 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLet the Results Speak: A Replication-First Paradigm for LLM Behavioral Benchmarking
May 27, 2026Subjective evaluation of LLM behavior -- empathy, restraint, calibrated emotional tone -- is hard. Human inter-rater agreement on such qualities saturates near rho ~ 0.45, and an LLM-as-judge proxy alone risks circularity: a judge sharing the target's training cohort cannot independently verify it. Anchoring validity to a single human-rater consensus does not extend to capabilities where humans themselves disagree. We propose a replication-first paradigm: instead of anchoring on one rater group, we certify the instrument via four orthogonal properties -- reliability across K runs, cross-instrument replication across architecturally distinct judges, historical-footprint calibration via judges from earlier training cohorts, and pre-registered prediction. We test it on emotional accompaniment by letting the rubric self-evolve data-driven across iterations: the dimensions are not pre-stipulated and the procedure stabilizes to a 9-dimension set. Pre-registration applies to 10 falsifiable hypotheses and 11 forward predictions, committed before any test data was collected. Applied to 49 models across 8 families, the paradigm surfaces what aggregate scores hide. On advice-restraint -- whether a model refrains from giving unsolicited solutions in empathic contexts -- gpt-5 falls 1.87 points from gpt-4.1 and Opus-4.7 falls 0.629 from Opus-4.6, while aggregate scores stay flat. The regression survives three user-proxy swaps (95% of magnitude), replicates across a 5-family judge stack and a 17-month cohort gap, and persists on 74 held-out real ESConv conversations (rho in [0.749, 0.850]); the instrument reaches ordinal Krippendorff alpha = 0.91. As a by-product, the paradigm acts as a saturation-source diagnostic, separating instrumental ceilings (breakable by rubric refinement) from structural ceilings (needing scenario or roster intervention).
PlanRAG-Audio: Planning and Retrieval Augmented Generation for Long-form Audio Understanding
May 19, 2026Long-form audio understanding poses significant challenges for large audio language models (LALMs) due to the extreme length of audio sequences and the need to reason over heterogeneous acoustic cues distributed over time, such as speech content, speaker identity, emotion, and sound events. To address these challenges, we propose \textbf{PlanRAG-Audio}, a planning-based retrieval-augmented generation framework for scalable long-form audio understanding. Rather than having audio LALMs process entire recordings directly, PlanRAG-Audio explicitly plans which modalities and temporal spans are required for a given query, and retrieves only query-relevant information from a structured text and audio database. This retrieval planning enables effective reasoning over complex, cross-domain audio queries while substantially reducing the input length passed to the large language models. Experiments across a wide range of speech/audio retrieval demonstrate that PlanRAG-Audio improves reasoning accuracy and stabilizes performance as audio duration increases by decoupling inference cost from raw audio length.
Score-Informed BiLSTM Correction for Refining MIDI Velocity in Automatic Piano Transcription
Aug 11, 2025MIDI is a modern standard for storing music, recording how musical notes are played. Many piano performances have corresponding MIDI scores available online. Some of these are created by the original performer, recording on an electric piano alongside the audio, while others are through manual transcription. In recent years, automatic music transcription (AMT) has rapidly advanced, enabling machines to transcribe MIDI from audio. However, these transcriptions often require further correction. Assuming a perfect timing correction, we focus on the loudness correction in terms of MIDI velocity (a parameter in MIDI for loudness control). This task can be approached through score-informed MIDI velocity estimation, which has undergone several developments. While previous approaches introduced specifically built models to re-estimate MIDI velocity, thereby replacing AMT estimates, we propose a BiLSTM correction module to refine AMT-estimated velocity. Although we did not reach state-of-the-art performance, we validated our method on the well-known AMT system, the high-resolution piano transcription (HPT), and achieved significant improvements.
