 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmnilingual ASR: Open-Source Multilingual Speech Recognition for 1600+ Languages
Nov 12, 2025



Automatic speech recognition (ASR) has advanced in high-resource languages, but most of the world's 7,000+ languages remain unsupported, leaving thousands of long-tail languages behind. Expanding ASR coverage has been costly and limited by architectures that restrict language support, making extension inaccessible to most--all while entangled with ethical concerns when pursued without community collaboration. To transcend these limitations, we introduce Omnilingual ASR, the first large-scale ASR system designed for extensibility. Omnilingual ASR enables communities to introduce unserved languages with only a handful of data samples. It scales self-supervised pre-training to 7B parameters to learn robust speech representations and introduces an encoder-decoder architecture designed for zero-shot generalization, leveraging a LLM-inspired decoder. This capability is grounded in a massive and diverse training corpus; by combining breadth of coverage with linguistic variety, the model learns representations robust enough to adapt to unseen languages. Incorporating public resources with community-sourced recordings gathered through compensated local partnerships, Omnilingual ASR expands coverage to over 1,600 languages, the largest such effort to date--including over 500 never before served by ASR. Automatic evaluations show substantial gains over prior systems, especially in low-resource conditions, and strong generalization. We release Omnilingual ASR as a family of models, from 300M variants for low-power devices to 7B for maximum accuracy. We reflect on the ethical considerations shaping this design and conclude by discussing its societal impact. In particular, we highlight how open-sourcing models and tools can lower barriers for researchers and communities, inviting new forms of participation. Open-source artifacts are available at https://github.com/facebookresearch/omnilingual-asr.
Effects of Speaker Count, Duration, and Accent Diversity on Zero-Shot Accent Robustness in Low-Resource ASR
Jun 04, 2025



To build an automatic speech recognition (ASR) system that can serve everyone in the world, the ASR needs to be robust to a wide range of accents including unseen accents. We systematically study how three different variables in training data -- the number of speakers, the audio duration per each individual speaker, and the diversity of accents -- affect ASR robustness towards unseen accents in a low-resource training regime. We observe that for a fixed number of ASR training hours, it is more beneficial to increase the number of speakers (which means each speaker contributes less) than the number of hours contributed per speaker. We also observe that more speakers enables ASR performance gains from scaling number of hours. Surprisingly, we observe minimal benefits to prioritizing speakers with different accents when the number of speakers is controlled. Our work suggests that practitioners should prioritize increasing the speaker count in ASR training data composition for new languages.
Improving Multilingual ASR in the Wild Using Simple N-best Re-ranking
Sep 27, 2024



Multilingual Automatic Speech Recognition (ASR) models are typically evaluated in a setting where the ground-truth language of the speech utterance is known, however, this is often not the case for most practical settings. Automatic Spoken Language Identification (SLID) models are not perfect and misclassifications have a substantial impact on the final ASR accuracy. In this paper, we present a simple and effective N-best re-ranking approach to improve multilingual ASR accuracy for several prominent acoustic models by employing external features such as language models and text-based language identification models. Our results on FLEURS using the MMS and Whisper models show spoken language identification accuracy improvements of 8.7% and 6.1%, respectively and word error rates which are 3.3% and 2.0% lower on these benchmarks.
Scaling A Simple Approach to Zero-Shot Speech Recognition
Jul 25, 2024



Despite rapid progress in increasing the language coverage of automatic speech recognition, the field is still far from covering all languages with a known writing script. Recent work showed promising results with a zero-shot approach requiring only a small amount of text data, however, accuracy heavily depends on the quality of the used phonemizer which is often weak for unseen languages. In this paper, we present MMS Zero-shot a conceptually simpler approach based on romanization and an acoustic model trained on data in 1,078 different languages or three orders of magnitude more than prior art. MMS Zero-shot reduces the average character error rate by a relative 46% over 100 unseen languages compared to the best previous work. Moreover, the error rate of our approach is only 2.5x higher compared to in-domain supervised baselines, while our approach uses no labeled data for the evaluation languages at all.
Toward Joint Language Modeling for Speech Units and Text
Oct 12, 2023



Speech and text are two major forms of human language. The research community has been focusing on mapping speech to text or vice versa for many years. However, in the field of language modeling, very little effort has been made to model them jointly. In light of this, we explore joint language modeling for speech units and text. Specifically, we compare different speech tokenizers to transform continuous speech signals into discrete units and use different methods to construct mixed speech-text data. We introduce automatic metrics to evaluate how well the joint LM mixes speech and text. We also fine-tune the LM on downstream spoken language understanding (SLU) tasks with different modalities (speech or text) and test its performance to assess the model's learning of shared representations. Our results show that by mixing speech units and text with our proposed mixing techniques, the joint LM improves over a speech-only baseline on SLU tasks and shows zero-shot cross-modal transferability.
Scaling Speech Technology to 1,000+ Languages
May 22, 2023Expanding the language coverage of speech technology has the potential to improve access to information for many more people. However, current speech technology is restricted to about one hundred languages which is a small fraction of the over 7,000 languages spoken around the world. The Massively Multilingual Speech (MMS) project increases the number of supported languages by 10-40x, depending on the task. The main ingredients are a new dataset based on readings of publicly available religious texts and effectively leveraging self-supervised learning. We built pre-trained wav2vec 2.0 models covering 1,406 languages, a single multilingual automatic speech recognition model for 1,107 languages, speech synthesis models for the same number of languages, as well as a language identification model for 4,017 languages. Experiments show that our multilingual speech recognition model more than halves the word error rate of Whisper on 54 languages of the FLEURS benchmark while being trained on a small fraction of the labeled data.
DinoSR: Self-Distillation and Online Clustering for Self-supervised Speech Representation Learning
May 17, 2023



