 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructured Personality Control and Adaptation for LLM Agents
Jan 15, 2026Large Language Models (LLMs) are increasingly shaping human-computer interaction (HCI), from personalized assistants to social simulations. Beyond language competence, researchers are exploring whether LLMs can exhibit human-like characteristics that influence engagement, decision-making, and perceived realism. Personality, in particular, is critical, yet existing approaches often struggle to achieve both nuanced and adaptable expression. We present a framework that models LLM personality via Jungian psychological types, integrating three mechanisms: a dominant-auxiliary coordination mechanism for coherent core expression, a reinforcement-compensation mechanism for temporary adaptation to context, and a reflection mechanism that drives long-term personality evolution. This design allows the agent to maintain nuanced traits while dynamically adjusting to interaction demands and gradually updating its underlying structure. Personality alignment is evaluated using Myers-Briggs Type Indicator questionnaires and tested under diverse challenge scenarios as a preliminary structured assessment. Findings suggest that evolving, personality-aware LLMs can support coherent, context-sensitive interactions, enabling naturalistic agent design in HCI.
The Tenth NTIRE 2025 Efficient Super-Resolution Challenge Report
Apr 14, 2025This paper presents a comprehensive review of the NTIRE 2025 Challenge on Single-Image Efficient Super-Resolution (ESR). The challenge aimed to advance the development of deep models that optimize key computational metrics, i.e., runtime, parameters, and FLOPs, while achieving a PSNR of at least 26.90 dB on the $\operatorname{DIV2K\_LSDIR\_valid}$ dataset and 26.99 dB on the $\operatorname{DIV2K\_LSDIR\_test}$ dataset. A robust participation saw \textbf{244} registered entrants, with \textbf{43} teams submitting valid entries. This report meticulously analyzes these methods and results, emphasizing groundbreaking advancements in state-of-the-art single-image ESR techniques. The analysis highlights innovative approaches and establishes benchmarks for future research in the field.
CDI: Blind Image Restoration Fidelity Evaluation based on Consistency with Degraded Image
Jan 24, 2025Recent advancements in Blind Image Restoration (BIR) methods, based on Generative Adversarial Networks and Diffusion Models, have significantly improved visual quality. However, they present significant challenges for Image Quality Assessment (IQA), as the existing Full-Reference IQA methods often rate images with high perceptual quality poorly. In this paper, we reassess the Solution Non-Uniqueness and Degradation Indeterminacy issues of BIR, and propose constructing a specific BIR IQA system. In stead of directly comparing a restored image with a reference image, the BIR IQA evaluates fidelity by calculating the Consistency with Degraded Image (CDI). Specifically, we propose a wavelet domain Reference Guided CDI algorithm, which can acquire the consistency with a degraded image for various types without requiring knowledge of degradation parameters. The supported degradation types include down sampling, blur, noise, JPEG and complex combined degradations etc. In addition, we propose a Reference Agnostic CDI, enabling BIR fidelity evaluation without reference images. Finally, in order to validate the rationality of CDI, we create a new Degraded Images Switch Display Comparison Dataset (DISDCD) for subjective evaluation of BIR fidelity. Experiments conducted on DISDCD verify that CDI is markedly superior to common Full Reference IQA methods for BIR fidelity evaluation. The source code and the DISDCD dataset will be publicly available shortly.
Valid Information Guidance Network for Compressed Video Quality Enhancement
Feb 28, 2023

In recent years deep learning methods have shown great superiority in compressed video quality enhancement tasks. Existing methods generally take the raw video as the ground truth and extract practical information from consecutive frames containing various artifacts. However, they do not fully exploit the valid information of compressed and raw videos to guide the quality enhancement for compressed videos. In this paper, we propose a unique Valid Information Guidance scheme (VIG) to enhance the quality of compressed videos by mining valid information from both compressed videos and raw videos. Specifically, we propose an efficient framework, Compressed Redundancy Filtering (CRF) network, to balance speed and enhancement. After removing the redundancy by filtering the information, CRF can use the valid information of the compressed video to reconstruct the texture. Furthermore, we propose a progressive Truth Guidance Distillation (TGD) strategy, which does not need to design additional teacher models and distillation loss functions. By only using the ground truth as input to guide the model to aggregate the correct spatio-temporal correspondence across the raw frames, TGD can significantly improve the enhancement effect without increasing the extra training cost. Extensive experiments show that our method achieves the state-of-the-art performance of compressed video quality enhancement in terms of accuracy and efficiency.