A Quantitative Evaluation of the Expressivity of BMI, Pose and Gender in Body Embeddings for Recognition and Identification
Mar 09, 2025Person Re-identification (ReID) systems identify individuals across images or video frames and play a critical role in various real-world applications. However, many ReID methods are influenced by sensitive attributes such as gender, pose, and body mass index (BMI), which vary in uncontrolled environments, leading to biases and reduced generalization. To address this, we extend the concept of expressivity to the body recognition domain to better understand how ReID models encode these attributes. Expressivity, defined as the mutual information between feature vector representations and specific attributes, is computed using a secondary neural network that takes feature and attribute vectors as inputs. This provides a quantitative framework for analyzing the extent to which sensitive attributes are embedded in the model's representations. We apply expressivity analysis to SemReID, a state-of-the-art self-supervised ReID model, and find that BMI consistently exhibits the highest expressivity scores in the model's final layers, underscoring its dominant role in feature encoding. In the final attention layer of the trained network, the expressivity order for body attributes is BMI > Pitch > Yaw > Gender, highlighting their relative importance in learned representations. Additionally, expressivity values evolve progressively across network layers and training epochs, reflecting a dynamic encoding of attributes during feature extraction. These insights emphasize the influence of body-related attributes on ReID models and provide a systematic methodology for identifying and mitigating attribute-driven biases. By leveraging expressivity analysis, we offer valuable tools to enhance the fairness, robustness, and generalization of ReID systems in diverse real-world settings.
Deriving Representative Structure from Music Corpora
Feb 21, 2025Western music is an innately hierarchical system of interacting levels of structure, from fine-grained melody to high-level form. In order to analyze music compositions holistically and at multiple granularities, we propose a unified, hierarchical meta-representation of musical structure called the structural temporal graph (STG). For a single piece, the STG is a data structure that defines a hierarchy of progressively finer structural musical features and the temporal relationships between them. We use the STG to enable a novel approach for deriving a representative structural summary of a music corpus, which we formalize as a dually NP-hard combinatorial optimization problem extending the Generalized Median Graph problem. Our approach first applies simulated annealing to develop a measure of structural distance between two music pieces rooted in graph isomorphism. Our approach then combines the formal guarantees of SMT solvers with nested simulated annealing over structural distances to produce a structurally sound, representative centroid STG for an entire corpus of STGs from individual pieces. To evaluate our approach, we conduct experiments verifying that structural distance accurately differentiates between music pieces, and that derived centroids accurately structurally characterize their corpora.
Pseudo Strong Labels from Frame-Level Predictions for Weakly Supervised Sound Event Detection
Jan 07, 2025Weakly Supervised Sound Event Detection (WSSED), which relies on audio tags without precise onset and offset times, has become prevalent due to the scarcity of strongly labeled data that includes exact temporal boundaries for events. This study introduces Frame-level Pseudo Strong Labeling (FPSL) to overcome the lack of temporal information in WSSED by generating pseudo strong labels from frame-level predictions. This enhances temporal localization during training and addresses the limitations of clip-wise weak supervision. We validate our approach across three benchmark datasets (DCASE2017 Task 4, DCASE2018 Task 4, and UrbanSED) and demonstrate significant improvements in key metrics such as the Polyphonic Sound Detection Scores (PSDS), event-based F1 scores, and intersection-based F1 scores. For example, Convolutional Recurrent Neural Networks (CRNNs) trained with FPSL outperform baseline models by 4.9% in PSDS1 on DCASE2017, 7.6% on DCASE2018, and 1.8% on UrbanSED, confirming the effectiveness of our method in enhancing model performance.
Impact of Noisy Labels on Sound Event Detection: Deletion Errors Are More Detrimental Than Insertion Errors
Aug 27, 2024This study explores the critical but underexamined impact of label noise on Sound Event Detection (SED), which requires both sound identification and precise temporal localization. We categorize label noise into deletion, insertion, substitution, and subjective types and systematically evaluate their effects on SED using synthetic and real-life datasets. Our analysis shows that deletion noise significantly degrades performance, while insertion noise is relatively benign. Moreover, loss functions effective against classification noise do not perform well for SED due to intra-class imbalance between foreground sound events and background sounds. We demonstrate that loss functions designed to address data imbalance in SED can effectively reduce the impact of noisy labels on system performance. For instance, halving the weight of background sounds in a synthetic dataset improved macro-F1 and micro-F1 scores by approximately $9\%$ with minimal Error Rate increase, with consistent results in real-life datasets. This research highlights the nuanced effects of noisy labels on SED systems and provides practical strategies to enhance model robustness, which are pivotal for both constructing new SED datasets and improving model performance, including efficient utilization of soft and crowdsourced labels.
Envisioning Possibilities and Challenges of AI for Personalized Cancer Care
Aug 19, 2024
The use of Artificial Intelligence (AI) in healthcare, including in caring for cancer survivors, has gained significant interest. However, gaps remain in our understanding of how such AI systems can provide care, especially for ethnic and racial minority groups who continue to face care disparities. Through interviews with six cancer survivors, we identify critical gaps in current healthcare systems such as a lack of personalized care and insufficient cultural and linguistic accommodation. AI, when applied to care, was seen as a way to address these issues by enabling real-time, culturally aligned, and linguistically appropriate interactions. We also uncovered concerns about the implications of AI-driven personalization, such as data privacy, loss of human touch in caregiving, and the risk of echo chambers that limit exposure to diverse information. We conclude by discussing the trade-offs between AI-enhanced personalization and the need for structural changes in healthcare that go beyond technological solutions, leading us to argue that we should begin by asking, ``Why personalization?''
