 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSteering Prediction via a Multi-Sensor System for Autonomous Racing
Sep 28, 2024



Autonomous racing has rapidly gained research attention. Traditionally, racing cars rely on 2D LiDAR as their primary visual system. In this work, we explore the integration of an event camera with the existing system to provide enhanced temporal information. Our goal is to fuse the 2D LiDAR data with event data in an end-to-end learning framework for steering prediction, which is crucial for autonomous racing. To the best of our knowledge, this is the first study addressing this challenging research topic. We start by creating a multisensor dataset specifically for steering prediction. Using this dataset, we establish a benchmark by evaluating various SOTA fusion methods. Our observations reveal that existing methods often incur substantial computational costs. To address this, we apply low-rank techniques to propose a novel, efficient, and effective fusion design. We introduce a new fusion learning policy to guide the fusion process, enhancing robustness against misalignment. Our fusion architecture provides better steering prediction than LiDAR alone, significantly reducing the RMSE from 7.72 to 1.28. Compared to the second-best fusion method, our work represents only 11% of the learnable parameters while achieving better accuracy. The source code, dataset, and benchmark will be released to promote future research.
Alignment-free HDR Deghosting with Semantics Consistent Transformer
May 29, 2023



High dynamic range (HDR) imaging aims to retrieve information from multiple low-dynamic range inputs to generate realistic output. The essence is to leverage the contextual information, including both dynamic and static semantics, for better image generation. Existing methods often focus on the spatial misalignment across input frames caused by the foreground and/or camera motion. However, there is no research on jointly leveraging the dynamic and static context in a simultaneous manner. To delve into this problem, we propose a novel alignment-free network with a Semantics Consistent Transformer (SCTNet) with both spatial and channel attention modules in the network. The spatial attention aims to deal with the intra-image correlation to model the dynamic motion, while the channel attention enables the inter-image intertwining to enhance the semantic consistency across frames. Aside from this, we introduce a novel realistic HDR dataset with more variations in foreground objects, environmental factors, and larger motions. Extensive comparisons on both conventional datasets and ours validate the effectiveness of our method, achieving the best trade-off on the performance and the computational cost.
DSEC-MOS: Segment Any Moving Object with Moving Ego Vehicle
Apr 28, 2023



Moving Object Segmentation (MOS), a crucial task in computer vision, has numerous applications such as surveillance, autonomous driving, and video analytics. Existing datasets for moving object segmentation mainly focus on RGB or Lidar videos, but lack additional event information that can enhance the understanding of dynamic scenes. To address this limitation, we propose a novel dataset, called DSEC-MOS. Our dataset includes frames captured by RGB cameras embedded on moving vehicules and incorporates event data, which provide high temporal resolution and low-latency information about changes in the scenes. To generate accurate segmentation mask annotations for moving objects, we apply the recently emerged large model SAM - Segment Anything Model - with moving object bounding boxes from DSEC-MOD serving as prompts and calibrated RGB frames, then further revise the results. Our DSEC-MOS dataset contains in total 16 sequences (13314 images). To the best of our knowledge, DSEC-MOS is also the first moving object segmentation dataset that includes event camera in autonomous driving. Project Page: https://github.com/ZZY-Zhou/DSEC-MOS.
CEN-HDR: Computationally Efficient neural Network for real-time High Dynamic Range imaging
Feb 10, 2023



High dynamic range (HDR) imaging is still a challenging task in modern digital photography. Recent research proposes solutions that provide high-quality acquisition but at the cost of a very large number of operations and a slow inference time that prevent the implementation of these solutions on lightweight real-time systems. In this paper, we propose CEN-HDR, a new computationally efficient neural network by providing a novel architecture based on a light attention mechanism and sub-pixel convolution operations for real-time HDR imaging. We also provide an efficient training scheme by applying network compression using knowledge distillation. We performed extensive qualitative and quantitative comparisons to show that our approach produces competitive results in image quality while being faster than state-of-the-art solutions, allowing it to be practically deployed under real-time constraints. Experimental results show our method obtains a score of 43.04 mu-PSNR on the Kalantari2017 dataset with a framerate of 33 FPS using a Macbook M1 NPU.
