 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Plane HyperX: A Low-Latency and Cost-Effective Network for Large-Scale AI and HPC Systems
Apr 26, 2026Multi-plane architectures have become increasingly prevalent in the Fat-Tree networks of AI data centers. By leveraging multiple ports on a single network interface card (NIC) or multiple NICs within a scale-up domain, each port or NIC is allocated to an independent network plane, thereby provisioning the overall system with multiple network planes. However, no prior literature has explored the application of multi-plane technologies to direct networks such as HyperX. This paper investigates the multi-plane HyperX network and demonstrates that, compared to state-of-the-art network topologies like multi-plane Fat-Tree, Dragonfly, and Dragonfly+, the multi-plane HyperX architecture achieves a significantly smaller network diameter and superior cost-effectiveness.
Frequency-domain Learning with Kernel Prior for Blind Image Deblurring
Apr 20, 2025



While achieving excellent results on various datasets, many deep learning methods for image deblurring suffer from limited generalization capabilities with out-of-domain data. This limitation is likely caused by their dependence on certain domain-specific datasets. To address this challenge, we argue that it is necessary to introduce the kernel prior into deep learning methods, as the kernel prior remains independent of the image context. For effective fusion of kernel prior information, we adopt a rational implementation method inspired by traditional deblurring algorithms that perform deconvolution in the frequency domain. We propose a module called Frequency Integration Module (FIM) for fusing the kernel prior and combine it with a frequency-based deblurring Transfomer network. Experimental results demonstrate that our method outperforms state-of-the-art methods on multiple blind image deblurring tasks, showcasing robust generalization abilities. Source code will be available soon.
Bokeh-Loss GAN: Multi-Stage Adversarial Training for Realistic Edge-Aware Bokeh
Aug 25, 2022
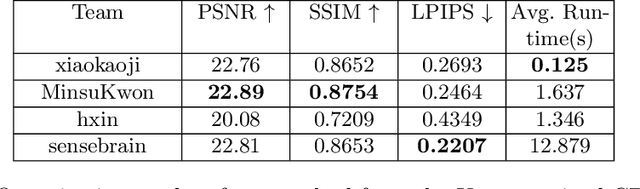
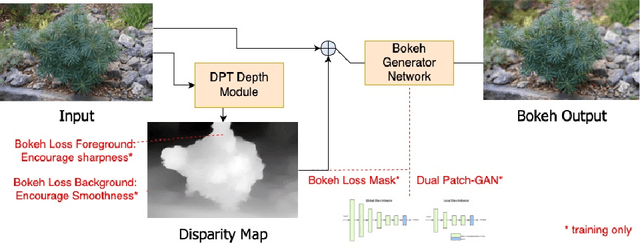
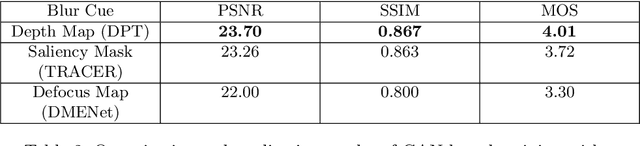
In this paper, we tackle the problem of monocular bokeh synthesis, where we attempt to render a shallow depth of field image from a single all-in-focus image. Unlike in DSLR cameras, this effect can not be captured directly in mobile cameras due to the physical constraints of the mobile aperture. We thus propose a network-based approach that is capable of rendering realistic monocular bokeh from single image inputs. To do this, we introduce three new edge-aware Bokeh Losses based on a predicted monocular depth map, that sharpens the foreground edges while blurring the background. This model is then finetuned using an adversarial loss to generate a realistic Bokeh effect. Experimental results show that our approach is capable of generating a pleasing, natural Bokeh effect with sharp edges while handling complicated scenes.
