 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEven Sparser Graph Transformers
Nov 25, 2024



Graph Transformers excel in long-range dependency modeling, but generally require quadratic memory complexity in the number of nodes in an input graph, and hence have trouble scaling to large graphs. Sparse attention variants such as Exphormer can help, but may require high-degree augmentations to the input graph for good performance, and do not attempt to sparsify an already-dense input graph. As the learned attention mechanisms tend to use few of these edges, such high-degree connections may be unnecessary. We show (empirically and with theoretical backing) that attention scores on graphs are usually quite consistent across network widths, and use this observation to propose a two-stage procedure, which we call Spexphormer: first, train a narrow network on the full augmented graph. Next, use only the active connections to train a wider network on a much sparser graph. We establish theoretical conditions when a narrow network's attention scores can match those of a wide network, and show that Spexphormer achieves good performance with drastically reduced memory requirements on various graph datasets.
A Theory for Compressibility of Graph Transformers for Transductive Learning
Nov 20, 2024



Transductive tasks on graphs differ fundamentally from typical supervised machine learning tasks, as the independent and identically distributed (i.i.d.) assumption does not hold among samples. Instead, all train/test/validation samples are present during training, making them more akin to a semi-supervised task. These differences make the analysis of the models substantially different from other models. Recently, Graph Transformers have significantly improved results on these datasets by overcoming long-range dependency problems. However, the quadratic complexity of full Transformers has driven the community to explore more efficient variants, such as those with sparser attention patterns. While the attention matrix has been extensively discussed, the hidden dimension or width of the network has received less attention. In this work, we establish some theoretical bounds on how and under what conditions the hidden dimension of these networks can be compressed. Our results apply to both sparse and dense variants of Graph Transformers.
Optimal Sketching for Residual Error Estimation for Matrix and Vector Norms
Aug 16, 2024
We study the problem of residual error estimation for matrix and vector norms using a linear sketch. Such estimates can be used, for example, to quickly assess how useful a more expensive low-rank approximation computation will be. The matrix case concerns the Frobenius norm and the task is to approximate the $k$-residual $\|A - A_k\|_F$ of the input matrix $A$ within a $(1+\epsilon)$-factor, where $A_k$ is the optimal rank-$k$ approximation. We provide a tight bound of $\Theta(k^2/\epsilon^4)$ on the size of bilinear sketches, which have the form of a matrix product $SAT$. This improves the previous $O(k^2/\epsilon^6)$ upper bound in (Andoni et al. SODA 2013) and gives the first non-trivial lower bound, to the best of our knowledge. In our algorithm, our sketching matrices $S$ and $T$ can both be sparse matrices, allowing for a very fast update time. We demonstrate that this gives a substantial advantage empirically, for roughly the same sketch size and accuracy as in previous work. For the vector case, we consider the $\ell_p$-norm for $p>2$, where the task is to approximate the $k$-residual $\|x - x_k\|_p$ up to a constant factor, where $x_k$ is the optimal $k$-sparse approximation to $x$. Such vector norms are frequently studied in the data stream literature and are useful for finding frequent items or so-called heavy hitters. We establish an upper bound of $O(k^{2/p}n^{1-2/p}\operatorname{poly}(\log n))$ for constant $\epsilon$ on the dimension of a linear sketch for this problem. Our algorithm can be extended to the $\ell_p$ sparse recovery problem with the same sketching dimension, which seems to be the first such bound for $p > 2$. We also show an $\Omega(k^{2/p}n^{1-2/p})$ lower bound for the sparse recovery problem, which is tight up to a $\mathrm{poly}(\log n)$ factor.
$\ell_p$-Regression in the Arbitrary Partition Model of Communication
Jul 11, 2023We consider the randomized communication complexity of the distributed $\ell_p$-regression problem in the coordinator model, for $p\in (0,2]$. In this problem, there is a coordinator and $s$ servers. The $i$-th server receives $A^i\in\{-M, -M+1, \ldots, M\}^{n\times d}$ and $b^i\in\{-M, -M+1, \ldots, M\}^n$ and the coordinator would like to find a $(1+\epsilon)$-approximate solution to $\min_{x\in\mathbb{R}^n} \|(\sum_i A^i)x - (\sum_i b^i)\|_p$. Here $M \leq \mathrm{poly}(nd)$ for convenience. This model, where the data is additively shared across servers, is commonly referred to as the arbitrary partition model. We obtain significantly improved bounds for this problem. For $p = 2$, i.e., least squares regression, we give the first optimal bound of $\tilde{\Theta}(sd^2 + sd/\epsilon)$ bits. For $p \in (1,2)$,we obtain an $\tilde{O}(sd^2/\epsilon + sd/\mathrm{poly}(\epsilon))$ upper bound. Notably, for $d$ sufficiently large, our leading order term only depends linearly on $1/\epsilon$ rather than quadratically. We also show communication lower bounds of $\Omega(sd^2 + sd/\epsilon^2)$ for $p\in (0,1]$ and $\Omega(sd^2 + sd/\epsilon)$ for $p\in (1,2]$. Our bounds considerably improve previous bounds due to (Woodruff et al. COLT, 2013) and (Vempala et al., SODA, 2020).