In this paper, we introduce self-distillation and online clustering for self-supervised speech representation learning (DinoSR) which combines masked language modeling, self-distillation, and online clustering. We show that these concepts complement each other and result in a strong representation learning model for speech. DinoSR first extracts contextualized embeddings from the input audio with a teacher network, then runs an online clustering system on the embeddings to yield a machine-discovered phone inventory, and finally uses the discretized tokens to guide a student network. We show that DinoSR surpasses previous state-of-the-art performance in several downstream tasks, and provide a detailed analysis of the model and the learned discrete units. The source code will be made available after the anonymity period.
AV-data2vec: Self-supervised Learning of Audio-Visual Speech Representations with Contextualized Target Representations
Feb 10, 2023Self-supervision has shown great potential for audio-visual speech recognition by vastly reducing the amount of labeled data required to build good systems. However, existing methods are either not entirely end-to-end or do not train joint representations of both modalities. In this paper, we introduce AV-data2vec which addresses these challenges and builds audio-visual representations based on predicting contextualized representations which has been successful in the uni-modal case. The model uses a shared transformer encoder for both audio and video and can combine both modalities to improve speech recognition. Results on LRS3 show that AV-data2vec consistently outperforms existing methods under most settings.
Efficient Self-supervised Learning with Contextualized Target Representations for Vision, Speech and Language
Dec 14, 2022



Current self-supervised learning algorithms are often modality-specific and require large amounts of computational resources. To address these issues, we increase the training efficiency of data2vec, a learning objective that generalizes across several modalities. We do not encode masked tokens, use a fast convolutional decoder and amortize the effort to build teacher representations. data2vec 2.0 benefits from the rich contextualized target representations introduced in data2vec which enable a fast self-supervised learner. Experiments on ImageNet-1K image classification show that data2vec 2.0 matches the accuracy of Masked Autoencoders in 16.4x lower pre-training time, on Librispeech speech recognition it performs as well as wav2vec 2.0 in 10.6x less time, and on GLUE natural language understanding it matches a retrained RoBERTa model in half the time. Trading some speed for accuracy results in ImageNet-1K top-1 accuracy of 86.8\% with a ViT-L model trained for 150 epochs.
Simple and Effective Unsupervised Speech Translation
Oct 18, 2022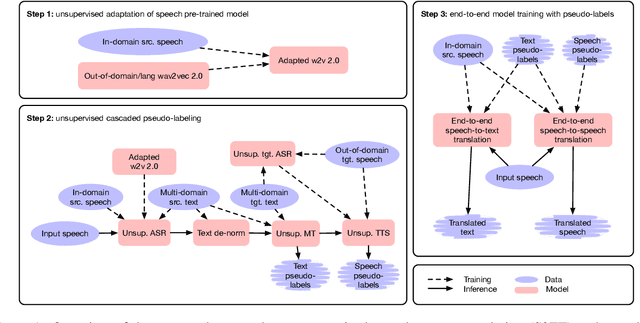
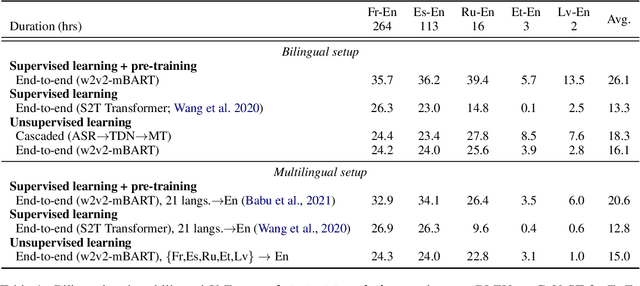
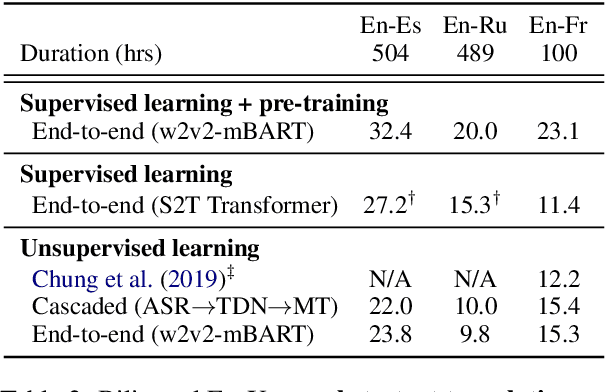
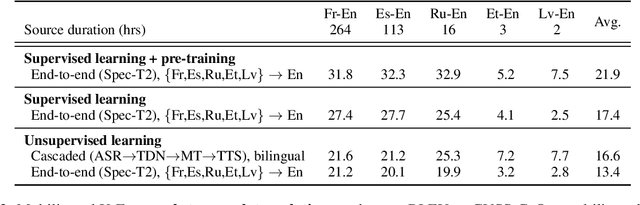
The amount of labeled data to train models for speech tasks is limited for most languages, however, the data scarcity is exacerbated for speech translation which requires labeled data covering two different languages. To address this issue, we study a simple and effective approach to build speech translation systems without labeled data by leveraging recent advances in unsupervised speech recognition, machine translation and speech synthesis, either in a pipeline approach, or to generate pseudo-labels for training end-to-end speech translation models. Furthermore, we present an unsupervised domain adaptation technique for pre-trained speech models which improves the performance of downstream unsupervised speech recognition, especially for low-resource settings. Experiments show that unsupervised speech-to-text translation outperforms the previous unsupervised state of the art by 3.2 BLEU on the Libri-Trans benchmark, on CoVoST 2, our best systems outperform the best supervised end-to-end models (without pre-training) from only two years ago by an average of 5.0 BLEU over five X-En directions. We also report competitive results on MuST-C and CVSS benchmarks.