 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVISA: VLM-Guided Instance Semantic Auditing for 3D Occupancy World Models
Jun 11, 2026Semantic 3D occupancy provides a voxelized world state for autonomous driving and robot decision making, but object and rare-class errors can affect free-space interpretation, collision checking, and temporal state propagation. We show that a common VLM strategy, aligning 3D voxel or object features with crop-caption embeddings, improves text-space similarity without reliably improving closed-set occupancy mIoU. Motivated by this mismatch, we propose VISA, a training-time semantic auditing approach for existing occupancy world models. VISA queries an offline VLM on a representative crop of each physical object instance, obtains a structured audit with class hypotheses, plausible confusions, reliability, attributes, and evidence, and propagates it along the object track. The audit is grounded to matched 3D object voxels and distilled into semantic logits through reliability-weighted taxonomy, attribute-factor, and scene-level audit graph losses, while inference remains unchanged and requires no VLM. On nuScenes, averaged across three runs, VISA improves OccWorld from 19.06 to 20.05 mIoU and GaussianWorld from 21.36 to 21.91 mIoU; on GaussianWorld, object mIoU improves from 18.18 to 19.16 and rare-class mIoU from 15.60 to 16.79. These results suggest that VLMs are better suited to closed-set occupancy as reliability-aware semantic auditors than as generic caption-embedding targets.
Reformulate LLM Reinforcement Learning for Efficient Training under Black-box Discrepancy
Jun 09, 2026Reinforcement Learning (RL) has emerged as a pivotal post-training paradigm, yet it frequently suffers from unpredictable sub-optimum performance or even training collapses. Recent findings attribute these failures to a hidden train-inference discrepancy (or mismatch), stemming from the disparate underlying engines and architecture. We find that the training policy can actively self-correct such a discrepancy when provided with an appropriate learning signal. Then, we further empirically identify a discrepancy tolerance region: within this region, aggressively narrowing the discrepancy can suppress policy exploration and reduce learning efficiency, whereas outside this region, reducing excessive discrepancy improves optimization consistency and raises the achievable local performance ceiling. According to such findings, we formulate this problem as a Discrepancy-Constrained Markov Decision Process (DCMDP), where reward maximization is coupled with a constraint that aligns training-Inference behavior, achieving stable dual-objective optimization. To adaptively balance performance improvement and discrepancy control, we introduce a Lagrangian relaxation mechanism that dynamically adjusts the relative weight of the two objectives according to the current degree of discrepancy violation. This enables stable dual-objective optimization: the policy is allowed to explore freely within the tolerance region, while being guided back when the discrepancy exceeds the safe boundary. Empirically, DCMDP significantly improves the performance of 8B dense model (Qwen-3-8b) and 30B Mixture-of-Expert model (Qwen-3-30bA3b), and enables a heterogeneous training paradigm, where LLMs can be optimized in high-fidelity training setup while being explicitly aligned for low-cost, resource-constrained inference deployment.
GaussianSSC: Triplane-Guided Directional Gaussian Fields for 3D Semantic Completion
Mar 23, 2026We present \emph{GaussianSSC}, a two-stage, grid-native and triplane-guided approach to semantic scene completion (SSC) that injects the benefits of Gaussians without replacing the voxel grid or maintaining a separate Gaussian set. We introduce \emph{Gaussian Anchoring}, a sub-pixel, Gaussian-weighted image aggregation over fused FPN features that tightens voxel--image alignment and improves monocular occupancy estimation. We further convert point-like voxel features into a learned per-voxel Gaussian field and refine triplane features via a triplane-aligned \emph{Gaussian--Triplane Refinement} module that combines \emph{local gathering} (target-centric) and \emph{global aggregation} (source-centric). This directional, anisotropic support captures surface tangency, scale, and occlusion-aware asymmetry while preserving the efficiency of triplane representations. On SemanticKITTI~\cite{behley2019semantickitti}, GaussianSSC improves Stage~1 occupancy by +1.0\% Recall, +2.0\% Precision, and +1.8\% IoU over state-of-the-art baselines, and improves Stage~2 semantic prediction by +1.8\% IoU and +0.8\% mIoU.