RGB-Event Fusion for Moving Object Detection in Autonomous Driving
Sep 17, 2022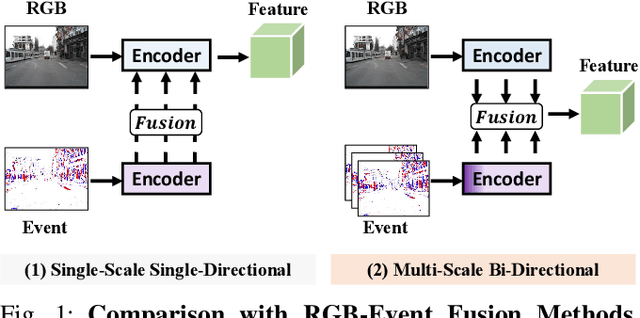
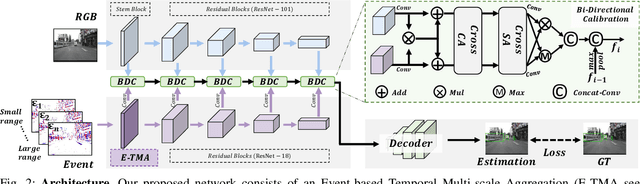
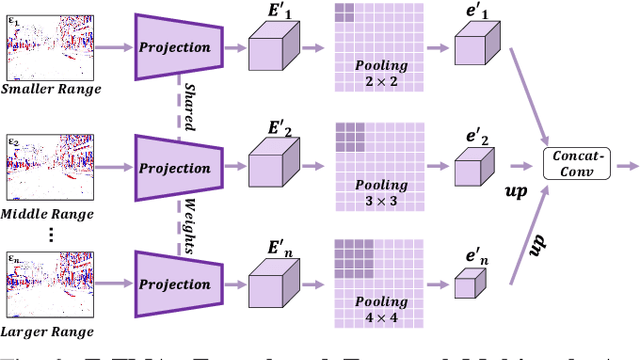
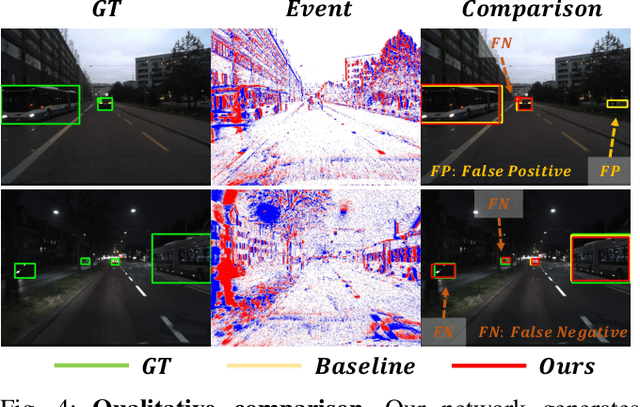
Moving Object Detection (MOD) is a critical vision task for successfully achieving safe autonomous driving. Despite plausible results of deep learning methods, most existing approaches are only frame-based and may fail to reach reasonable performance when dealing with dynamic traffic participants. Recent advances in sensor technologies, especially the Event camera, can naturally complement the conventional camera approach to better model moving objects. However, event-based works often adopt a pre-defined time window for event representation, and simply integrate it to estimate image intensities from events, neglecting much of the rich temporal information from the available asynchronous events. Therefore, from a new perspective, we propose RENet, a novel RGB-Event fusion Network, that jointly exploits the two complementary modalities to achieve more robust MOD under challenging scenarios for autonomous driving. Specifically, we first design a temporal multi-scale aggregation module to fully leverage event frames from both the RGB exposure time and larger intervals. Then we introduce a bi-directional fusion module to attentively calibrate and fuse multi-modal features. To evaluate the performance of our network, we carefully select and annotate a sub-MOD dataset from the commonly used DSEC dataset. Extensive experiments demonstrate that our proposed method performs significantly better than the state-of-the-art RGB-Event fusion alternatives.
