 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Semantic Image Alignment for Vehicle Localization
Oct 08, 2021
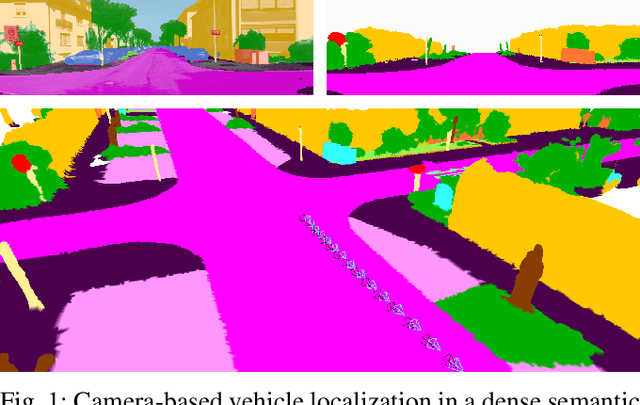
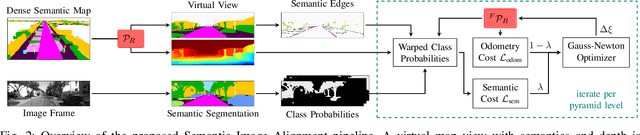
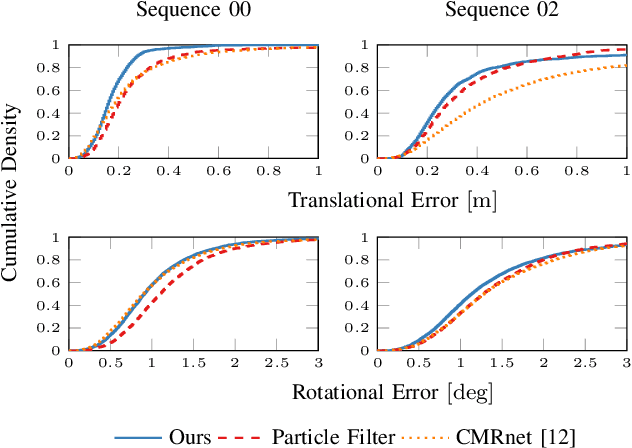
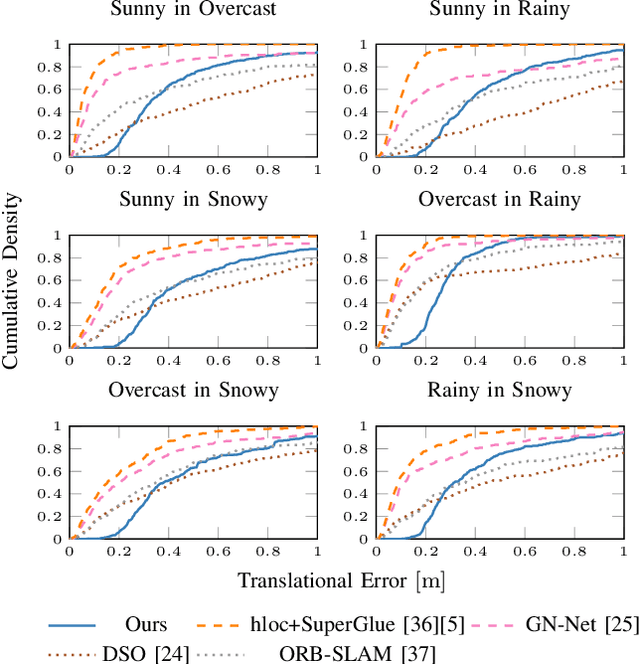
Accurate and reliable localization is a fundamental requirement for autonomous vehicles to use map information in higher-level tasks such as navigation or planning. In this paper, we present a novel approach to vehicle localization in dense semantic maps, including vectorized high-definition maps or 3D meshes, using semantic segmentation from a monocular camera. We formulate the localization task as a direct image alignment problem on semantic images, which allows our approach to robustly track the vehicle pose in semantically labeled maps by aligning virtual camera views rendered from the map to sequences of semantically segmented camera images. In contrast to existing visual localization approaches, the system does not require additional keypoint features, handcrafted localization landmark extractors or expensive LiDAR sensors. We demonstrate the wide applicability of our method on a diverse set of semantic mesh maps generated from stereo or LiDAR as well as manually annotated HD maps and show that it achieves reliable and accurate localization in real-time.
