 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREViT: Roto-reflection Equivariant Convolutional Vision Transformer
Jun 24, 2026In this paper, we propose a discrete roto-reflection group equivariant vision transformer with convolutional attention. Roto-reflection equivariant networks preserve the rotational, flip and positional symmetry in feature maps, making them useful for tasks where orientation of the inputs is relevant to the model outputs. In image classification and object detection, most of the studies on roto-reflection equivariant models have focused on using convolutional neural networks rather than vision transformers. In this paper, we examine the challenges involved in achieving equivariance in vision transformers, and we propose a simpler way to implement a discretized roto-reflection group equivariant vision transformer. The experimental results demonstrate that our approach outperforms the existing approaches for developing discrete roto-reflection group equivariant neural networks for image classification.
ErA: Error-Aware Deep Unrolling Network for Single Image Defocus Deblurring
Jun 04, 2026We introduce ErA (Error-Aware Deep Unrolling Network), an end-to-end frame work for single-image defocus deblurring. ErA jointly learns a compact kerne basis and per-pixel weights, while an error-aware term in Augmented Lagrangian unrolling corrects kernel estimation errors via alternating updates and ResUNet denoisers. It achieves state-of-the-art PSNR/SSIM on DPDD, RealDOF, and RTF, and shows strong generalization on CUHK without ground truth.
Drift-Augmented Scoring: Text-Derived Noise Robustness for Zero-Shot Audio-Language Classification
Jun 03, 2026Contrastive audio-language models such as CLAP enable zero-shot audio classification: a sound is labelled by matching its embedding to text prompt embeddings, with no labelled audio. This matching breaks down under acoustic noise, where accuracy and mAP fall by 12-30 percentage points at 0 dB SNR on standard benchmarks. We propose Drift Augmented Scoring (DAS), a small per-class bonus added to the cosine score. The bonus rewards a class when the noisy audio embedding drifts in the direction that the class's noise-conditioned text prompts predict. It is derived from text alone, computed once and cached, and adds a single inner product per class at inference, with no gradients and no test-time batch. On a LAION CLAP backbone, we compare DAS against the four variants of Acevedo et al.'s concurrent method on UrbanSound8K and the full FSD50K eval set, mixing each clip with urban acoustic scene noise across a range of SNRs. DAS improves the metric on every test condition: by +2.60 to +5.75 accuracy points on UrbanSound8K and +1.50 to +1.74 mAP points on FSD50K.
Deep Joint Unrolling for Deblurring and Low-Light Image Enhancement (JUDE).pdf
Dec 10, 2024



Low-light and blurring issues are prevalent when capturing photos at night, often due to the use of long exposure to address dim environments. Addressing these joint problems can be challenging and error-prone if an end-to-end model is trained without incorporating an appropriate physical model. In this paper, we introduce JUDE, a Deep Joint Unrolling for Deblurring and Low-Light Image Enhancement, inspired by the image physical model. Based on Retinex theory and the blurring model, the low-light blurry input is iteratively deblurred and decomposed, producing sharp low-light reflectance and illuminance through an unrolling mechanism. Additionally, we incorporate various modules to estimate the initial blur kernel, enhance brightness, and eliminate noise in the final image. Comprehensive experiments on LOL-Blur and Real-LOL-Blur demonstrate that our method outperforms existing techniques both quantitatively and qualitatively.