NTIRE 2022 Challenge on High Dynamic Range Imaging: Methods and Results
May 25, 2022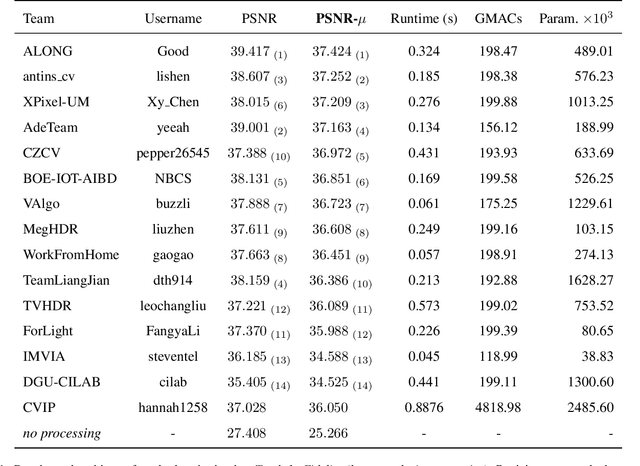
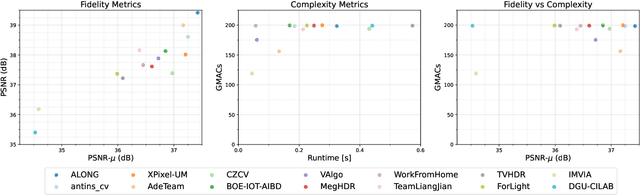
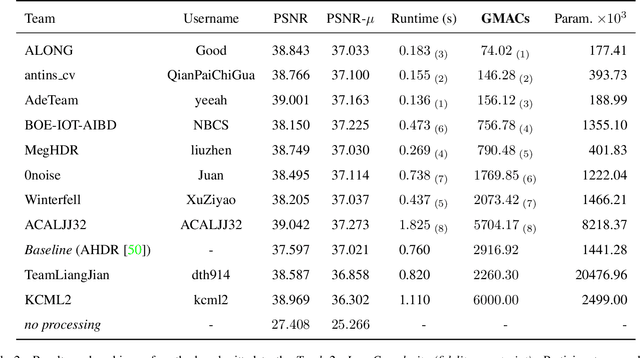
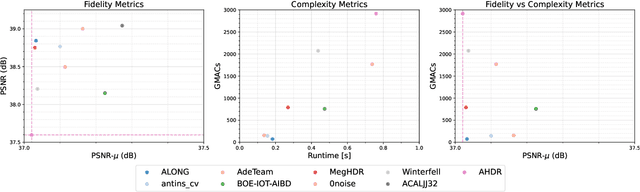
This paper reviews the challenge on constrained high dynamic range (HDR) imaging that was part of the New Trends in Image Restoration and Enhancement (NTIRE) workshop, held in conjunction with CVPR 2022. This manuscript focuses on the competition set-up, datasets, the proposed methods and their results. The challenge aims at estimating an HDR image from multiple respective low dynamic range (LDR) observations, which might suffer from under- or over-exposed regions and different sources of noise. The challenge is composed of two tracks with an emphasis on fidelity and complexity constraints: In Track 1, participants are asked to optimize objective fidelity scores while imposing a low-complexity constraint (i.e. solutions can not exceed a given number of operations). In Track 2, participants are asked to minimize the complexity of their solutions while imposing a constraint on fidelity scores (i.e. solutions are required to obtain a higher fidelity score than the prescribed baseline). Both tracks use the same data and metrics: Fidelity is measured by means of PSNR with respect to a ground-truth HDR image (computed both directly and with a canonical tonemapping operation), while complexity metrics include the number of Multiply-Accumulate (MAC) operations and runtime (in seconds).
* CVPR Workshops 2022. 15 pages, 21 figures, 2 tables
Deep Learning methods for automatic evaluation of delayed enhancement-MRI. The results of the EMIDEC challenge
Aug 10, 2021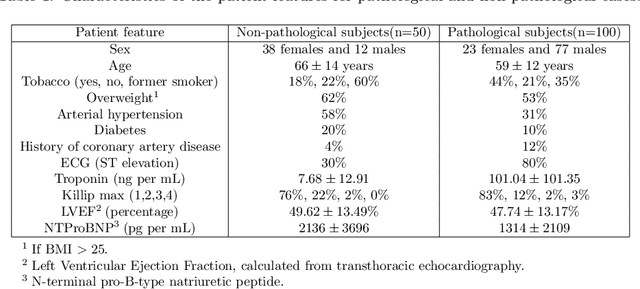

A key factor for assessing the state of the heart after myocardial infarction (MI) is to measure whether the myocardium segment is viable after reperfusion or revascularization therapy. Delayed enhancement-MRI or DE-MRI, which is performed several minutes after injection of the contrast agent, provides high contrast between viable and nonviable myocardium and is therefore a method of choice to evaluate the extent of MI. To automatically assess myocardial status, the results of the EMIDEC challenge that focused on this task are presented in this paper. The challenge's main objectives were twofold. First, to evaluate if deep learning methods can distinguish between normal and pathological cases. Second, to automatically calculate the extent of myocardial infarction. The publicly available database consists of 150 exams divided into 50 cases with normal MRI after injection of a contrast agent and 100 cases with myocardial infarction (and then with a hyperenhanced area on DE-MRI), whatever their inclusion in the cardiac emergency department. Along with MRI, clinical characteristics are also provided. The obtained results issued from several works show that the automatic classification of an exam is a reachable task (the best method providing an accuracy of 0.92), and the automatic segmentation of the myocardium is possible. However, the segmentation of the diseased area needs to be improved, mainly due to the small size of these areas and the lack of contrast with the surrounding structures.