FedDM: Iterative Distribution Matching for Communication-Efficient Federated Learning
Jul 20, 2022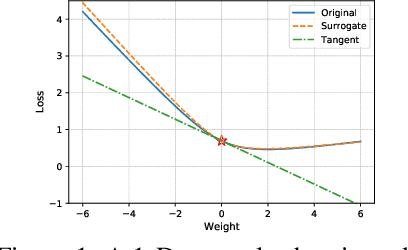

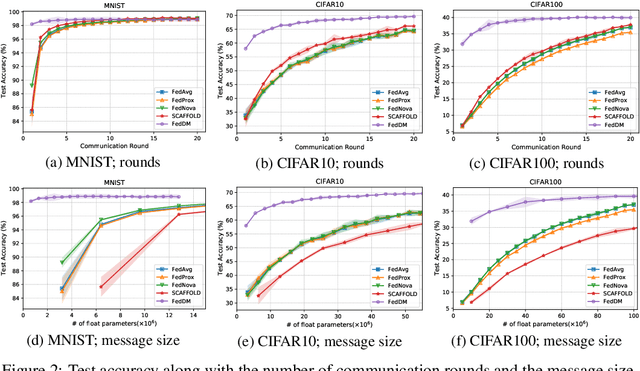
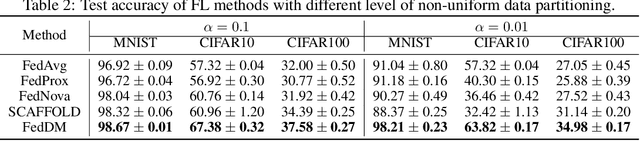
Federated learning~(FL) has recently attracted increasing attention from academia and industry, with the ultimate goal of achieving collaborative training under privacy and communication constraints. Existing iterative model averaging based FL algorithms require a large number of communication rounds to obtain a well-performed model due to extremely unbalanced and non-i.i.d data partitioning among different clients. Thus, we propose FedDM to build the global training objective from multiple local surrogate functions, which enables the server to gain a more global view of the loss landscape. In detail, we construct synthetic sets of data on each client to locally match the loss landscape from original data through distribution matching. FedDM reduces communication rounds and improves model quality by transmitting more informative and smaller synthesized data compared with unwieldy model weights. We conduct extensive experiments on three image classification datasets, and results show that our method can outperform other FL counterparts in terms of efficiency and model performance. Moreover, we demonstrate that FedDM can be adapted to preserve differential privacy with Gaussian mechanism and train a better model under the same privacy budget.
NTIRE 2022 Challenge on High Dynamic Range Imaging: Methods and Results
May 25, 2022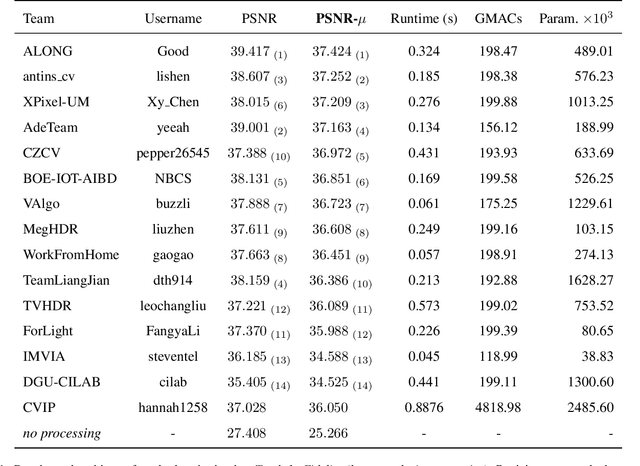
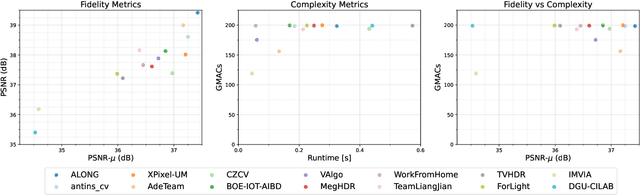
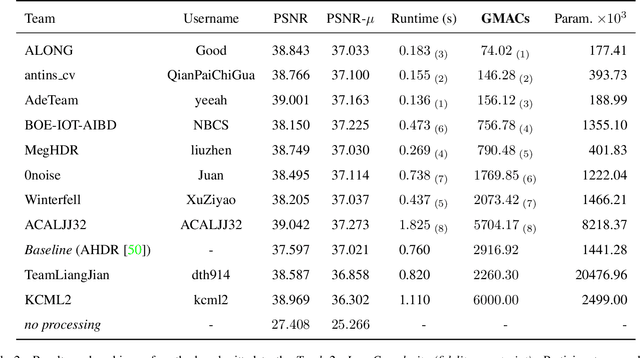
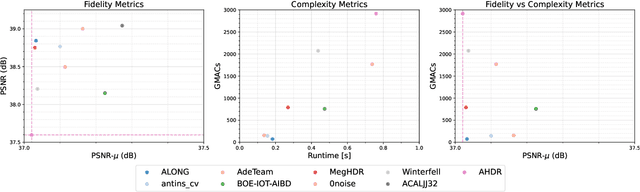
This paper reviews the challenge on constrained high dynamic range (HDR) imaging that was part of the New Trends in Image Restoration and Enhancement (NTIRE) workshop, held in conjunction with CVPR 2022. This manuscript focuses on the competition set-up, datasets, the proposed methods and their results. The challenge aims at estimating an HDR image from multiple respective low dynamic range (LDR) observations, which might suffer from under- or over-exposed regions and different sources of noise. The challenge is composed of two tracks with an emphasis on fidelity and complexity constraints: In Track 