* 10 pages
Meent: Differentiable Electromagnetic Simulator for Machine Learning
Jun 11, 2024



Electromagnetic (EM) simulation plays a crucial role in analyzing and designing devices with sub-wavelength scale structures such as solar cells, semiconductor devices, image sensors, future displays and integrated photonic devices. Specifically, optics problems such as estimating semiconductor device structures and designing nanophotonic devices provide intriguing research topics with far-reaching real world impact. Traditional algorithms for such tasks require iteratively refining parameters through simulations, which often yield sub-optimal results due to the high computational cost of both the algorithms and EM simulations. Machine learning (ML) emerged as a promising candidate to mitigate these challenges, and optics research community has increasingly adopted ML algorithms to obtain results surpassing classical methods across various tasks. To foster a synergistic collaboration between the optics and ML communities, it is essential to have an EM simulation software that is user-friendly for both research communities. To this end, we present Meent, an EM simulation software that employs rigorous coupled-wave analysis (RCWA). Developed in Python and equipped with automatic differentiation (AD) capabilities, Meent serves as a versatile platform for integrating ML into optics research and vice versa. To demonstrate its utility as a research platform, we present three applications of Meent: 1) generating a dataset for training neural operator, 2) serving as an environment for the reinforcement learning of nanophotonic device optimization, and 3) providing a solution for inverse problems with gradient-based optimizers. These applications highlight Meent's potential to advance both EM simulation and ML methodologies. The code is available at https://github.com/kc-ml2/meent with the MIT license to promote the cross-polinations of ideas among academic researchers and industry practitioners.
NTIRE 2022 Challenge on High Dynamic Range Imaging: Methods and Results
May 25, 2022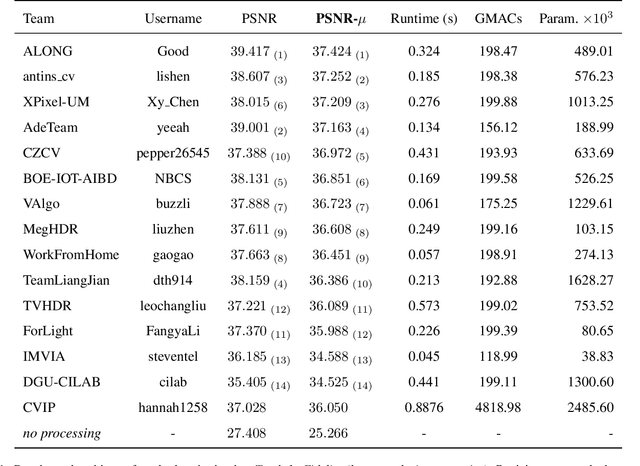
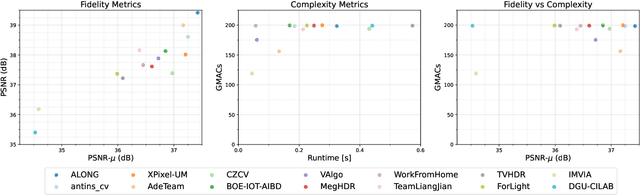
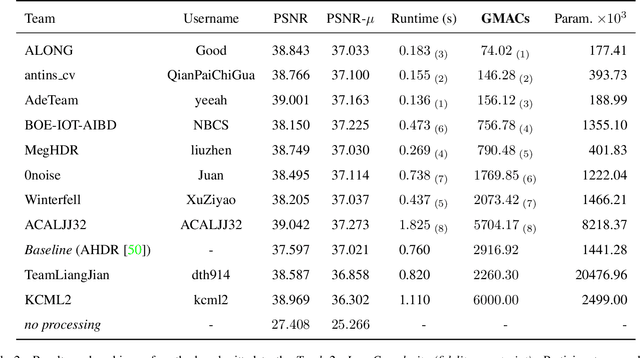
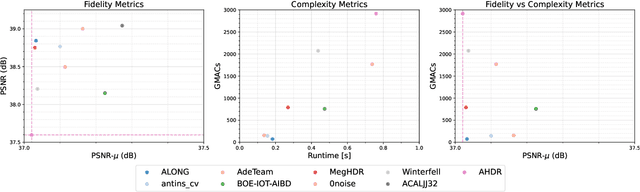
This paper reviews the challenge on constrained high dynamic range (HDR) imaging that was part of the New Trends in Image Restoration and Enhancement (NTIRE) workshop, held in conjunction with CVPR 2022. This manuscript focuses on the competition set-up, datasets, the proposed methods and their results. The challenge aims at estimating an HDR image from multiple respective low dynamic range (LDR) observations, which might suffer from under- or over-exposed regions and different sources of noise. The challenge is composed of two tracks with an emphasis on fidelity and complexity constraints: In Track 1, participants are asked to optimize objective fidelity scores while imposing a low-complexity constraint (i.e. solutions can not exceed a given number of operations). In Track 2, participants are asked to minimize the complexity of their solutions while imposing a constraint on fidelity scores (i.e. solutions are required to obtain a higher fidelity score than the prescribed baseline). Both tracks use the same data and metrics: Fidelity is measured by means of PSNR with respect to a ground-truth HDR image (computed both directly and with a canonical tonemapping operation), while complexity metrics include the number of Multiply-Accumulate (MAC) operations and runtime (in seconds).