ACDnet: An action detection network for real-time edge computing based on flow-guided feature approximation and memory aggregation
Feb 26, 2021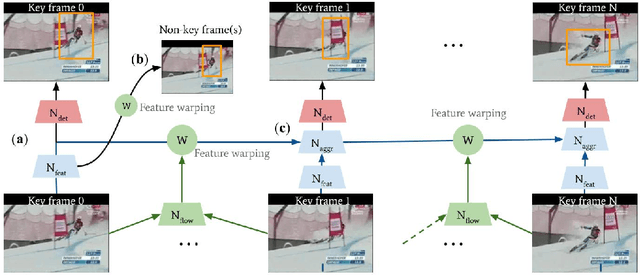
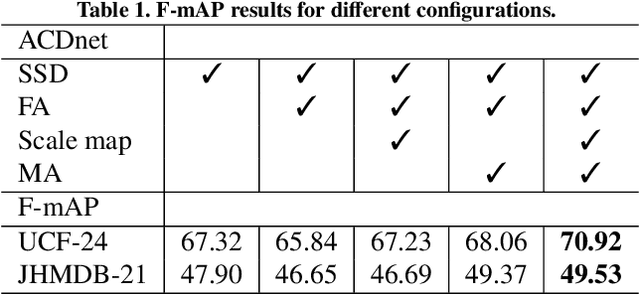
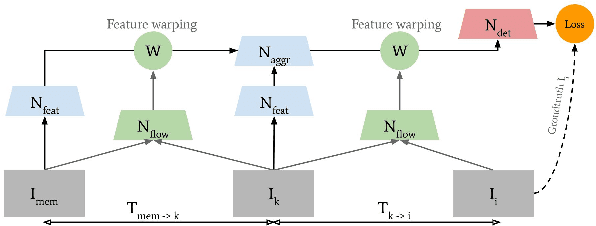
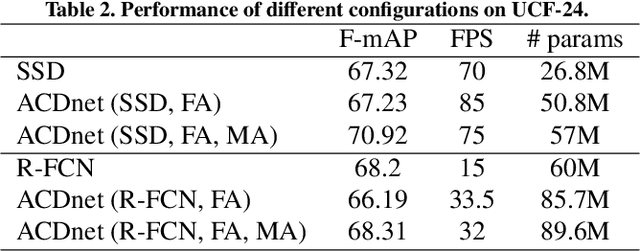
Interpreting human actions requires understanding the spatial and temporal context of the scenes. State-of-the-art action detectors based on Convolutional Neural Network (CNN) have demonstrated remarkable results by adopting two-stream or 3D CNN architectures. However, these methods typically operate in a non-real-time, ofline fashion due to system complexity to reason spatio-temporal information. Consequently, their high computational cost is not compliant with emerging real-world scenarios such as service robots or public surveillance where detection needs to take place at resource-limited edge devices. In this paper, we propose ACDnet, a compact action detection network targeting real-time edge computing which addresses both efficiency and accuracy. It intelligently exploits the temporal coherence between successive video frames to approximate their CNN features rather than naively extracting them. It also integrates memory feature aggregation from past video frames to enhance current detection stability, implicitly modeling long temporal cues over time. Experiments conducted on the public benchmark datasets UCF-24 and JHMDB-21 demonstrate that ACDnet, when integrated with the SSD detector, can robustly achieve detection well above real-time (75 FPS). At the same time, it retains reasonable accuracy (70.92 and 49.53 frame mAP) compared to other top-performing methods using far heavier configurations. Codes will be available at https://github.com/dginhac/ACDnet.
* Accepted for publication in Pattern Recognition Letters
Design and Implementation a 8 bits Pipeline Analog to Digital Converter in the Technology 0.6 μm CMOS Process
Aug 04, 2008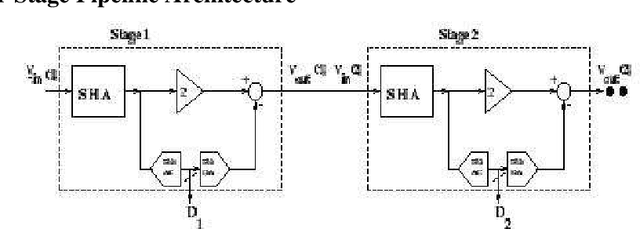
This paper describes a 8 bits, 20 Msamples/s pipeline analog-to-digital converter implemented in 0.6 \mu m CMOS technology with a total power dissipation of 75.47 mW. Circuit techniques used include a precise comparator, operational amplifier and clock management. A switched capacitor is used to sample and multiplying at each stage. Simulation a worst case DNL and INL of 0.75 LSB. The design operate at 5 V dc. The ADC achieves a SNDR of 44.86 dB. keywords : pipeline, switched capacitor, clock management