algorithms for ANN is based on constructing a multi-layer graph over the dataset, called the Hierarchical Navigable Small World (HNSW). While this algorithm supports insertion of new data, it does not support deletion of existing data. Moreover, deletion algorithms described by prior work come at the cost of increased query latency, decreased recall, or prolonged deletion time. In this paper, we propose a new theoretical framework for graph-based ANN based on random walks. We then utilize this framework to analyze a randomized deletion approach that preserves hitting time statistics compared to the graph before deleting the point. We then turn this theoretical framework into a deterministic deletion algorithm, and show that it provides better tradeoff between query latency, recall, deletion time, and memory usage through an extensive collection of experiments.
Learning from End User Data with Shuffled Differential Privacy over Kernel Densities
Feb 19, 2025We study a setting of collecting and learning from private data distributed across end users. In the shuffled model of differential privacy, the end users partially protect their data locally before sharing it, and their data is also anonymized during its collection to enhance privacy. This model has recently become a prominent alternative to central DP, which requires full trust in a central data curator, and local DP, where fully local data protection takes a steep toll on downstream accuracy. Our main technical result is a shuffled DP protocol for privately estimating the kernel density function of a distributed dataset, with accuracy essentially matching central DP. We use it to privately learn a classifier from the end user data, by learning a private density function per class. Moreover, we show that the density function itself can recover the semantic content of its class, despite having been learned in the absence of any unprotected data. Our experiments show the favorable downstream performance of our approach, and highlight key downstream considerations and trade-offs in a practical ML deployment of shuffled DP.
Private Text Generation by Seeding Large Language Model Prompts
Feb 18, 2025



We explore how private synthetic text can be generated by suitably prompting a large language model (LLM). This addresses a challenge for organizations like hospitals, which hold sensitive text data like patient medical records, and wish to share it in order to train machine learning models for medical tasks, while preserving patient privacy. Methods that rely on training or finetuning a model may be out of reach, either due to API limits of third-party LLMs, or due to ethical and legal prohibitions on sharing the private data with the LLM itself. We propose Differentially Private Keyphrase Prompt Seeding (DP-KPS), a method that generates a private synthetic text corpus from a sensitive input corpus, by accessing an LLM only through privatized prompts. It is based on seeding the prompts with private samples from a distribution over phrase embeddings, thus capturing the input corpus while achieving requisite output diversity and maintaining differential privacy. We evaluate DP-KPS on downstream ML text classification tasks, and show that the corpora it generates preserve much of the predictive power of the original ones. Our findings offer hope that institutions can reap ML insights by privately sharing data with simple prompts and little compute.
Fast Private Kernel Density Estimation via Locality Sensitive Quantization
Jul 04, 2023



We study efficient mechanisms for differentially private kernel density estimation (DP-KDE). Prior work for the Gaussian kernel described algorithms that run in time exponential in the number of dimensions $d$. This paper breaks the exponential barrier, and shows how the KDE can privately be approximated in time linear in $d$, making it feasible for high-dimensional data. We also present improved bounds for low-dimensional data. Our results are obtained through a general framework, which we term Locality Sensitive Quantization (LSQ), for constructing private KDE mechanisms where existing KDE approximation techniques can be applied. It lets us leverage several efficient non-private KDE methods -- like Random Fourier Features, the Fast Gauss Transform, and Locality Sensitive Hashing -- and ``privatize'' them in a black-box manner. Our experiments demonstrate that our resulting DP-KDE mechanisms are fast and accurate on large datasets in both high and low dimensions.
Learned Interpolation for Better Streaming Quantile Approximation with Worst-Case Guarantees
Apr 15, 2023



An $\varepsilon$-approximate quantile sketch over a stream of $n$ inputs approximates the rank of any query point $q$ - that is, the number of input points less than $q$ - up to an additive error of $\varepsilon n$, generally with some probability of at least $1 - 1/\mathrm{poly}(n)$, while consuming $o(n)$ space. While the celebrated KLL sketch of Karnin, Lang, and Liberty achieves a provably optimal quantile approximation algorithm over worst-case streams, the approximations it achieves in practice are often far from optimal. Indeed, the most commonly used technique in practice is Dunning's t-digest, which often achieves much better approximations than KLL on real-world data but is known to have arbitrarily large errors in the worst case. We apply interpolation techniques to the streaming quantiles problem to attempt to achieve better approximations on real-world data sets than KLL while maintaining similar guarantees in the worst case.
Exponentially Improving the Complexity of Simulating the Weisfeiler-Lehman Test with Graph Neural Networks
Nov 06, 2022



Recent work shows that the expressive power of Graph Neural Networks (GNNs) in distinguishing non-isomorphic graphs is exactly the same as that of the Weisfeiler-Lehman (WL) graph test. In particular, they show that the WL test can be simulated by GNNs. However, those simulations involve neural networks for the 'combine' function of size polynomial or even exponential in the number of graph nodes $n$, as well as feature vectors of length linear in $n$. We present an improved simulation of the WL test on GNNs with \emph{exponentially} lower complexity. In particular, the neural network implementing the combine function in each node has only a polylogarithmic number of parameters in $n$, and the feature vectors exchanged by the nodes of GNN consists of only $O(\log n)$ bits. We also give logarithmic lower bounds for the feature vector length and the size of the neural networks, showing the (near)-optimality of our construction.
Budget-Constrained Bounds for Mini-Batch Estimation of Optimal Transport
Oct 24, 2022