1, participants are asked to optimize objective fidelity scores while imposing a low-complexity constraint (i.e. solutions can not exceed a given number of operations). In Track 2, participants are asked to minimize the complexity of their solutions while imposing a constraint on fidelity scores (i.e. solutions are required to obtain a higher fidelity score than the prescribed baseline). Both tracks use the same data and metrics: Fidelity is measured by means of PSNR with respect to a ground-truth HDR image (computed both directly and with a canonical tonemapping operation), while complexity metrics include the number of Multiply-Accumulate (MAC) operations and runtime (in seconds).
* CVPR Workshops 2022. 15 pages, 21 figures, 2 tables
Hierarchical Image-Goal Navigation in Real Crowded Scenarios
Aug 13, 2021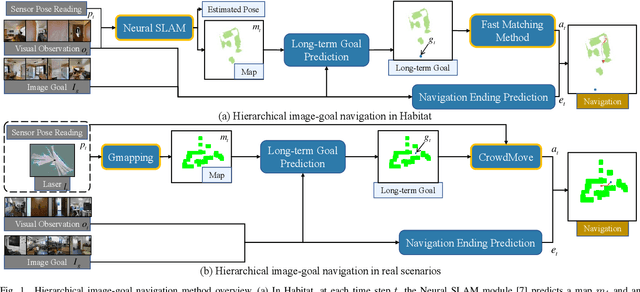

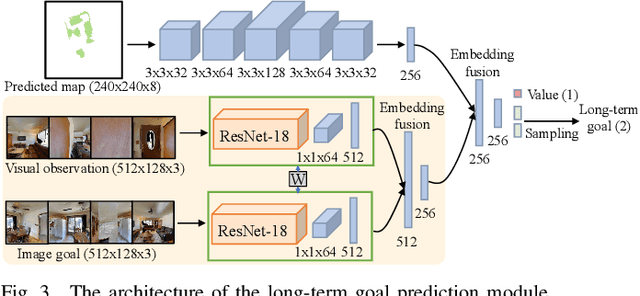

This work studies the problem of image-goal navigation, which entails guiding robots with noisy sensors and controls through real crowded environments. Recent fruitful approaches rely on deep reinforcement learning and learn navigation policies in simulation environments that are much simpler in complexity than real environments. Directly transferring these trained policies to real environments can be extremely challenging or even dangerous. We tackle this problem with a hierarchical navigation method composed of four decoupled modules. The first module maintains an obstacle map during robot navigation. The second one predicts a long-term goal on the real-time map periodically. The third one plans collision-free command sets for navigating to long-term goals, while the final module stops the robot properly near the goal image. The four modules are developed separately to suit the image-goal navigation in real crowded scenarios. In addition, the hierarchical decomposition decouples the learning of navigation goal planning, collision avoidance and navigation ending prediction, which cuts down the search space during navigation training and helps improve the generalization to previously unseen real scenes. We evaluate the method in both a simulator and the real world with a mobile robot. The results show that our method outperforms several navigation baselines and can successfully achieve navigation tasks in these scenarios.