Let It Flow: Agentic Crafting on Rock and Roll, Building the ROME Model within an Open Agentic Learning Ecosystem
Dec 31, 2025Agentic crafting requires LLMs to operate in real-world environments over multiple turns by taking actions, observing outcomes, and iteratively refining artifacts. Despite its importance, the open-source community lacks a principled, end-to-end ecosystem to streamline agent development. We introduce the Agentic Learning Ecosystem (ALE), a foundational infrastructure that optimizes the production pipeline for agent LLMs. ALE consists of three components: ROLL, a post-training framework for weight optimization; ROCK, a sandbox environment manager for trajectory generation; and iFlow CLI, an agent framework for efficient context engineering. We release ROME (ROME is Obviously an Agentic Model), an open-source agent grounded by ALE and trained on over one million trajectories. Our approach includes data composition protocols for synthesizing complex behaviors and a novel policy optimization algorithm, Interaction-based Policy Alignment (IPA), which assigns credit over semantic interaction chunks rather than individual tokens to improve long-horizon training stability. Empirically, we evaluate ROME within a structured setting and introduce Terminal Bench Pro, a benchmark with improved scale and contamination control. ROME demonstrates strong performance across benchmarks like SWE-bench Verified and Terminal Bench, proving the effectiveness of the ALE infrastructure.
Clustering-based Transfer Learning for Dynamic Multimodal MultiObjective Evolutionary Algorithm
Dec 22, 2025Dynamic multimodal multiobjective optimization presents the dual challenge of simultaneously tracking multiple equivalent pareto optimal sets and maintaining population diversity in time-varying environments. However, existing dynamic multiobjective evolutionary algorithms often neglect solution modality, whereas static multimodal multiobjective evolutionary algorithms lack adaptability to dynamic changes. To address above challenge, this paper makes two primary contributions. First, we introduce a new benchmark suite of dynamic multimodal multiobjective test functions constructed by fusing the properties of both dynamic and multimodal optimization to establish a rigorous evaluation platform. Second, we propose a novel algorithm centered on a Clustering-based Autoencoder prediction dynamic response mechanism, which utilizes an autoencoder model to process matched clusters to generate a highly diverse initial population. Furthermore, to balance the algorithm's convergence and diversity, we integrate an adaptive niching strategy into the static optimizer. Empirical analysis on 12 instances of dynamic multimodal multiobjective test functions reveals that, compared with several state-of-the-art dynamic multiobjective evolutionary algorithms and multimodal multiobjective evolutionary algorithms, our algorithm not only preserves population diversity more effectively in the decision space but also achieves superior convergence in the objective space.
