 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Extremely Data-efficient and Generative LLM-based Reinforcement Learning Agent for Recommenders
Aug 28, 2024



Recent advancements in large language models (LLMs) have enabled understanding webpage contexts, product details, and human instructions. Utilizing LLMs as the foundational architecture for either reward models or policies in reinforcement learning has gained popularity -- a notable achievement is the success of InstructGPT. RL algorithms have been instrumental in maximizing long-term customer satisfaction and avoiding short-term, myopic goals in industrial recommender systems, which often rely on deep learning models to predict immediate clicks or purchases. In this project, several RL methods are implemented and evaluated using the WebShop benchmark environment, data, simulator, and pre-trained model checkpoints. The goal is to train an RL agent to maximize the purchase reward given a detailed human instruction describing a desired product. The RL agents are developed by fine-tuning a pre-trained BERT model with various objectives, learning from preferences without a reward model, and employing contemporary training techniques such as Proximal Policy Optimization (PPO) as used in InstructGPT, and Direct Preference Optimization (DPO). This report also evaluates the RL agents trained using generative trajectories. Evaluations were conducted using Thompson sampling in the WebShop simulator environment. The simulated online experiments demonstrate that agents trained on generated trajectories exhibited comparable task performance to those trained using human trajectories. This has demonstrated an example of an extremely low-cost data-efficient way of training reinforcement learning agents. Also, with limited training time (<2hours), without utilizing any images, a DPO agent achieved a 19% success rate after approximately 3000 steps or 30 minutes of training on T4 GPUs, compared to a PPO agent, which reached a 15% success rate.
NTIRE 2022 Challenge on High Dynamic Range Imaging: Methods and Results
May 25, 2022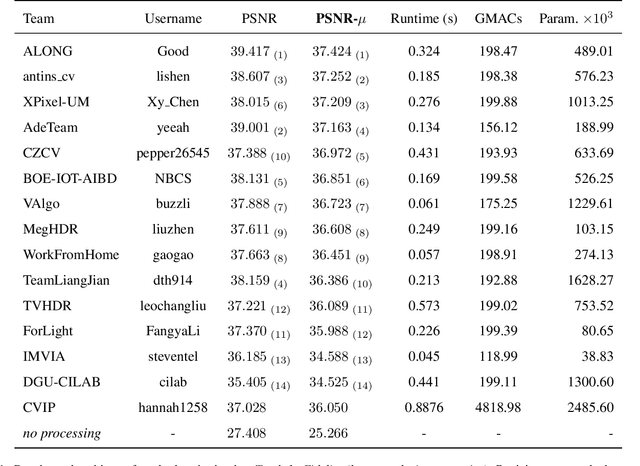
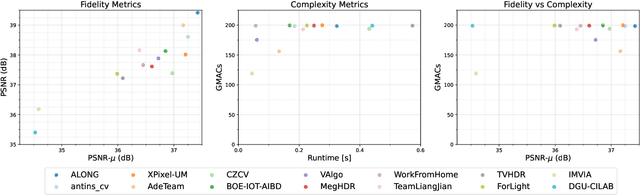
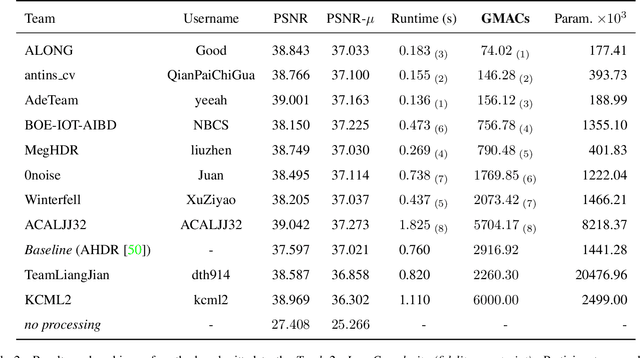
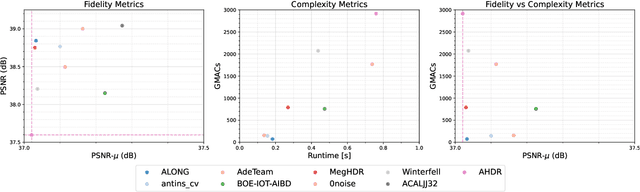
This paper reviews the challenge on constrained high dynamic range (HDR) imaging that was part of the New Trends in Image Restoration and Enhancement (NTIRE) workshop, held in conjunction with CVPR 2022. This manuscript focuses on the competition set-up, datasets, the proposed methods and their results. The challenge aims at estimating an HDR image from multiple respective low dynamic range (LDR) observations, which might suffer from under- or over-exposed regions and different sources of noise. The challenge is composed of two tracks with an emphasis on fidelity and complexity constraints: In Track 1, participants are asked to optimize objective fidelity scores while imposing a low-complexity constraint (i.e. solutions can not exceed a given number of operations). In Track 2, participants are asked to minimize the complexity of their solutions while imposing a constraint on fidelity scores (i.e. solutions are required to obtain a higher fidelity score than the prescribed baseline). Both tracks use the same data and metrics: Fidelity is measured by means of PSNR with respect to a ground-truth HDR image (computed both directly and with a canonical tonemapping operation), while complexity metrics include the number of Multiply-Accumulate (MAC) operations and runtime (in seconds).
* CVPR Workshops 2022. 15 pages, 21 figures, 2 tables