RandomMix: A mixed sample data augmentation method with multiple mixed modes
May 18, 2022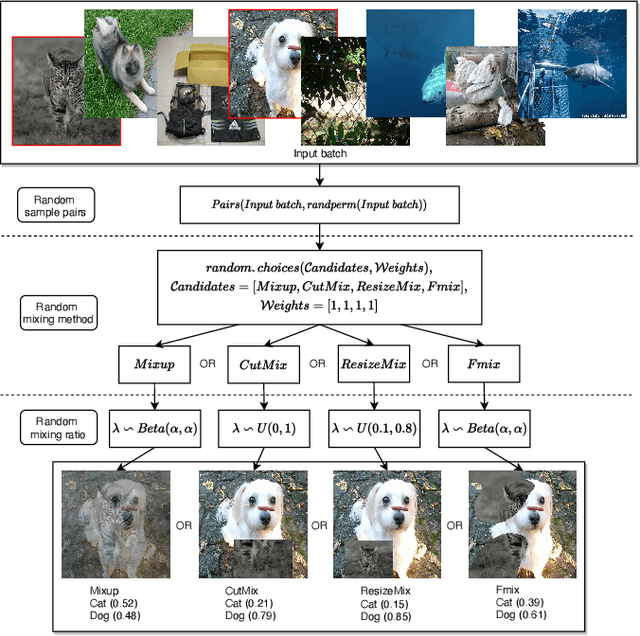
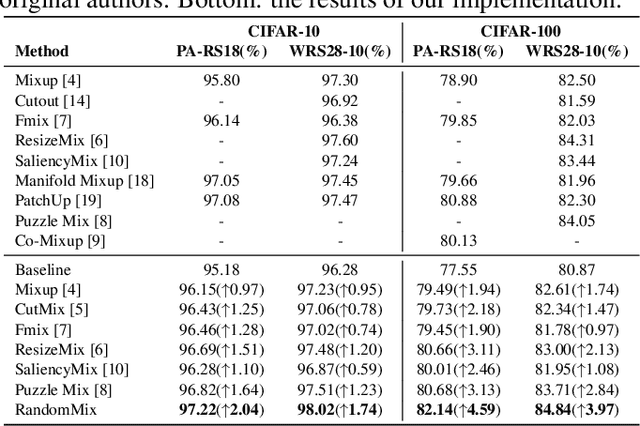
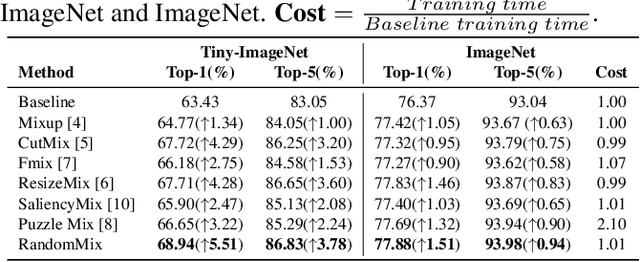

Data augmentation is a very practical technique that can be used to improve the generalization ability of neural networks and prevent overfitting. Recently, mixed sample data augmentation has received a lot of attention and achieved great success. In order to enhance the performance of mixed sample data augmentation, a series of recent works are devoted to obtaining and analyzing the salient regions of the image, and using the saliency area to guide the image mixing. However, obtaining the salient information of an image requires a lot of extra calculations. Different from improving performance through saliency analysis, our proposed method RandomMix mainly increases the diversity of the mixed sample to enhance the generalization ability and performance of neural networks. Moreover, RandomMix can improve the robustness of the model, does not require too much additional calculation, and is easy to insert into the training pipeline. Finally, experiments on the CIFAR-10/100, Tiny-ImageNet, ImageNet, and Google Speech Commands datasets demonstrate that RandomMix achieves better performance than other state-of-the-art mixed sample data augmentation methods.