Learning the Positions in CountSketch
Jun 11, 2023We consider sketching algorithms which first compress data by multiplication with a random sketch matrix, and then apply the sketch to quickly solve an optimization problem, e.g., low-rank approximation and regression. In the learning-based sketching paradigm proposed by~\cite{indyk2019learning}, the sketch matrix is found by choosing a random sparse matrix, e.g., CountSketch, and then the values of its non-zero entries are updated by running gradient descent on a training data set. Despite the growing body of work on this paradigm, a noticeable omission is that the locations of the non-zero entries of previous algorithms were fixed, and only their values were learned. In this work, we propose the first learning-based algorithms that also optimize the locations of the non-zero entries. Our first proposed algorithm is based on a greedy algorithm. However, one drawback of the greedy algorithm is its slower training time. We fix this issue and propose approaches for learning a sketching matrix for both low-rank approximation and Hessian approximation for second order optimization. The latter is helpful for a range of constrained optimization problems, such as LASSO and matrix estimation with a nuclear norm constraint. Both approaches achieve good accuracy with a fast running time. Moreover, our experiments suggest that our algorithm can still reduce the error significantly even if we only have a very limited number of training matrices.
Triangle and Four Cycle Counting with Predictions in Graph Streams
Mar 17, 2022
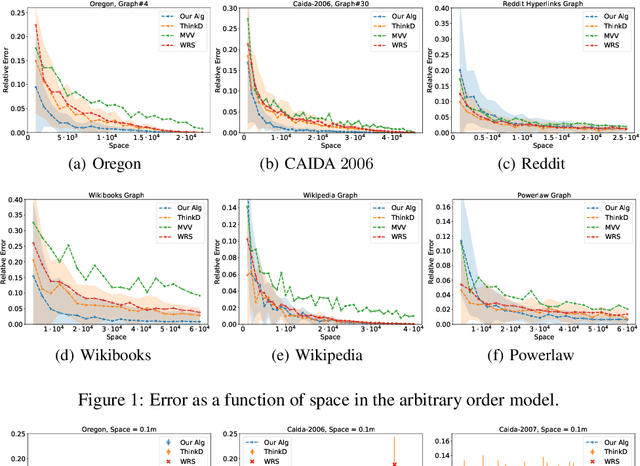
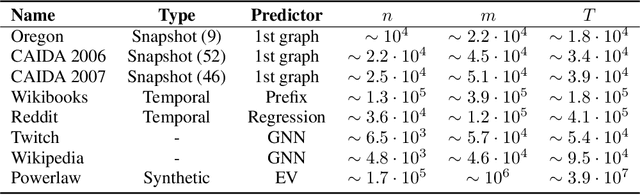
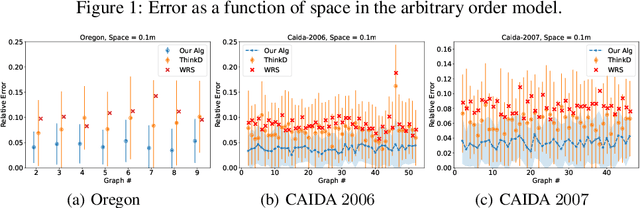
We propose data-driven one-pass streaming algorithms for estimating the number of triangles and four cycles, two fundamental problems in graph analytics that are widely studied in the graph data stream literature. Recently, (Hsu 2018) and (Jiang 2020) applied machine learning techniques in other data stream problems, using a trained oracle that can predict certain properties of the stream elements to improve on prior "classical" algorithms that did not use oracles. In this paper, we explore the power of a "heavy edge" oracle in multiple graph edge streaming models. In the adjacency list model, we present a one-pass triangle counting algorithm improving upon the previous space upper bounds without such an oracle. In the arbitrary order model, we present algorithms for both triangle and four cycle estimation with fewer passes and the same space complexity as in previous algorithms, and we show several of these bounds are optimal. We analyze our algorithms under several noise models, showing that the algorithms perform well even when the oracle errs. Our methodology expands upon prior work on "classical" streaming algorithms, as previous multi-pass and random order streaming algorithms can be seen as special cases of our algorithms, where the first pass or random order was used to implement the heavy edge oracle. Lastly, our experiments demonstrate advantages of the proposed method compared to state-of-the-art streaming algorithms.