Field Testing of a Stochastic Planner for ASV Navigation Using Satellite Images
Sep 26, 2023



We introduce a multi-sensor navigation system for autonomous surface vessels (ASV) intended for water-quality monitoring in freshwater lakes. Our mission planner uses satellite imagery as a prior map, formulating offline a mission-level policy for global navigation of the ASV and enabling autonomous online execution via local perception and local planning modules. A significant challenge is posed by the inconsistencies in traversability estimation between satellite images and real lakes, due to environmental effects such as wind, aquatic vegetation, shallow waters, and fluctuating water levels. Hence, we specifically modelled these traversability uncertainties as stochastic edges in a graph and optimized for a mission-level policy that minimizes the expected total travel distance. To execute the policy, we propose a modern local planner architecture that processes sensor inputs and plans paths to execute the high-level policy under uncertain traversability conditions. Our system was tested on three km-scale missions on a Northern Ontario lake, demonstrating that our GPS-, vision-, and sonar-enabled ASV system can effectively execute the mission-level policy and disambiguate the traversability of stochastic edges. Finally, we provide insights gained from practical field experience and offer several future directions to enhance the overall reliability of ASV navigation systems.
Masked Autoencoders that Listen
Jul 13, 2022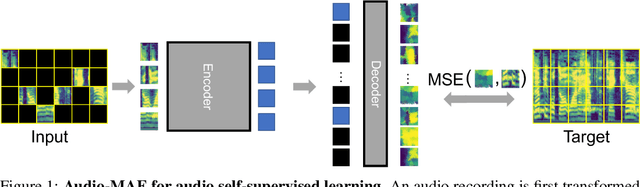
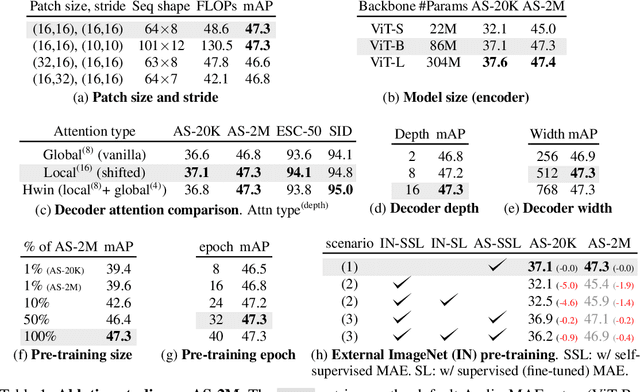

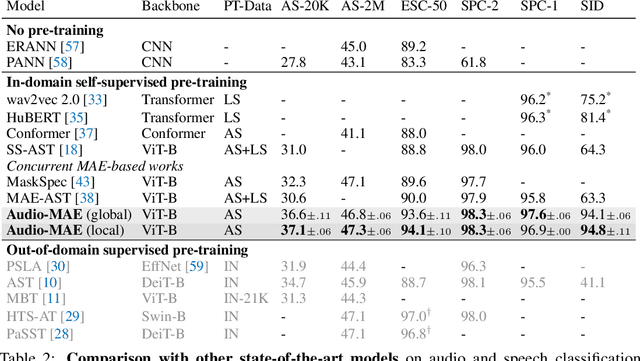
This paper studies a simple extension of image-based Masked Autoencoders (MAE) to self-supervised representation learning from audio spectrograms. Following the Transformer encoder-decoder design in MAE, our Audio-MAE first encodes audio spectrogram patches with a high masking ratio, feeding only the non-masked tokens through encoder layers. The decoder then re-orders and decodes the encoded context padded with mask tokens, in order to reconstruct the input spectrogram. We find it beneficial to incorporate local window attention in the decoder, as audio spectrograms are highly correlated in local time and frequency bands. We then fine-tune the encoder with a lower masking ratio on target datasets. Empirically, Audio-MAE sets new state-of-the-art performance on six audio and speech classification tasks, outperforming other recent models that use external supervised pre-training. The code and models will be at https://github.com/facebookresearch/AudioMAE.