Masked Autoencoders that Listen
Jul 13, 2022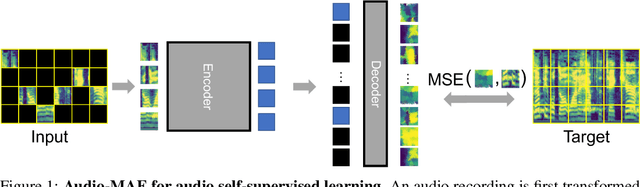
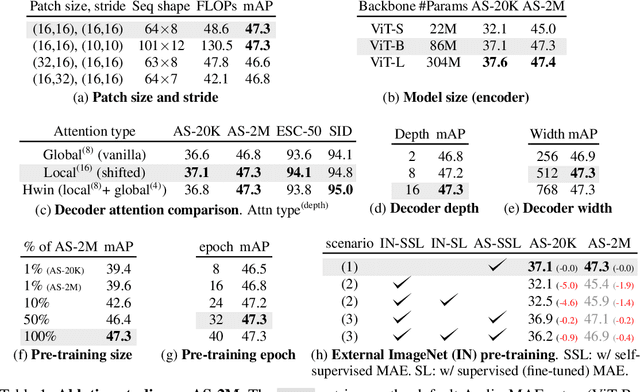

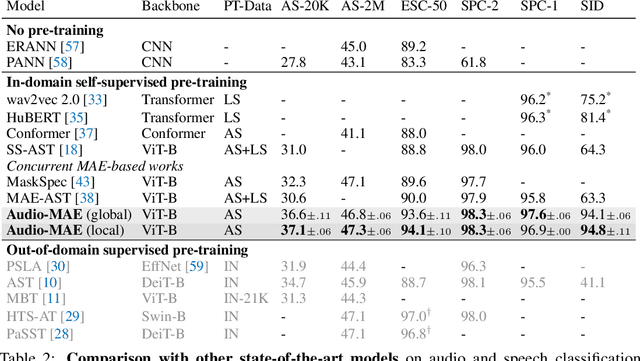
This paper studies a simple extension of image-based Masked Autoencoders (MAE) to self-supervised representation learning from audio spectrograms. Following the Transformer encoder-decoder design in MAE, our Audio-MAE first encodes audio spectrogram patches with a high masking ratio, feeding only the non-masked tokens through encoder layers. The decoder then re-orders and decodes the encoded context padded with mask tokens, in order to reconstruct the input spectrogram. We find it beneficial to incorporate local window attention in the decoder, as audio spectrograms are highly correlated in local time and frequency bands. We then fine-tune the encoder with a lower masking ratio on target datasets. Empirically, Audio-MAE sets new state-of-the-art performance on six audio and speech classification tasks, outperforming other recent models that use external supervised pre-training. The code and models will be at https://github.com/facebookresearch/AudioMAE.
Subgroup Discovery in Unstructured Data
Jul 15, 2022


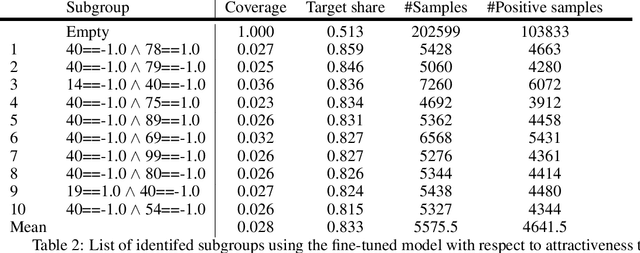
Subgroup discovery is a descriptive and exploratory data mining technique to identify subgroups in a population that exhibit interesting behavior with respect to a variable of interest. Subgroup discovery has numerous applications in knowledge discovery and hypothesis generation, yet it remains inapplicable for unstructured, high-dimensional data such as images. This is because subgroup discovery algorithms rely on defining descriptive rules based on (attribute, value) pairs, however, in unstructured data, an attribute is not well defined. Even in cases where the notion of attribute intuitively exists in the data, such as a pixel in an image, due to the high dimensionality of the data, these attributes are not informative enough to be used in a rule. In this paper, we introduce the subgroup-aware variational autoencoder, a novel variational autoencoder that learns a representation of unstructured data which leads to subgroups with higher quality. Our experimental results demonstrate the effectiveness of the method at learning subgroups with high quality while supporting the interpretability of the concepts.