Power Efficient Video Super-Resolution on Mobile NPUs with Deep Learning, Mobile AI & AIM 2022 challenge: Report
Nov 07, 2022



Video super-resolution is one of the most popular tasks on mobile devices, being widely used for an automatic improvement of low-bitrate and low-resolution video streams. While numerous solutions have been proposed for this problem, they are usually quite computationally demanding, demonstrating low FPS rates and power efficiency on mobile devices. In this Mobile AI challenge, we address this problem and propose the participants to design an end-to-end real-time video super-resolution solution for mobile NPUs optimized for low energy consumption. The participants were provided with the REDS training dataset containing video sequences for a 4X video upscaling task. The runtime and power efficiency of all models was evaluated on the powerful MediaTek Dimensity 9000 platform with a dedicated AI processing unit capable of accelerating floating-point and quantized neural networks. All proposed solutions are fully compatible with the above NPU, demonstrating an up to 500 FPS rate and 0.2 [Watt / 30 FPS] power consumption. A detailed description of all models developed in the challenge is provided in this paper.
NTIRE 2022 Challenge on High Dynamic Range Imaging: Methods and Results
May 25, 2022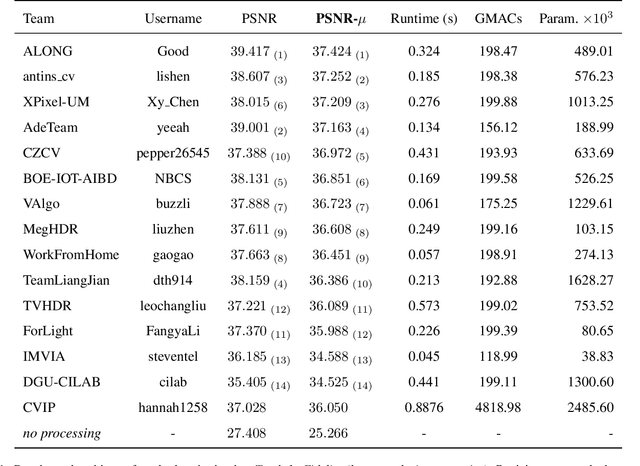
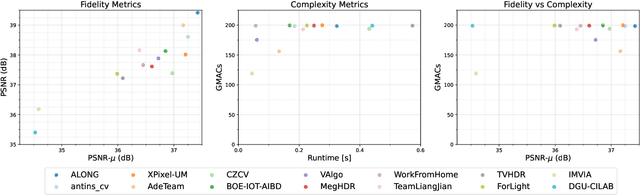
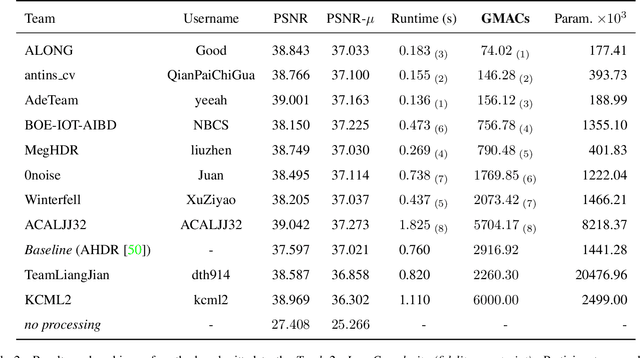
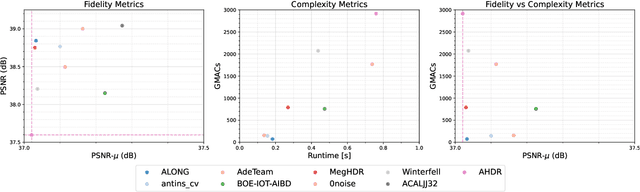
This paper reviews the challenge on constrained high dynamic range (HDR) imaging that was part of the New Trends in Image Restoration and Enhancement (NTIRE) workshop, held in conjunction with CVPR 2022. This manuscript focuses on the competition set-up, datasets, the proposed methods and their results. The challenge aims at estimating an HDR image from multiple respective low dynamic range (LDR) observations, which might suffer from under- or over-exposed regions and different sources of noise. The challenge is composed of two tracks with an emphasis on fidelity and complexity constraints: In Track 1, participants are asked to optimize objective fidelity scores while imposing a low-complexity constraint (i.e. solutions can not exceed a given number of operations). In Track 2, participants are asked to minimize the complexity of their solutions while imposing a constraint on fidelity scores (i.e. solutions are required to obtain a higher fidelity score than the prescribed baseline). Both tracks use the same data and metrics: Fidelity is measured by means of PSNR with respect to a ground-truth HDR image (computed both directly and with a canonical tonemapping operation), while complexity metrics include the number of Multiply-Accumulate (MAC) operations and runtime (in seconds).
* CVPR Workshops 2022. 15 pages, 21 figures, 2 tables