* CVPR Workshops 2022. 15 pages, 21 figures, 2 tables
GMAC: A Distributional Perspective on Actor-Critic Framework
May 24, 2021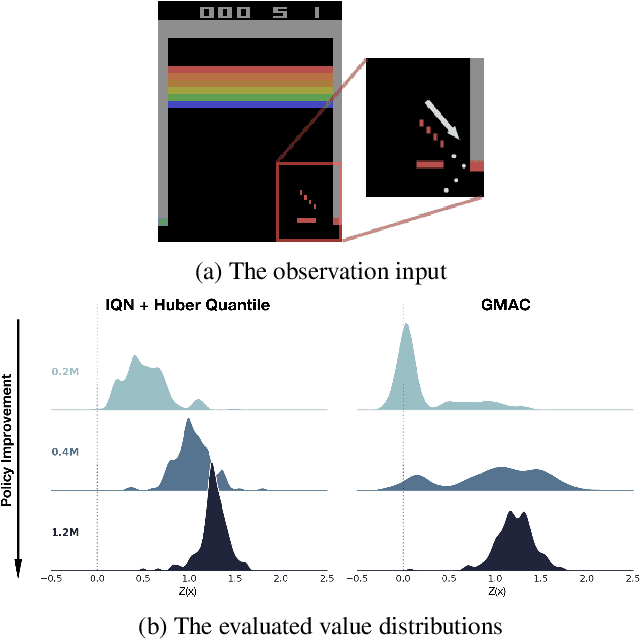
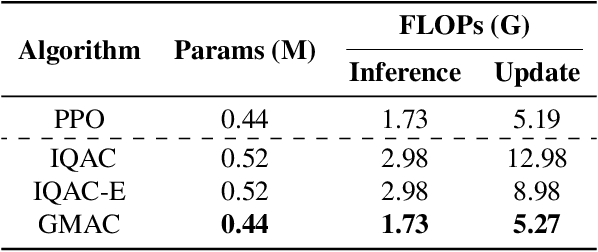
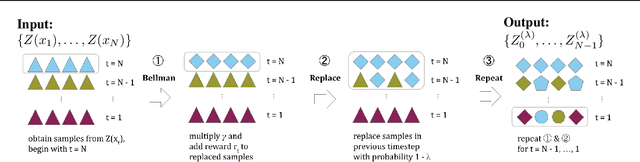

In this paper, we devise a distributional framework on actor-critic as a solution to distributional instability, action type restriction, and conflation between samples and statistics. We propose a new method that minimizes the Cram\'er distance with the multi-step Bellman target distribution generated from a novel Sample-Replacement algorithm denoted SR($\lambda$), which learns the correct value distribution under multiple Bellman operations. Parameterizing a value distribution with Gaussian Mixture Model further improves the efficiency and the performance of the method, which we name GMAC. We empirically show that GMAC captures the correct representation of value distributions and improves the performance of a conventional actor-critic method with low computational cost, in both discrete and continuous action spaces using Arcade Learning Environment (ALE) and PyBullet environment.