3D Human Texture Estimation from a Single Image with Transformers
Sep 06, 2021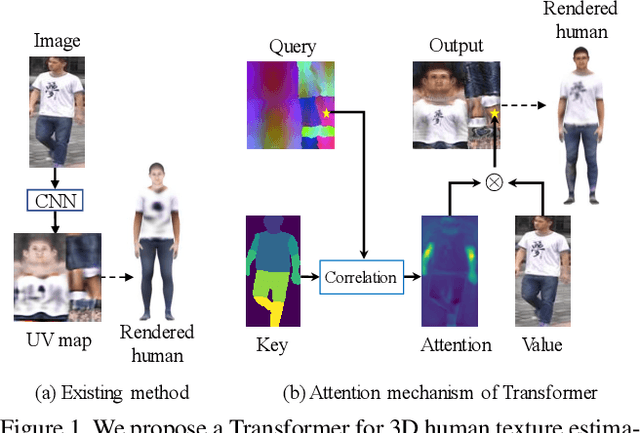
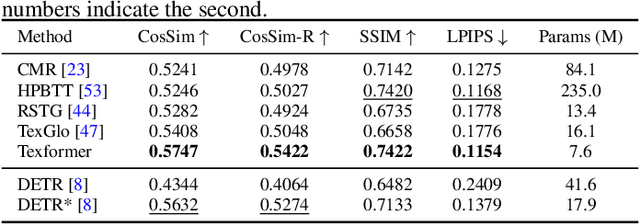
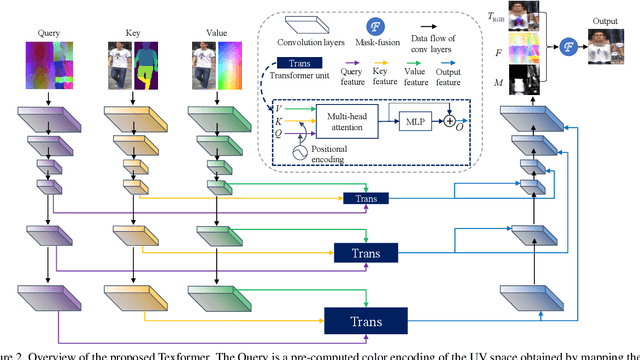
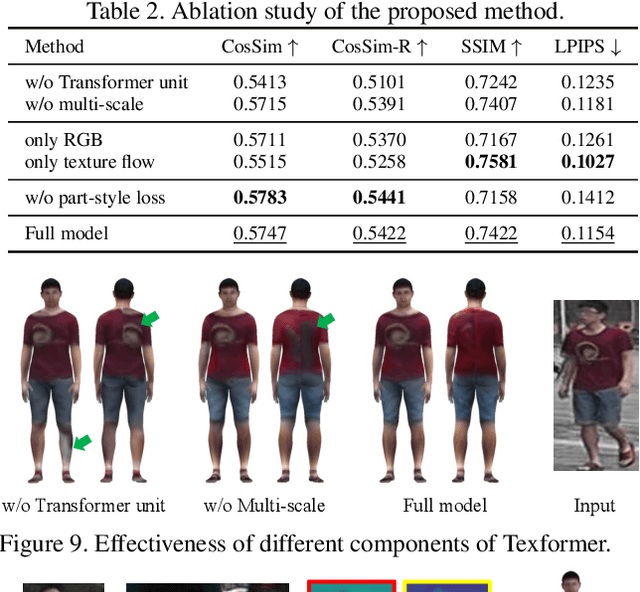
We propose a Transformer-based framework for 3D human texture estimation from a single image. The proposed Transformer is able to effectively exploit the global information of the input image, overcoming the limitations of existing methods that are solely based on convolutional neural networks. In addition, we also propose a mask-fusion strategy to combine the advantages of the RGB-based and texture-flow-based models. We further introduce a part-style loss to help reconstruct high-fidelity colors without introducing unpleasant artifacts. Extensive experiments demonstrate the effectiveness of the proposed method against state-of-the-art 3D human texture estimation approaches both quantitatively and qualitatively.
