 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompSplat: Compression-aware 3D Gaussian Splatting for Real-world Video
Feb 10, 2026High-quality novel view synthesis (NVS) from real-world videos is crucial for applications such as cultural heritage preservation, digital twins, and immersive media. However, real-world videos typically contain long sequences with irregular camera trajectories and unknown poses, leading to pose drift, feature misalignment, and geometric distortion during reconstruction. Moreover, lossy compression amplifies these issues by introducing inconsistencies that gradually degrade geometry and rendering quality. While recent studies have addressed either long-sequence NVS or unposed reconstruction, compression-aware approaches still focus on specific artifacts or limited scenarios, leaving diverse compression patterns in long videos insufficiently explored. In this paper, we propose CompSplat, a compression-aware training framework that explicitly models frame-wise compression characteristics to mitigate inter-frame inconsistency and accumulated geometric errors. CompSplat incorporates compression-aware frame weighting and an adaptive pruning strategy to enhance robustness and geometric consistency, particularly under heavy compression. Extensive experiments on challenging benchmarks, including Tanks and Temples, Free, and Hike, demonstrate that CompSplat achieves state-of-the-art rendering quality and pose accuracy, significantly surpassing most recent state-of-the-art NVS approaches under severe compression conditions.
G2P: Gaussian-to-Point Attribute Alignment for Boundary-Aware 3D Semantic Segmentation
Jan 07, 2026Semantic segmentation on point clouds is critical for 3D scene understanding. However, sparse and irregular point distributions provide limited appearance evidence, making geometry-only features insufficient to distinguish objects with similar shapes but distinct appearances (e.g., color, texture, material). We propose Gaussian-to-Point (G2P), which transfers appearance-aware attributes from 3D Gaussian Splatting to point clouds for more discriminative and appearance-consistent segmentation. Our G2P address the misalignment between optimized Gaussians and original point geometry by establishing point-wise correspondences. By leveraging Gaussian opacity attributes, we resolve the geometric ambiguity that limits existing models. Additionally, Gaussian scale attributes enable precise boundary localization in complex 3D scenes. Extensive experiments demonstrate that our approach achieves superior performance on standard benchmarks and shows significant improvements on geometrically challenging classes, all without any 2D or language supervision.
AAPL: Adding Attributes to Prompt Learning for Vision-Language Models
Apr 25, 2024



Recent advances in large pre-trained vision-language models have demonstrated remarkable performance on zero-shot downstream tasks. Building upon this, recent studies, such as CoOp and CoCoOp, have proposed the use of prompt learning, where context within a prompt is replaced with learnable vectors, leading to significant improvements over manually crafted prompts. However, the performance improvement for unseen classes is still marginal, and to tackle this problem, data augmentation has been frequently used in traditional zero-shot learning techniques. Through our experiments, we have identified important issues in CoOp and CoCoOp: the context learned through traditional image augmentation is biased toward seen classes, negatively impacting generalization to unseen classes. To address this problem, we propose adversarial token embedding to disentangle low-level visual augmentation features from high-level class information when inducing bias in learnable prompts. Through our novel mechanism called "Adding Attributes to Prompt Learning", AAPL, we guide the learnable context to effectively extract text features by focusing on high-level features for unseen classes. We have conducted experiments across 11 datasets, and overall, AAPL shows favorable performances compared to the existing methods in few-shot learning, zero-shot learning, cross-dataset, and domain generalization tasks.
NTIRE 2022 Challenge on High Dynamic Range Imaging: Methods and Results
May 25, 2022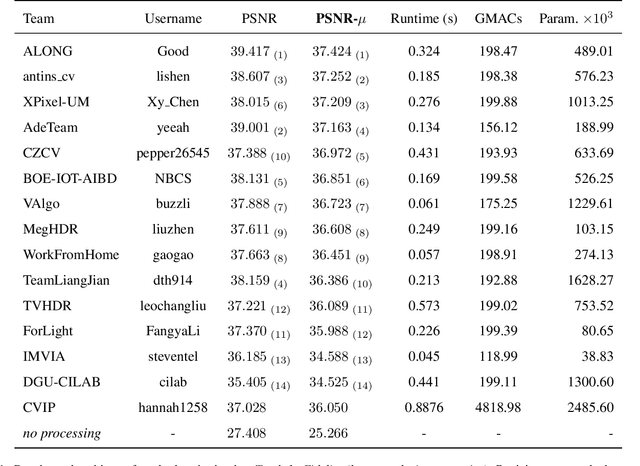
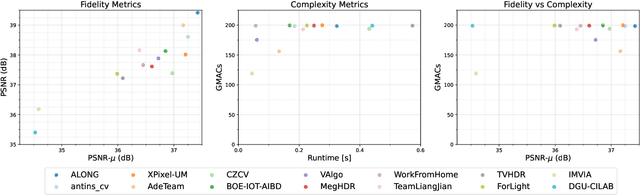
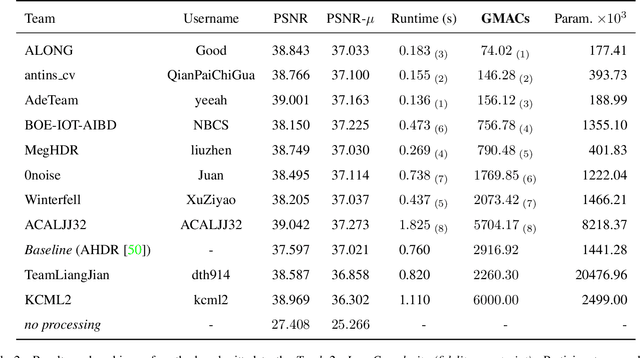
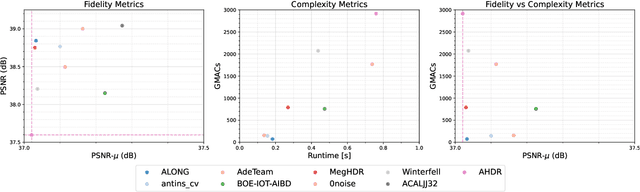
This paper reviews the challenge on constrained high dynamic range (HDR) imaging that was part of the New Trends in Image Restoration and Enhancement (NTIRE) workshop, held in conjunction with CVPR 2022. This manuscript focuses on the competition set-up, datasets, the proposed methods and their results. The challenge aims at estimating an HDR image from multiple respective low dynamic range (LDR) observations, which might suffer from under- or over-exposed regions and different sources of noise. The challenge is composed of two tracks with an emphasis on fidelity and complexity constraints: In Track 1, participants are asked to optimize objective fidelity scores while imposing a low-complexity constraint (i.e. solutions can not exceed a given number of operations). In Track 2, participants are asked to minimize the complexity of their solutions while imposing a constraint on fidelity scores (i.e. solutions are required to obtain a higher fidelity score than the prescribed baseline). Both tracks use the same data and metrics: Fidelity is measured by means of PSNR with respect to a ground-truth HDR image (computed both directly and with a canonical tonemapping operation), while complexity metrics include the number of Multiply-Accumulate (MAC) operations and runtime (in seconds).
* CVPR Workshops 2022. 15 pages, 21 figures, 2 tables