NTIRE 2022 Challenge on High Dynamic Range Imaging: Methods and Results
May 25, 2022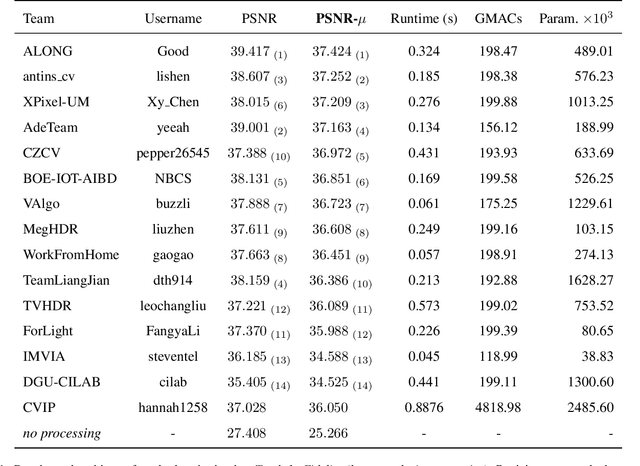
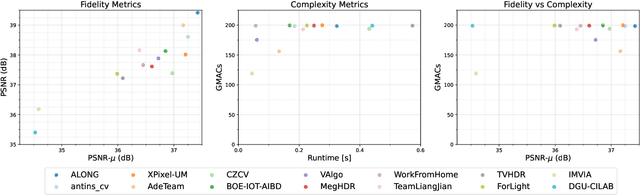
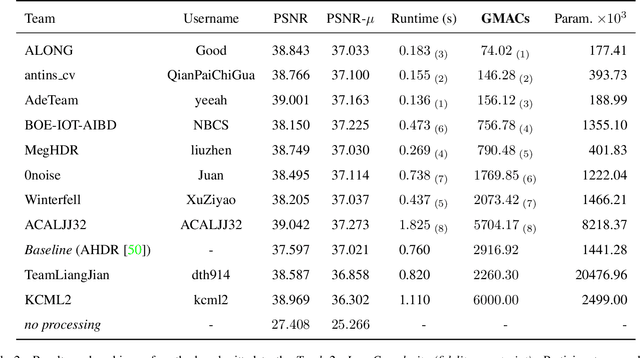
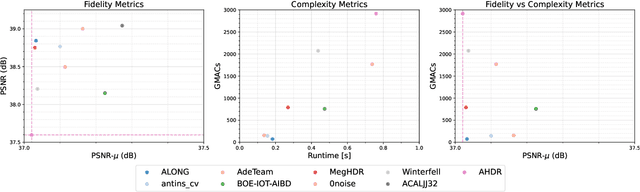
This paper reviews the challenge on constrained high dynamic range (HDR) imaging that was part of the New Trends in Image Restoration and Enhancement (NTIRE) workshop, held in conjunction with CVPR 2022. This manuscript focuses on the competition set-up, datasets, the proposed methods and their results. The challenge aims at estimating an HDR image from multiple respective low dynamic range (LDR) observations, which might suffer from under- or over-exposed regions and different sources of noise. The challenge is composed of two tracks with an emphasis on fidelity and complexity constraints: In Track 1, participants are asked to optimize objective fidelity scores while imposing a low-complexity constraint (i.e. solutions can not exceed a given number of operations). In Track 2, participants are asked to minimize the complexity of their solutions while imposing a constraint on fidelity scores (i.e. solutions are required to obtain a higher fidelity score than the prescribed baseline). Both tracks use the same data and metrics: Fidelity is measured by means of PSNR with respect to a ground-truth HDR image (computed both directly and with a canonical tonemapping operation), while complexity metrics include the number of Multiply-Accumulate (MAC) operations and runtime (in seconds).
* CVPR Workshops 2022. 15 pages, 21 figures, 2 tables
Semi-synthesis: A fast way to produce effective datasets for stereo matching
Jan 26, 2021
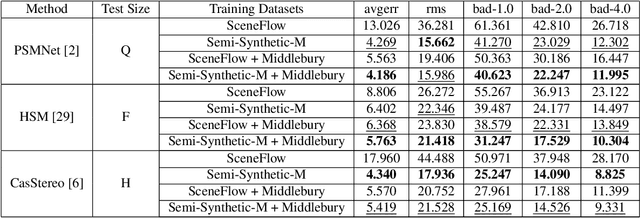

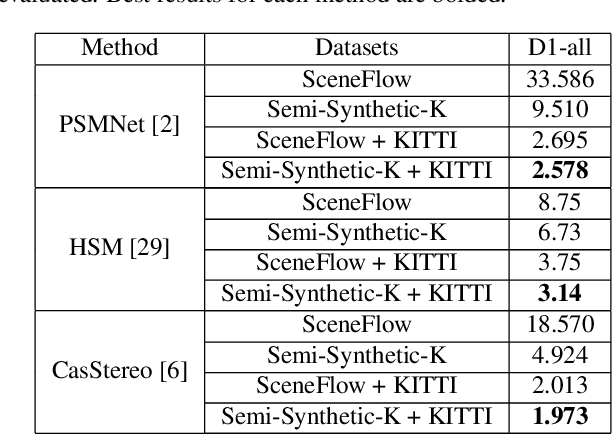
Stereo matching is an important problem in computer vision which has drawn tremendous research attention for decades. Recent years, data-driven methods with convolutional neural networks (CNNs) are continuously pushing stereo matching to new heights. However, data-driven methods require large amount of training data, which is not an easy task for real stereo data due to the annotation difficulties of per-pixel ground-truth disparity. Though synthetic dataset is proposed to fill the gaps of large data demand, the fine-tuning on real dataset is still needed due to the domain variances between synthetic data and real data. In this paper, we found that in synthetic datasets, close-to-real-scene texture rendering is a key factor to boost up stereo matching performance, while close-to-real-scene 3D modeling is less important. We then propose semi-synthetic, an effective and fast way to synthesize large amount of data with close-to-real-scene texture to minimize the gap between synthetic data and real data. Extensive experiments demonstrate that models trained with our proposed semi-synthetic datasets achieve significantly better performance than with general synthetic datasets, especially on real data benchmarks with limited training data. With further fine-tuning on the real dataset, we also achieve SOTA performance on Middlebury and competitive results on KITTI and ETH3D datasets.