* ICCV 2021 Oral, Project: https://www.mmlab-ntu.com/project/texformer, Code: https://github.com/xuxy09/Texformer
No-Reference Image Quality Assessment by Hallucinating Pristine Features
Aug 10, 2021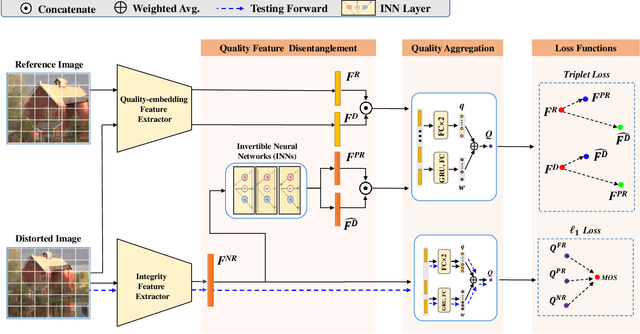

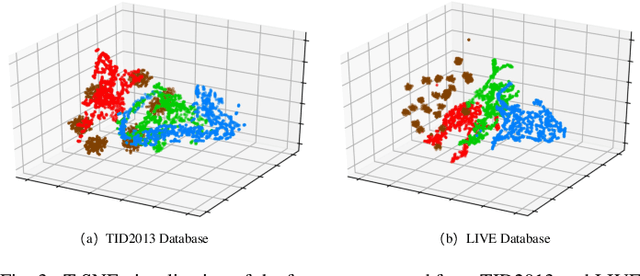
In this paper, we propose a no-reference (NR) image quality assessment (IQA) method via feature level pseudo-reference (PR) hallucination. The proposed quality assessment framework is grounded on the prior models of natural image statistical behaviors and rooted in the view that the perceptually meaningful features could be well exploited to characterize the visual quality. Herein, the PR features from the distorted images are learned by a mutual learning scheme with the pristine reference as the supervision, and the discriminative characteristics of PR features are further ensured with the triplet constraints. Given a distorted image for quality inference, the feature level disentanglement is performed with an invertible neural layer for final quality prediction, leading to the PR and the corresponding distortion features for comparison. The effectiveness of our proposed method is demonstrated on four popular IQA databases, and superior performance on cross-database evaluation also reveals the high generalization capability of our method. The implementation of our method is publicly available on https://github.com/Baoliang93/FPR.
Achieving Utility, Fairness, and Compactness via Tunable Information Bottleneck Measures
Jun 20, 2022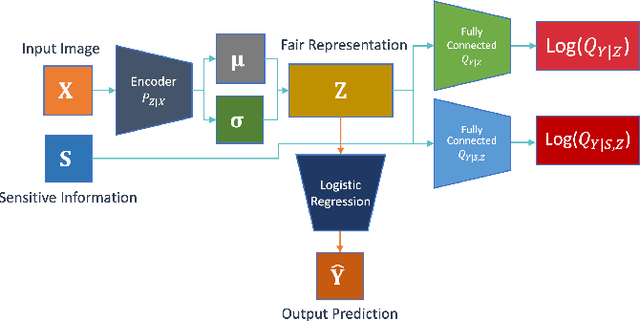

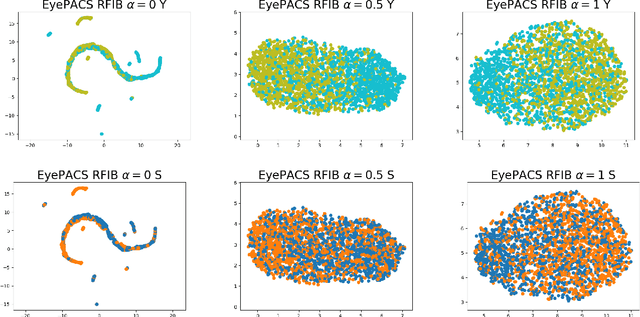

Designing machine learning algorithms that are accurate yet fair, not discriminating based on any sensitive attribute, is of paramount importance for society to accept AI for critical applications. In this article, we propose a novel fair representation learning method termed the R\'enyi Fair Information Bottleneck Method (RFIB) which incorporates constraints for utility, fairness, and compactness of representation, and apply it to image classification. A key attribute of our approach is that we consider - in contrast to most prior work - both demographic parity and equalized odds as fairness constraints, allowing for a more nuanced satisfaction of both criteria. Leveraging a variational approach, we show that our objectives yield a loss function involving classical Information Bottleneck (IB) measures and establish an upper bound in terms of the R\'enyi divergence of order $\alpha$ on the mutual information IB term measuring compactness between the input and its encoded embedding. Experimenting on three different image datasets (EyePACS, CelebA, and FairFace), we study the influence of the $\alpha$ parameter as well as two other tunable IB parameters on achieving utility/fairness trade-off goals, and show that the $\alpha$ parameter gives an additional degree of freedom that can be used to control the compactness of the representation. We evaluate the performance of our method using various utility, fairness, and compound utility/fairness metrics, showing that RFIB outperforms current state-of-the-art approaches.