Robust Learning of Fixed-Structure Bayesian Networks in Nearly-Linear Time
May 12, 2021We study the problem of learning Bayesian networks where an $\epsilon$-fraction of the samples are adversarially corrupted. We focus on the fully-observable case where the underlying graph structure is known. In this work, we present the first nearly-linear time algorithm for this problem with a dimension-independent error guarantee. Previous robust algorithms with comparable error guarantees are slower by at least a factor of $(d/\epsilon)$, where $d$ is the number of variables in the Bayesian network and $\epsilon$ is the fraction of corrupted samples. Our algorithm and analysis are considerably simpler than those in previous work. We achieve this by establishing a direct connection between robust learning of Bayesian networks and robust mean estimation. As a subroutine in our algorithm, we develop a robust mean estimation algorithm whose runtime is nearly-linear in the number of nonzeros in the input samples, which may be of independent interest.
Learning-Augmented Sketches for Hessians
Feb 24, 2021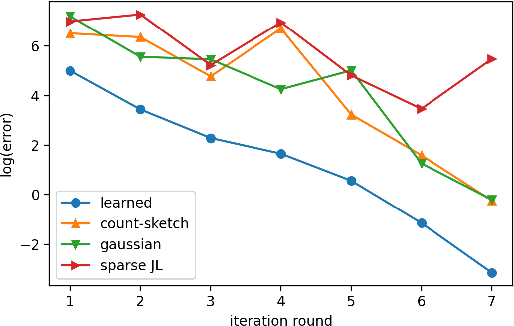
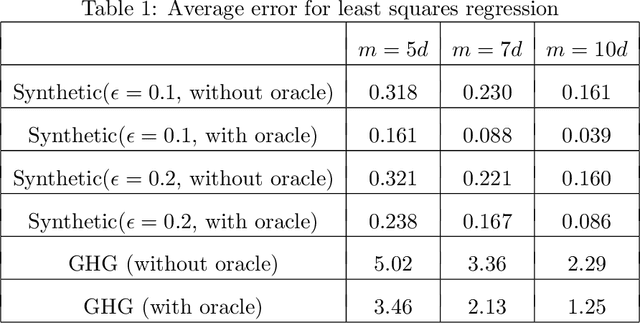
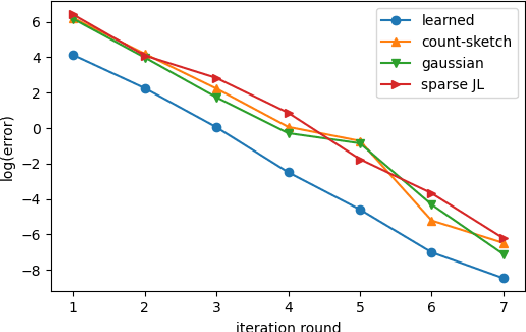
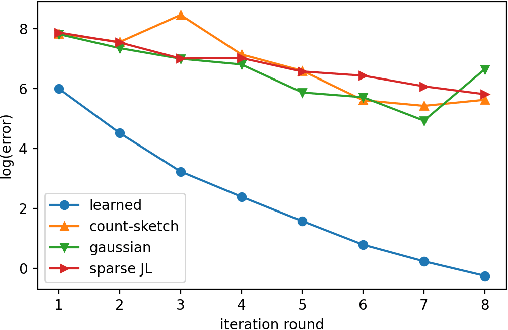
Sketching is a dimensionality reduction technique where one compresses a matrix by linear combinations that are typically chosen at random. A line of work has shown how to sketch the Hessian to speed up each iteration in a second order method, but such sketches usually depend only on the matrix at hand, and in a number of cases are even oblivious to the input matrix. One could instead hope to learn a distribution on sketching matrices that is optimized for the specific distribution of input matrices. We show how to design learned sketches for the Hessian in the context of second order methods, where we learn potentially different sketches for the different iterations of an optimization procedure. We show empirically that learned sketches, compared with their "non-learned" counterparts, improve the approximation accuracy for important problems, including LASSO, SVM, and matrix estimation with nuclear norm constraints. Several of our schemes can be proven to perform no worse than their unlearned counterparts. Additionally, we show that a smaller sketching dimension of the column space of a tall matrix is possible, assuming an oracle for predicting rows which have a large leverage score.