DR. Nav: Semantic-Geometric Representations for Proactive Dead-End Recovery and Navigation
Nov 16, 2025We present DR. Nav (Dead-End Recovery-aware Navigation), a novel approach to autonomous navigation in scenarios where dead-end detection and recovery are critical, particularly in unstructured environments where robots must handle corners, vegetation occlusions, and blocked junctions. DR. Nav introduces a proactive strategy for navigation in unmapped environments without prior assumptions. Our method unifies dead-end prediction and recovery by generating a single, continuous, real-time semantic cost map. Specifically, DR. Nav leverages cross-modal RGB-LiDAR fusion with attention-based filtering to estimate per-cell dead-end likelihoods and recovery points, which are continuously updated through Bayesian inference to enhance robustness. Unlike prior mapping methods that only encode traversability, DR. Nav explicitly incorporates recovery-aware risk into the navigation cost map, enabling robots to anticipate unsafe regions and plan safer alternative trajectories. We evaluate DR. Nav across multiple dense indoor and outdoor scenarios and demonstrate an increase of 83.33% in accuracy in detection, a 52.4% reduction in time-to-goal (path efficiency), compared to state-of-the-art planners such as DWA, MPPI, and Nav2 DWB. Furthermore, the dead-end classifier functions
Squeeze the Soaked Sponge: Efficient Off-policy Reinforcement Finetuning for Large Language Model
Jul 09, 2025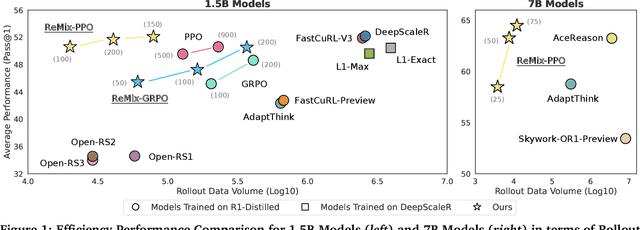
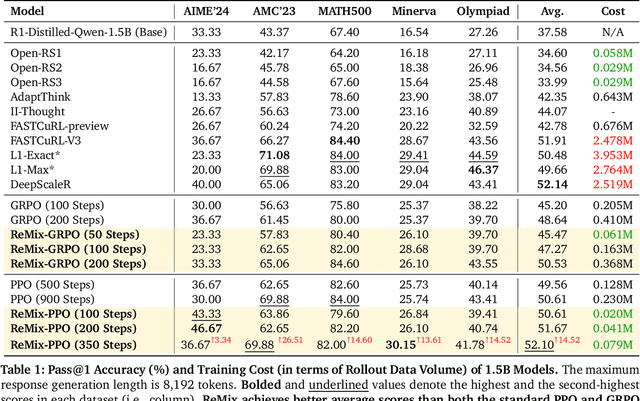
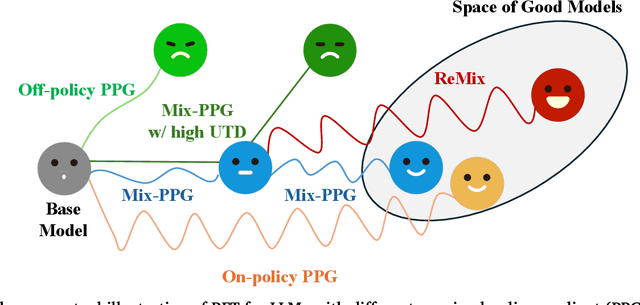

Reinforcement Learning (RL) has demonstrated its potential to improve the reasoning ability of Large Language Models (LLMs). One major limitation of most existing Reinforcement Finetuning (RFT) methods is that they are on-policy RL in nature, i.e., data generated during the past learning process is not fully utilized. This inevitably comes at a significant cost of compute and time, posing a stringent bottleneck on continuing economic and efficient scaling. To this end, we launch the renaissance of off-policy RL and propose Reincarnating Mix-policy Proximal Policy Gradient (ReMix), a general approach to enable on-policy RFT methods like PPO and GRPO to leverage off-policy data. ReMix consists of three major components: (1) Mix-policy proximal policy gradient with an increased Update-To-Data (UTD) ratio for efficient training; (2) KL-Convex policy constraint to balance the trade-off between stability and flexibility; (3) Policy reincarnation to achieve a seamless transition from efficient early-stage learning to steady asymptotic improvement. In our experiments, we train a series of ReMix models upon PPO, GRPO and 1.5B, 7B base models. ReMix shows an average Pass@1 accuracy of 52.10% (for 1.5B model) with 0.079M response rollouts, 350 training steps and achieves 63.27%/64.39% (for 7B model) with 0.007M/0.011M response rollouts, 50/75 training steps, on five math reasoning benchmarks (i.e., AIME'24, AMC'23, Minerva, OlympiadBench, and MATH500). Compared with 15 recent advanced models, ReMix shows SOTA-level performance with an over 30x to 450x reduction in training cost in terms of rollout data volume. In addition, we reveal insightful findings via multifaceted analysis, including the implicit preference for shorter responses due to the Whipping Effect of off-policy discrepancy, the collapse mode of self-reflection behavior under the presence of severe off-policyness, etc.