Optimal Transport (OT) is a fundamental tool for comparing probability distributions, but its exact computation remains prohibitive for large datasets. In this work, we introduce novel families of upper and lower bounds for the OT problem constructed by aggregating solutions of mini-batch OT problems. The upper bound family contains traditional mini-batch averaging at one extreme and a tight bound found by optimal coupling of mini-batches at the other. In between these extremes, we propose various methods to construct bounds based on a fixed computational budget. Through various experiments, we explore the trade-off between computational budget and bound tightness and show the usefulness of these bounds in computer vision applications.
Generalization Bounds for Data-Driven Numerical Linear Algebra
Jun 16, 2022Data-driven algorithms can adapt their internal structure or parameters to inputs from unknown application-specific distributions, by learning from a training sample of inputs. Several recent works have applied this approach to problems in numerical linear algebra, obtaining significant empirical gains in performance. However, no theoretical explanation for their success was known. In this work we prove generalization bounds for those algorithms, within the PAC-learning framework for data-driven algorithm selection proposed by Gupta and Roughgarden (SICOMP 2017). Our main results are closely matching upper and lower bounds on the fat shattering dimension of the learning-based low rank approximation algorithm of Indyk et al.~(NeurIPS 2019). Our techniques are general, and provide generalization bounds for many other recently proposed data-driven algorithms in numerical linear algebra, covering both sketching-based and multigrid-based methods. This considerably broadens the class of data-driven algorithms for which a PAC-learning analysis is available.
Unveiling Transformers with LEGO: a synthetic reasoning task
Jun 09, 2022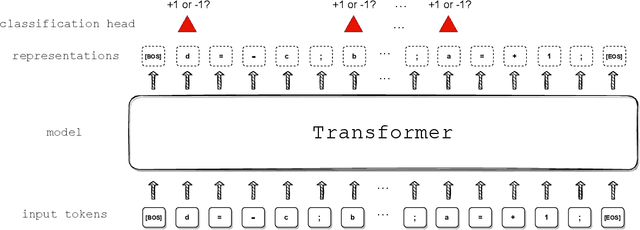
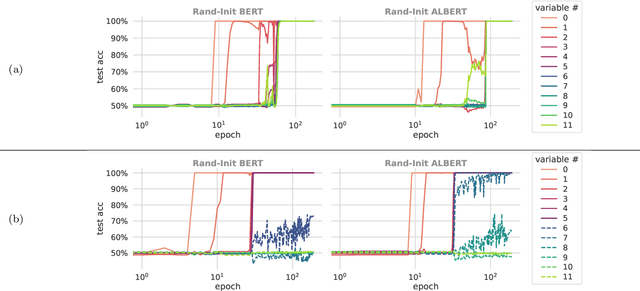
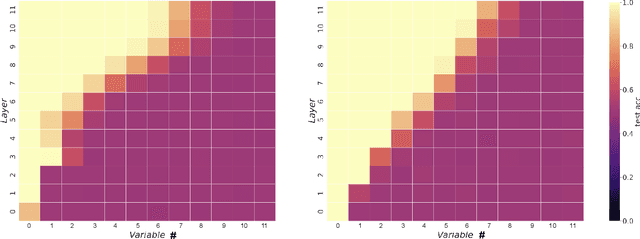
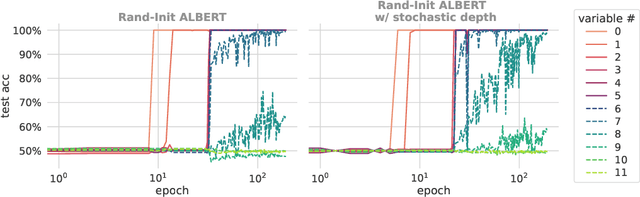
We propose a synthetic task, LEGO (Learning Equality and Group Operations), that encapsulates the problem of following a chain of reasoning, and we study how the transformer architecture learns this task. We pay special attention to data effects such as pretraining (on seemingly unrelated NLP tasks) and dataset composition (e.g., differing chain length at training and test time), as well as architectural variants such as weight-tied layers or adding convolutional components. We study how the trained models eventually succeed at the task, and in particular, we are able to understand (to some extent) some of the attention heads as well as how the information flows in the network. Based on these observations we propose a hypothesis that here pretraining helps merely due to being a smart initialization rather than some deep knowledge stored in the network. We also observe that in some data regime the trained transformer finds "shortcut" solutions to follow the chain of reasoning, which impedes the model's ability to generalize to simple variants of the main task, and moreover we find that one can prevent such shortcut with appropriate architecture modification or careful data preparation. Motivated by our findings, we begin to explore the task of learning to execute C programs, where a convolutional modification to transformers, namely adding convolutional structures in the key/query/value maps, shows an encouraging edge.