LLM Agents for Education: Advances and Applications
Mar 14, 2025Large Language Model (LLM) agents have demonstrated remarkable capabilities in automating tasks and driving innovation across diverse educational applications. In this survey, we provide a systematic review of state-of-the-art research on LLM agents in education, categorizing them into two broad classes: (1) \emph{Pedagogical Agents}, which focus on automating complex pedagogical tasks to support both teachers and students; and (2) \emph{Domain-Specific Educational Agents}, which are tailored for specialized fields such as science education, language learning, and professional development. We comprehensively examine the technological advancements underlying these LLM agents, including key datasets, benchmarks, and algorithmic frameworks that drive their effectiveness. Furthermore, we discuss critical challenges such as privacy, bias and fairness concerns, hallucination mitigation, and integration with existing educational ecosystems. This survey aims to provide a comprehensive technological overview of LLM agents for education, fostering further research and collaboration to enhance their impact for the greater good of learners and educators alike.
Vi-LAD: Vision-Language Attention Distillation for Socially-Aware Robot Navigation in Dynamic Environments
Mar 12, 2025We introduce Vision-Language Attention Distillation (Vi-LAD), a novel approach for distilling socially compliant navigation knowledge from a large Vision-Language Model (VLM) into a lightweight transformer model for real-time robotic navigation. Unlike traditional methods that rely on expert demonstrations or human-annotated datasets, Vi-LAD performs knowledge distillation and fine-tuning at the intermediate layer representation level (i.e., attention maps) by leveraging the backbone of a pre-trained vision-action model. These attention maps highlight key navigational regions in a given scene, which serve as implicit guidance for socially aware motion planning. Vi-LAD fine-tunes a transformer-based model using intermediate attention maps extracted from the pre-trained vision-action model, combined with attention-like semantic maps constructed from a large VLM. To achieve this, we introduce a novel attention-level distillation loss that fuses knowledge from both sources, generating augmented attention maps with enhanced social awareness. These refined attention maps are then utilized as a traversability costmap within a socially aware model predictive controller (MPC) for navigation. We validate our approach through real-world experiments on a Husky wheeled robot, demonstrating significant improvements over state-of-the-art (SOTA) navigation methods. Our results show up to 14.2% - 50% improvement in success rate, which highlights the effectiveness of Vi-LAD in enabling socially compliant and efficient robot navigation.
AutoSpatial: Visual-Language Reasoning for Social Robot Navigation through Efficient Spatial Reasoning Learning
Mar 10, 2025We present a novel method, AutoSpatial, an efficient approach with structured spatial grounding to enhance VLMs' spatial reasoning. By combining minimal manual supervision with large-scale Visual Question-Answering (VQA) pairs auto-labeling, our approach tackles the challenge of VLMs' limited spatial understanding in social navigation tasks. By applying a hierarchical two-round VQA strategy during training, AutoSpatial achieves both global and detailed understanding of scenarios, demonstrating more accurate spatial perception, movement prediction, Chain of Thought (CoT) reasoning, final action, and explanation compared to other SOTA approaches. These five components are essential for comprehensive social navigation reasoning. Our approach was evaluated using both expert systems (GPT-4o, Gemini 2.0 Flash, and Claude 3.5 Sonnet) that provided cross-validation scores and human evaluators who assigned relative rankings to compare model performances across four key aspects. Augmented by the enhanced spatial reasoning capabilities, AutoSpatial demonstrates substantial improvements by averaged cross-validation score from expert systems in: perception & prediction (up to 10.71%), reasoning (up to 16.26%), action (up to 20.50%), and explanation (up to 18.73%) compared to baseline models trained only on manually annotated data.